Python模块
1.logging模块
说明:
- 主要进行负责对系统进行日志记录的模块。
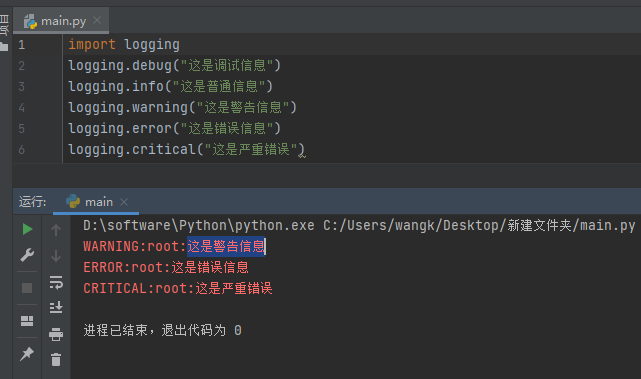
import logging # 导入 # 最简单用法 logging.debug("这是调试信息") logging.info("这是普通信息") logging.warning("这是警告信息") logging.error("这是错误信息") logging.critical("这是严重错误")日志等级:
- 默认只显示包含
WARNING以上的信息。
等级 含义 数值 DEBUG调试信息,最详细的日志,用于问题定位。 10 INFO一般运行信息,比如程序启动、关闭、某个步骤完成。 20 WARNING警告信息,程序还能继续运行,但可能会有潜在问题。 30 ERROR错误信息,某个功能出错了,但程序还没完全崩溃。 40 CRITICAL严重错误,可能导致程序无法继续运行。 50
日志输出格式字段含义:
字段字符 含义 %(name)s显示日志记录器的名字 %(levelname)s显示日志的级别 'DEBUG','INFO','WARNING','ERROR','CRITICAL'%(asctime)s创建日志记录时,显示可读时间。默认情况下,格式为 2003-07-08 16:49:45896(逗号后的数字是时间的毫秒部分)。%(message)s显示日志的具体的信息。 %(pathname)s显示日志输出时调用日志对象所在文件全路径。 %(filename)s显示日志输出时调用日志对象所在文件名。 %(funcName)s显示日志输出时调用日志对象具体的函数名。 %(module)s调用日志输出函数的模块名. %(lineno)d记录在调用日志对象时所在的代码行号。 %(thread)d显示调用线程的PID。 %(threadName)d显示调用线程的名字。 %(process)d显示调用进程的PID。 %(processName)s显示调用进程的名字。
1-1.简单使用
import logging
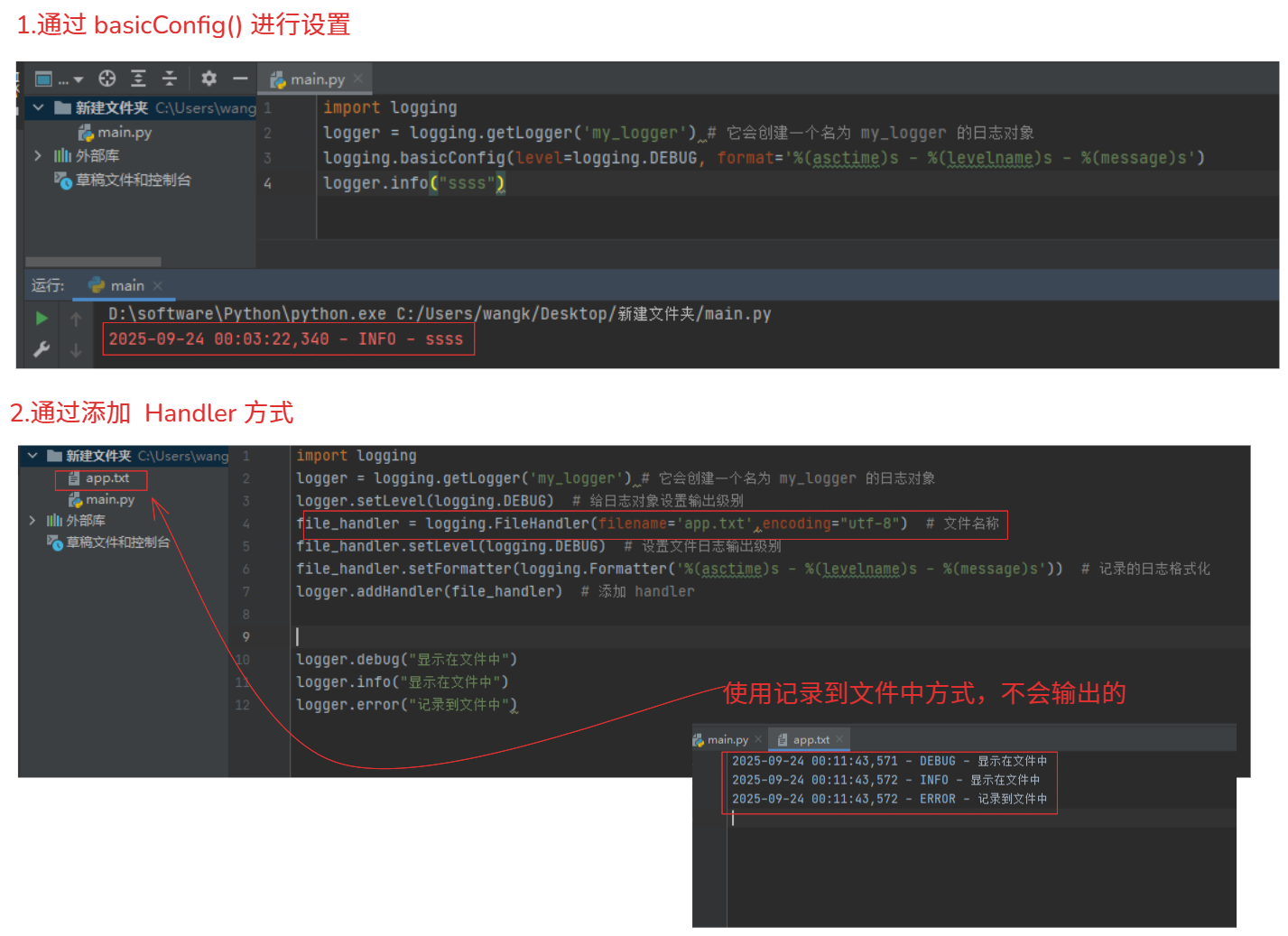
1.如果希望显示全部的日志级别 # 通过 logging.basicConfig 进行配置日志级别显示
logging.basicConfig(level=logging.DEBUG)
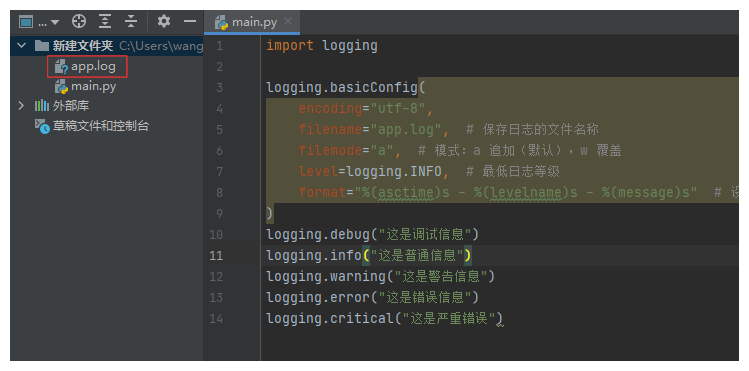
2.将日志写入到文件中
logging.basicConfig(
filename="app.log", # 保存日志的文件名称,可以增加路径,它是以当前logging对象所在文件
filemode="a", # 模式:a 追加(默认),w 覆盖
encoding="utf-8", # 设置记录到文件中的文字编码
level=logging.INFO, # 最低日志等级
format="%(asctime)s - %(levelname)s - %(message)s" # 设置记录到文件的日志格式
)
# filename 它会在当前所在执行文件的目录下创建一个 app.log 的文件进行记录
1.如果 指定的文件路径是相对路径,例如 filename="app.log",日志文件会保存在 当前工作目录 中。
2.如果 指定的是绝对路径,如 filename="/path/to/app.log",则日志文件会保存在该绝对路径指定的地方。
1-2.Logger日志对象说明
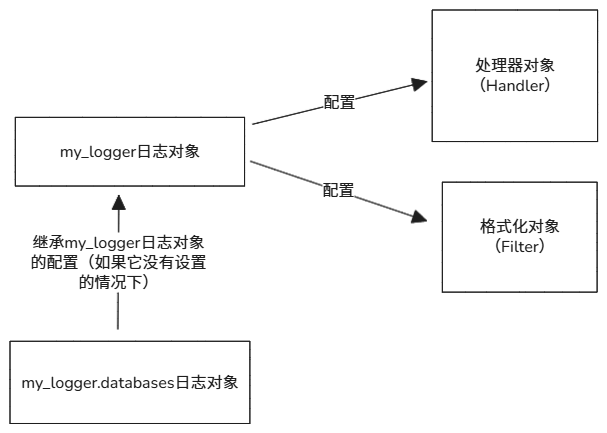
注意:日志对象的层级问题
Logger对象是有层次结构的,支持命名空间机制。它可以通过名字来区分不同的Logger,并且具有父子关系。子
Logger会继承父Logger的配置和行为。你可以通过点分法命名多个层次的
Logger,例如:
logger = logging.getLogger('myapp.database')logger = logging.getLogger('myapp.api')这意味着你可以有一个顶层的
Logger(如myapp),然后为不同的模块(如database和api)创建子Logger,这样可以分别配置不同模块的日志输出。import logging logger = logging.getLogger('my_logger') # 它会创建一个名为 my_logger 的日志对象 logger.setLevel(logging.DEBUG) # 给日志对象设置输出级别 logger_database = logging.getLogger('my_logger.database') # 它会创建一个名为 my_logger.database 的日志对象 # 如果没有 my_logger.database 对象没有设置就会继承 my_logger的设置的级别。注意:
"my_logger.database" 它是 "my_logger" 对象 的 子对象,他会继承 "my_logger" 对象 的配置和行为(配置了setLevel,或者handler,或者Filter)。
注意:级别问题
- 在创建日志对象时,需要确定好输出的级别(默认是:
WARNING)。- 你可以设置每个
Logger的日志级别。比如,设置某个Logger的级别为WARNING,那么它只会输出WARNING级别及以上的日志。import logging logger = logging.getLogger('my_logger') # 它会创建一个名为 my_logger 的日志对象 logger.setLevel(logging.DEBUG) # 只输出 DEBUG 及以上的日志 logger.setLevel(logging.WARNING) # 默认:只输出 WARNING 及以上的日志
import logging
logger = logging.getLogger('my_logger') # 它会创建一个名为 my_logger 的日志对象
logger.setLevel(logging.DEBUG) # 给日志对象设置输出级别
# 提供记录不同级别的日志:
1.logger.debug(msg):记录调试级别的日志。
2.logger.info(msg):记录普通信息。
3.logger.warning(msg):记录警告信息。
4.logger.error(msg):记录错误信息。
5.logger.critical(msg):记录严重错误信息。
1-3.Handler处理器对象
说明:
- 负责接收 Logger 日志对象传递的日志,并决定日志输出到哪里。不同的处理器作用不同。
- 注意: Handler也会设置日志的级别,如果Logger的级别是DEBUG,而Handler级别设置的INFO,那么DEBUG不会被打印输出(被Handler过滤掉),只有 ≥ Handler.level 的日志才会真正被输出。。
存储方式:
类型 作用 StreamHandler输出到控制台。 FileHandler写入文件。 RotatingFileHandler日志文件过大时自动切割。 TimedRotatingFileHandler按照时间切割日志文件。 SocketHandler把日志发到远程日志服务器。 SMTPHandler专门用来把日志通过邮件发送出去。
1-3-1.StreamHandler处理器使用
# 作用:
将日志打印到控制台中
# 使用场景:
1.把日志直接打到控制台,方便实时查看。
2.和 FileHandler 结合:开发时看控制台,线上运行时也写入文件。
3.定向输出:比如一些正常日志走 stdout,错误日志走 stderr,方便和 Linux 的日志系统或管道集成。
可以通过:
info_handler = logging.StreamHandler(sys.stdout) # 输出正常信息
error_handler = logging.StreamHandler(sys.stderr) # 输出错误信息
示例:
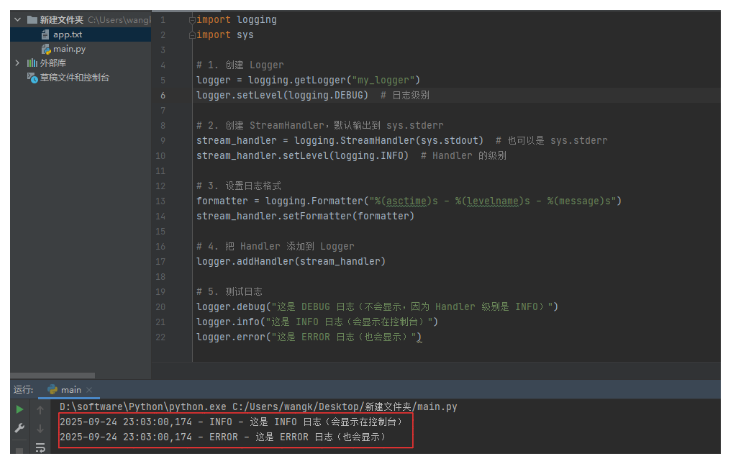
import logging
import sys
# 1. 创建 Logger
logger = logging.getLogger("my_logger")
logger.setLevel(logging.DEBUG) # 日志级别
# 2. 创建 StreamHandler,默认输出到 sys.stderr
stream_handler = logging.StreamHandler(sys.stdout) # 也可以是 sys.stderr,进行调整
stream_handler.setLevel(logging.INFO) # Handler 的级别
# 3. 设置日志格式
formatter = logging.Formatter("%(asctime)s - %(levelname)s - %(message)s")
stream_handler.setFormatter(formatter)
# 4. 把 Handler 添加到 Logger
logger.addHandler(stream_handler)
# 5. 测试日志
logger.debug("这是 DEBUG 日志(不会显示,因为 Handler 级别是 INFO)")
logger.info("这是 INFO 日志(会显示在控制台)")
logger.error("这是 ERROR 日志(也会显示)")
1-3-2.FileHandler处理器使用
# 作用:
将日志信息,写入到文件中。它不会对文件进行切割或者按照时间区分。
# 参数:
logging.FileHandler(
filename, # 日志文件名称
mode="a", # 写入模式,默认是a模式
encoding=None, # 写入文件的字符编码
delay=False, # 是否延迟打开日志文件,True是延迟打开文件写入日志(第一次写入日志时才会打开)避免不必要的文件句柄和空文件。
errors=None # 控制写文件时,编码/IO 出现错误的处理方式。当日志中可能包含非法编码字符(比如写入 utf-8 文件但日志里有 GBK 字符)。
)
errors的值:
"strict" 遇到错误时抛出异常(默认行为)。
"ignore" 忽略错误,继续写入。
"replace" 出错的字符替换为 ?。
"backslashreplace" 出错字符转为 \xNN 转义形式。
"namereplace" 出错字符转为 \N{...} Unicode 名称形式。
示例:
import logging
# 1. 创建 Logger
logger = logging.getLogger("file_logger")
logger.setLevel(logging.DEBUG) # Logger 层级
# 2. 创建 FileHandler(指定日志文件)
file_handler = logging.FileHandler("app.log", encoding="utf-8")
file_handler.setLevel(logging.INFO) # 只记录 INFO 及以上日志
# 3. 设置日志格式
formatter = logging.Formatter("%(asctime)s - %(levelname)s - %(message)s")
file_handler.setFormatter(formatter)
# 4. 将 handler 添加到 logger
logger.addHandler(file_handler)
# 5. 测试
logger.debug("这是 DEBUG,不会写入文件")
logger.info("这是 INFO,会写入文件")
logger.error("这是 ERROR,也会写入文件")

1-3-3.RotatingFileHandler处理器使用
# 作用:
它可以按文件大小自动切割日志
# 参数:它的参数与FileHandler参数相同,不过多了一个文件最大字节数和保留旧日志数量
handler = RotatingFileHandler(
filename,
mode='a',
maxBytes=0, # 日志文件最大字节数(单位:字节)
backupCount=0, # 保留旧日志数量
encoding=None,
delay=False,
errors=None
)
示例:
import logging
from logging.handlers import RotatingFileHandler
# 1. 创建 logger
logger = logging.getLogger("rotating_logger")
logger.setLevel(logging.DEBUG)
# 2. 创建 RotatingFileHandler
handler = RotatingFileHandler(
filename="app.log", # 日志文件名
maxBytes=1024, # 单个日志文件最大字节数(1 KB 仅做演示)
backupCount=3, # 保留的旧日志文件个数
encoding="utf-8"
)
# 3. 设置格式
formatter = logging.Formatter("%(asctime)s - %(levelname)s - %(message)s")
handler.setFormatter(formatter)
# 4. 添加到 logger
logger.addHandler(handler)
# 5. 测试写入日志
for i in range(100):
logger.info(f"这是第 {i} 条日志")

1-3-4.TimedRotatingFileHandler处理器使用
# 作用:
按照日期进行切割文件
# 参数:它的参数与FileHandler参数相同,多了一些关于时间切割的配置
TimedRotatingFileHandler(
filename,
when='h', # 时间切割的规则,默认是h
interval=1, # 切割的间隔数量,需要与when配合是使用,默认是1
backupCount=0, # 旧日志保留数量
encoding=None,
delay=False,
utc=False, # 切割时,按照本地时间还是UTC时间,默认False(使用本地时间)
atTime=None, # 指定一个精确时间点来切割日志。必须是 datetime.time 对象。(需要配合 when="D" 或 when="midnight" 使用)只能使用天相关的参数
errors=None
)
# when参数:不限制大小写
"S" 秒(Seconds)
"M" 分钟(Minutes)
"H" 小时(Hours)
"D" 天(Days)
"W0" - "W6" 每周(0=周一,6=周日)
"midnight" 每天午夜(00:00)切割
# interval参数:
when="H", interval=1 # 每小时切割一次
when="midnight", interval=1 # 每天切割一次
when="D", interval=3 # 每 3 天切割一次
# atTime参数:
import datetime
# 每天上午 9:30 切割日志
handler = TimedRotatingFileHandler(
filename="app.log",
when="D", # 按天
interval=1, # 每天
backupCount=7,
atTime=datetime.time(9, 30, 0), # 指定 09:30 切割
encoding="utf-8"
)
示例:
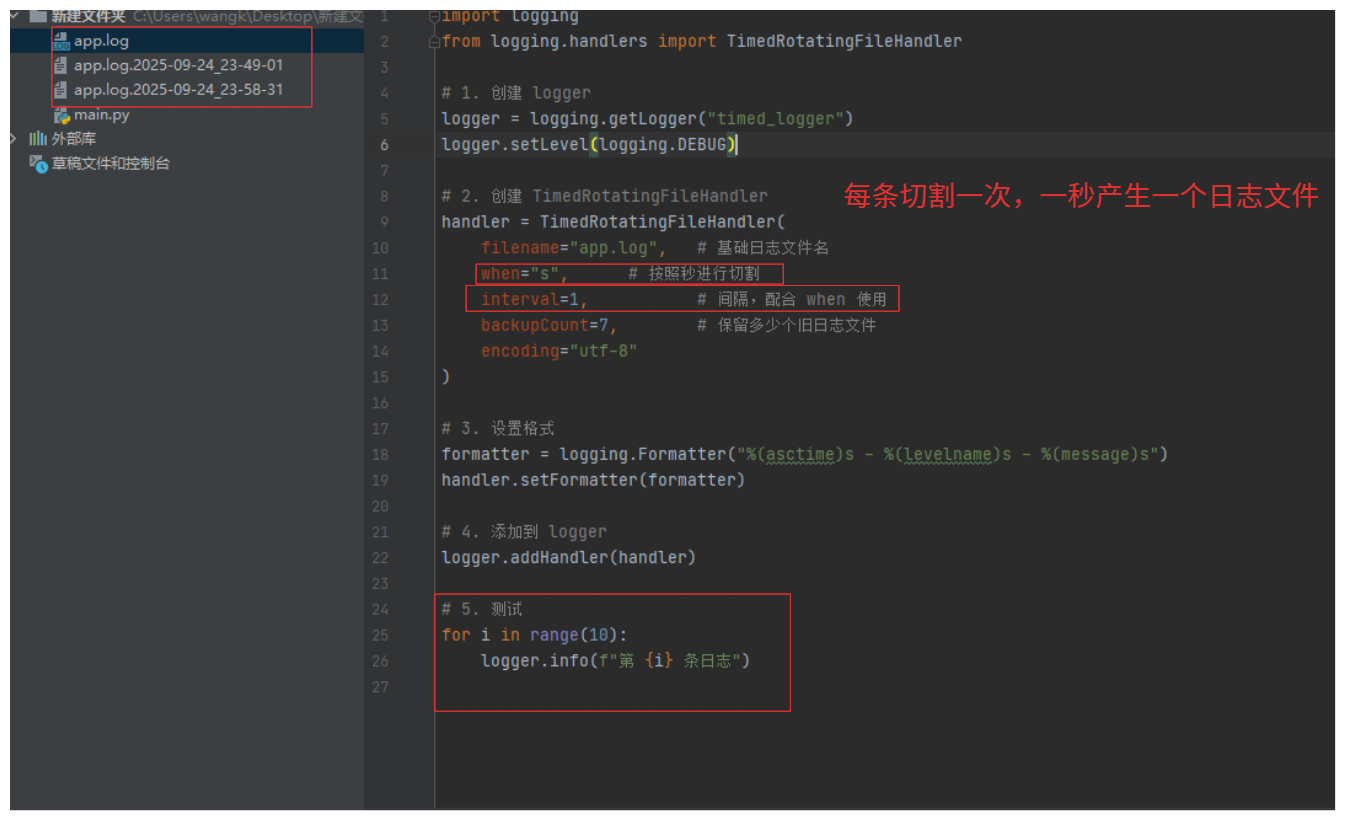
import logging
from logging.handlers import TimedRotatingFileHandler
# 1. 创建 logger
logger = logging.getLogger("timed_logger")
logger.setLevel(logging.DEBUG)
# 2. 创建 TimedRotatingFileHandler
handler = TimedRotatingFileHandler(
filename="app.log", # 基础日志文件名
when="midnight", # 切割时间点(每天午夜切割)
interval=1, # 间隔,配合 when 使用
backupCount=7, # 保留多少个旧日志文件
encoding="utf-8"
)
# 3. 设置格式
formatter = logging.Formatter("%(asctime)s - %(levelname)s - %(message)s")
handler.setFormatter(formatter)
# 4. 添加到 logger
logger.addHandler(handler)
# 5. 测试
for i in range(100):
logger.info(f"第 {i} 条日志")
1-3-5.SocketHandler处理器使用
# 作用:
把日志发到远程日志服务器
# 场景:真实使用情况下,不会这样使用,一般采用elk方式采集日志,直接将日志发送到elk的api接口或者其他的方式
1.集中日志收集:将日志统一发送到一台服务器上进行日志收集处理。
2.实时监控:日志集中发送到监控服务(比如 ELK / Graylog),实时分析。
3.分布式系统:各个子服务不单独写日志,而是统一发到中央日志处理器。
# 参数:
logging.handlers.SocketHandler(
host, # 日志服务器 IP
port # 日志服务器端口
)
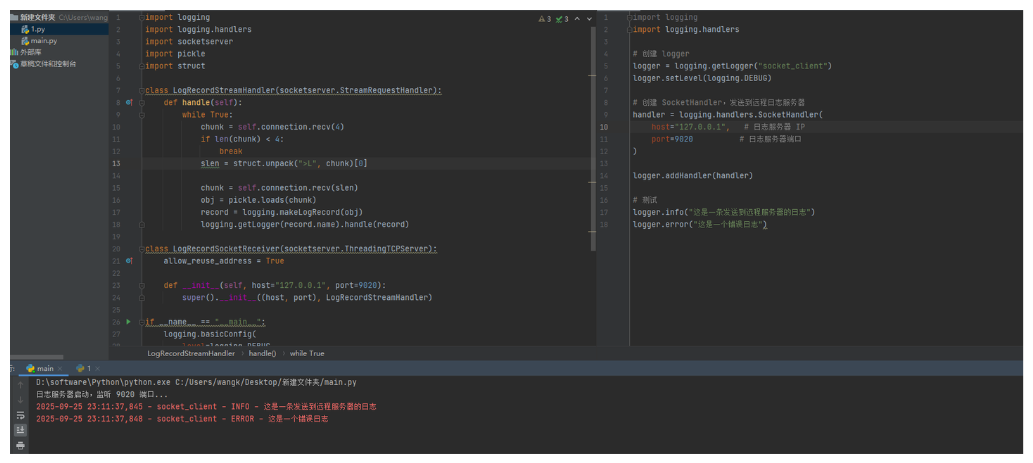
示例:客户端
import logging
import logging.handlers
# 创建 logger
logger = logging.getLogger("socket_client")
logger.setLevel(logging.DEBUG)
# 创建 SocketHandler,发送到远程日志服务器
handler = logging.handlers.SocketHandler(
host="127.0.0.1", # 日志服务器 IP
port=9020 # 日志服务器端口
)
logger.addHandler(handler)
# 测试
logger.info("这是一条发送到远程服务器的日志")
logger.error("这是一个错误日志")
示例:服务端
import logging
import logging.handlers
import socketserver
import pickle
import struct
class LogRecordStreamHandler(socketserver.StreamRequestHandler):
def handle(self): # 当接收到信息是就会自动的触发这个类中的handle函数
while True:
chunk = self.connection.recv(4) # 先读取日志的长度,4个字节就是日志信息的长度。
if len(chunk) < 4:
break
slen = struct.unpack(">L", chunk)[0] # (555,) 数据是一个元祖 555 就是日志信息的字节长度
chunk = self.connection.recv(slen) # 读取 555字节长度 日志的信息
obj = pickle.loads(chunk) # 解析序列化
record = logging.makeLogRecord(obj) # 将一个套接字连接(以字典形式发送)转换为日志记录
logging.getLogger(record.name).handle(record) # 创建日志对象,调用handle将反序列化记录,作为以及本地创建的日志。应用了日志级别过滤。
class (socketserver.ThreadingTCPServer):
allow_reuse_address = True
def __init__(self, host="127.0.0.1", port=9020):
super().__init__((host, port), LogRecordStreamHandler)
if __name__ == "__main__":
logging.basicConfig(
level=logging.DEBUG,
format="%(asctime)s - %(name)s - %(levelname)s - %(message)s"
)
tcpserver = LogRecordSocketReceiver()
print("日志服务器启动,监听 9020 端口...")
tcpserver.serve_forever()
1-3-6.SMTPHandler处理器使用
# 作用:
专门用来把日志通过邮件发送出去。
# 参数:
logging.handlers.SMTPHandler(
mailhost, # 邮件服务器地址,('服务器地址', 端口)
fromaddr, # 发件人地址
toaddrs, # 收件人地址(列表)[ A@email.com, B@email.com ]
subject, # 邮件标题
credentials=None, # (用户名, 密码)
secure=None, # 用于 TLS,加密参数
timeout=5.0 # 超时时间
)
# secure参数
secure=None # 不用加密
secure=() # 不传证书,用默认 TLS(最常见)
secure=(keyfile, certfile) # 用指定证书
secure=(None, None, ssl_context) # 用自定义 SSLContext
示例:
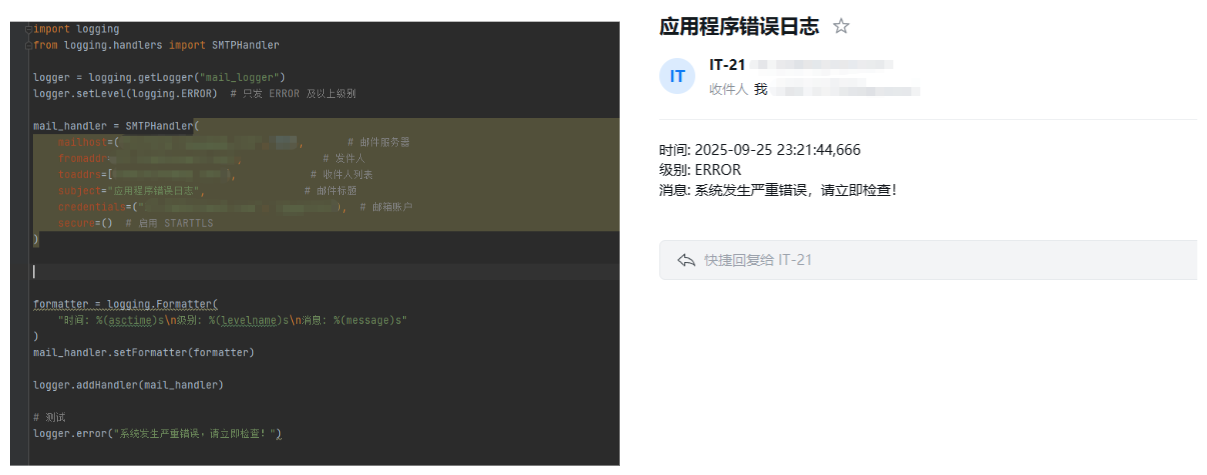
import logging
from logging.handlers import SMTPHandler
logger = logging.getLogger("mail_logger")
logger.setLevel(logging.ERROR) # 只发 ERROR 及以上级别
mail_handler = SMTPHandler(
mailhost=("smtp.example.com", 587),
fromaddr="alert@example.com",
toaddrs=["admin@example.com"],
subject="应用程序错误日志",
credentials=("alert@example.com", "yourpassword"),
secure=() # 启用 STARTTLS
)
formatter = logging.Formatter(
"时间: %(asctime)s\n级别: %(levelname)s\n消息: %(message)s"
)
mail_handler.setFormatter(formatter)
logger.addHandler(mail_handler)
# 测试
logger.error("系统发生严重错误,请立即检查!")
1-4.Filter过滤器对象
作用:
- 负责 是否允许日志通过(筛选日志)。是对日志进行更为细粒度的处理,在项目中不常用。
类型:
类型 说明 内置类型 使用内置类进行处理过滤。 自定义类型 继承内置类然后进行重写进行自定义。
1-4-1.内置类型
- 注意:
具体挂载到那个位置,需要根据需求而定,大部分都挂载到Handler上。
挂载位置 作用范围 触发时机 Logger Logger 及子 Logger 日志生成时,最先执行(全局,声明的Logger都会生效。) Handler 该 Handler 日志流到 Handler 时执行(局部,使用Handler的日志对象才会生效) 流程示意图:
Logger.log() 生成日志记录 │ ▼ Logger 上的挂载 Filter(s) │ True ────────────────┐ │ ▼ │ Handler 1 的挂载 Filter(s) │ │ True ──> 输出日志 │ │ False ─> 不输出 │ ▼ │ Handler 2 的挂载 Filter(s) │ │ True ──> 输出日志 │ │ False ─> 不输出 ▼ Logger 上的 Filter(s) 返回 False ──> 日志被拦截,不进入任何 Handler
import logging
logging.Filter(name='') # 使用内置过滤器
# name参数:内置的 name 参数就是用来匹配 Logger 对象的名称
name='' # 不限制 Logger,允许所有日志通过
name='app' # 只允许 Logger 名称以 'app' 开头的日志通过
# 示例:
import logging
# 1.声明日志对象
logger1 = logging.getLogger("myapp.module1")
logger1.setLevel(logging.INFO)
logger2 = logging.getLogger("other.module2")
logger2.setLevel(logging.INFO)
"""
# 挂着到logger对象,整个logger都会生效,包含子对象
logger = logging.getLogger("myapp")
f = logging.Filter(name='myapp')
logger.addFilter(f)
"""
# 2.声明 Handler 对象
stream_handler = logging.StreamHandler()
stream_handler.setLevel(logging.INFO) # Handler 的级别
# 2-1.声明过滤器
f = logging.Filter(name='myapp')
# 2-2.Handler对象 设置日志信息的格式化
formatter = logging.Formatter("%(asctime)s - 级别: %(levelname)s - 消息: %(message)s")
stream_handler.setFormatter(formatter)
# 2-3.Handler对象挂载 Filter过滤器
stream_handler.addFilter(f) # 这种方式是挂载到 handler处理对象上进行过滤的
# 3.挂载 Handler 对象
logger1.addHandler(stream_handler)
logger2.addHandler(stream_handler)
# 测试
logger.info("系统发生严重错误,请立即检查!")
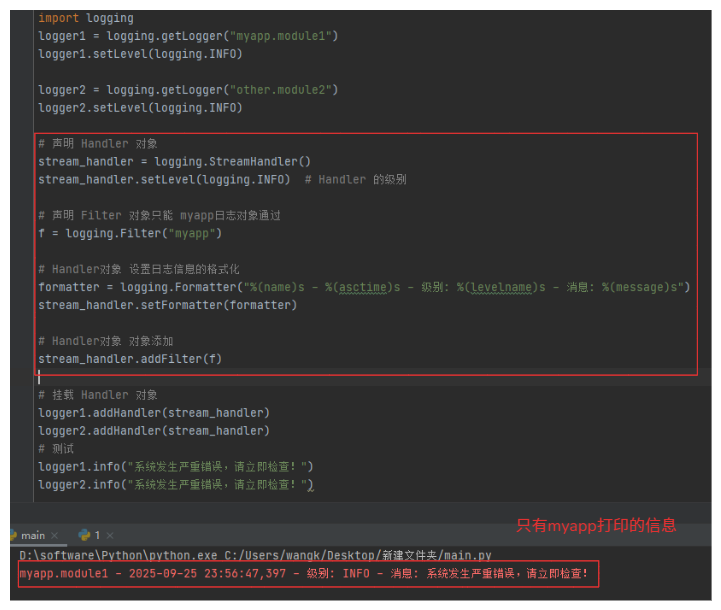
1-4-1.自定义类型
# 说明:
就是对logging.Filter的类的filter方法进行继承重写。
# 重写后的filter方法
def filter(self, record):
"""
核心就是 record 这个对象变量。
record 是 LogRecord对象,有很多的属性和方法,可以进行使用进行可控制的过滤操作,record.getMessage()就是获取消息体的
"""
# return True # 表示日志通过
return False # 表示日志拦截
# 示例:重写 filter 函数(根据 record内的自带属性进行过滤 )
import logging
class MyFilter(logging.Filter):
def filter(self, record):
return "重要" in record.getMessage() # 返回 True 表示日志允许通过,False 表示拦截
logger = logging.getLogger("my_logger")
logger.setLevel(logging.DEBUG)
f = MyFilter() # 实例化自定义类
handler = logging.StreamHandler()
handler.addFilter(f) # 添加自定义过滤器
logger.addHandler(handler)
logger.info("普通日志") # 不会输出
logger.error("这是重要错误") # 会输出
# 示例:高级写法(可以根据,环境 / 用户 / 请求 ID 过滤)
import logging
class MyFilter(logging.Filter):
def __init__(self, env):
super().__init__()
self.env = env
def filter(self, record):
print(record.env,record.username) # 打印的结果就是extra传递的字典数据
return getattr(record, "env", None) == self.env
logger = logging.getLogger("my_logger")
logger.setLevel(logging.DEBUG)
f = MyFilter('prod') # 实例化
handler = logging.StreamHandler()
handler.addFilter(f) # 添加自定义过滤器
logger.addHandler(handler)
# 这个 extra 字典会被 注入到 LogRecord 对象 里。(源码中 _log 私有方法中)重写的 filter 方法接收的 record变量就是LogRecord对象,所以可以通过 record对象获取注入的字典数据
logger.info("测试日志", extra={"env": "dev", "username": "李明"}) # 不输出
logger.info("生产日志", extra={"env": "prod", "username": "汪洋"}) # 输出
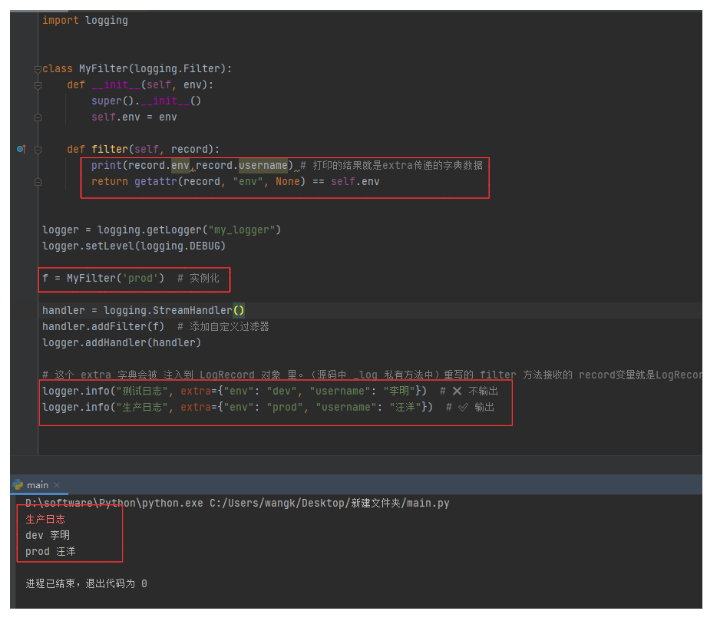
1-5.Formatter格式化器对象
作用:
- 负责日志信息的输出格式。
1-5-1.内置
# 作用:
使用内置的直接挂载到处理器对象就可以使用。(内置已经够用了)
# 参数:
logging.Formatter(
fmt=None, # 日志格式字符串
datefmt=None, # 时间格式字符串
style='%', # 格式化风格: %, {}, $
validate=True, # 是否校验 fmt 的合法性
*, # 之后的参数只能用关键字传递
defaults=None # 给 format 字符串提供默认变量
)
示例:
import logging
logger = logging.getLogger("my_logger")
logger.setLevel(logging.DEBUG)
# 定义日志输出格式
formatter = logging.Formatter(
fmt="%(asctime)s - %(name)s - %(levelname)s - %(message)s",
datefmt="%Y-%m-%d %H:%M:%S",
)
handler = logging.StreamHandler()
handler.setLevel(logging.DEBUG)
# 设置日志输出格式
handler.setFormatter(formatter)
logger.addHandler(handler)
# 输出日志信息
logger.info("6666")
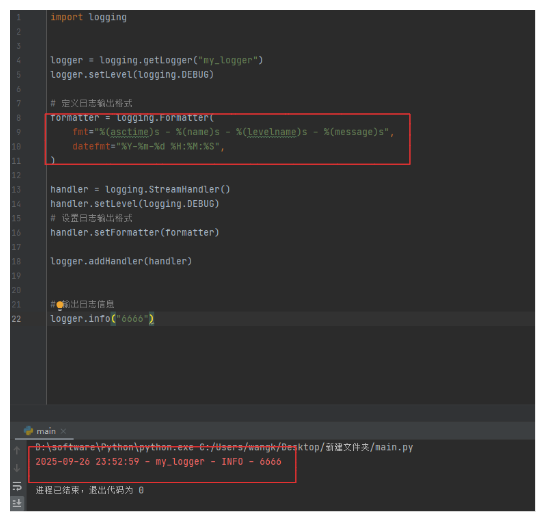
1-5-2.自定义
# 自定义json
import logging, json
# 继承 logging.Formatter 类型
class JSONFormatter(logging.Formatter):
def format(self, record): # 重写 format 方法
log_obj = {
"time": self.formatTime(record),
"level": record.levelname,
"name": record.name,
"message": record.getMessage(),
}
return json.dumps(log_obj, ensure_ascii=False)
logger = logging.getLogger("demo2")
logger.setLevel(logging.DEBUG)
handler = logging.StreamHandler()
handler.setFormatter(JSONFormatter())
logger.addHandler(handler)
logger.error("这是 JSON 格式日志")
# 彩色输出
import logging
class ColorFormatter(logging.Formatter):
COLORS = {
"DEBUG": "\033[37m", # 灰色
"INFO": "\033[36m", # 青色
"WARNING": "\033[33m", # 黄色
"ERROR": "\033[31m", # 红色
"CRITICAL": "\033[41m" # 红底
}
RESET = "\033[0m"
def format(self, record):
color = self.COLORS.get(record.levelname, "")
msg = super().format(record)
return f"{color}{msg}{self.RESET}"
logger = logging.getLogger("demo3")
logger.setLevel(logging.DEBUG)
handler = logging.StreamHandler()
handler.setFormatter(ColorFormatter("%(levelname)s - %(message)s"))
logger.addHandler(handler)
logger.info("彩色日志")
logger.error("出错啦!")
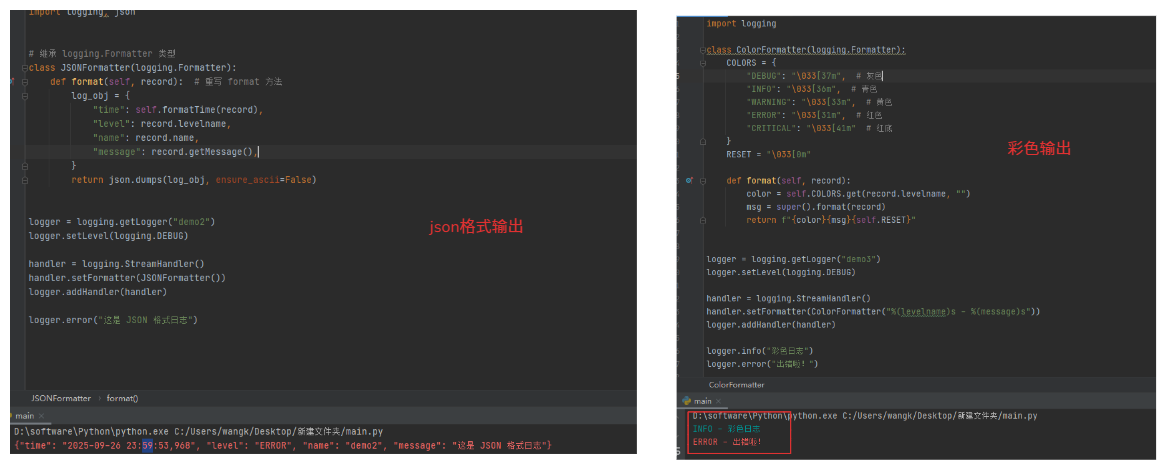
1-6.总结说明
| 组件 | 作用 | 举例/说明 |
|---|---|---|
| Logger(日志对象) | 日志的生产者,负责生成日志记录 | logger = logging.getLogger("myapp") |
| Handler(处理器) | 日志的输出通道,把日志发送到文件/控制台/邮件/网络等 | StreamHandler, FileHandler, SMTPHandler |
| Formatter(格式化器) | 决定日志输出内容的格式 | Formatter(fmt="%(asctime)s - %(levelname)s - %(message)s") |
| Filter(过滤器) | 对日志进行精细化筛选,决定日志能否通过 | 内置 Filter(name="myapp") 或自定义 Filter |
Logger.log() 生成 LogRecord
│
▼
Logger 上的挂载 Filter(s) (先行拦截)
│ True ──────────────┐
│ ▼
│ Handler 1
│ │
│ ▼
│ Handler 上的挂载 Filter(s)
│ │
│ ▼
│ Formatter.format() 日志信息格式化
│ │
│ ▼
│ 根据Handler的类型输出日志(控制台/文件/邮件/网络)
│
│
▼
Handler 2 ...
2.系统与文件操作
1.os模块
作用:
- 主要用来和操作系统进行交互。它提供了对文件、目录、进程、环境变量等操作系统功能的接口。
import os
# ========== 1. 路径操作 ==========
print(os.path.abspath(".")) # 获取当前文件的绝对路径
print(os.getcwd()) # 获取当前工作目录
os.chdir(r"C:\Users\wangk\Desktop") # 切换工作目录
print(os.path.basename("/a/b/c.txt")) # 获取路径下文件名 c.txt
print(os.path.dirname("/a/b/c.txt")) # 获取目录 /a/b
print(os.path.splitext("test.py")) # ('test', '.py') 拆分扩展名
print(os.path.join("folder", "file.txt")) # 拼接路径 folder/file.txt
print(os.path.join("folder", "file.txt")) # 拼接路径 folder/file.txt
print(os.path.exists(r"C:\Users\wangk\Desktop")) # 判断路径是否存在
print(os.path.isfile(r"C:\Users\wangk\Desktop\file.txt")) # 是否是文件
print(os.path.isdir(r"C:\Users\wangk\Desktop")) # 是否是目录
# ========== 2. 文件 & 目录操作 ==========
os.mkdir("new_folder") # 创建单个目录
os.makedirs("a/b/c", exist_ok=True) # 创建多级目录,不报错
os.rmdir("new_folder") # 删除空目录
os.remove("file.txt") # 删除文件
os.rename("old.txt", "new.txt") # 文件/目录重命名
print(os.listdir(".")) # 列出目录下所有文件/文件夹
# ========== 3. 环境变量 ==========
print(os.environ) # 获取所有环境变量
print(os.environ.get("PATH")) # 获取 PATH
os.environ["MY_VAR"] = "123" # 设置环境变量(当前进程)
# ========== 4. 系统命令 ==========
os.system("ping baidu.com") # 执行系统命令,比如 linux命令,简单但不推荐
stream = os.popen("ping baidu.com") # 执行命令 ,将结果存储然后在读取
output = stream.read()
print(output)
# ========== 5. 进程相关 ==========
print(os.getpid()) # 当前执行进程 ID
print(os.getppid()) # 当前执行进的父进程 ID
# ========== 6. 跨平台兼容 ==========
print(os.name) # 'posix' (Linux/macOS), 'nt' (Windows)
print(os.sep) # 路径分隔符 ('/' 或 '\')
print(os.linesep) # 换行符(Linux '\n', Windows '\r\n')
2.sys模块
作用:
- 它主要用来 访问解释器相关的功能。如果说
os模块是和「操作系统」打交道,那sys模块就是和「Python 解释器」打交道。
import sys
# ========== 1. 程序参数 ==========
print(sys.argv)
# 获取运行脚本时的参数列表,例如:python main.py arg1 arg2
# 输出:['main.py', 'arg1', 'arg2']
# ========== 2. 退出程序 ==========
# 退出程序,可传入状态码,0 表示成功,非0表示异常
sys.exit(0)
sys.exit(1)
# ========== 3. 标准输入/输出/错误 ==========
sys.stdout.write("标准输出\n")
sys.stderr.write("标准错误\n")
# sys.stdin.readline() 可从标准输入读取数据
# ========== 4. 解释器信息 ==========
print(sys.version) # Python 版本字符串
print(sys.version_info) # 版本号元组 (major, minor, micro, releaselevel, serial)
print(sys.platform) # 当前平台:'win32', 'linux', 'darwin'
print(sys.executable) # 当前 Python 解释器路径
# ========== 5. 模块搜索路径 ==========
print(sys.path) # 列出模块搜索路径列表
sys.path.append("/my/custom/path") # 动态添加模块搜索路径
# ========== 6. 运行时状态 ==========
print(sys.getrecursionlimit()) # 获取最大递归深度
sys.setrecursionlimit(2000) # 设置递归深度限制
print(sys.getsizeof(12345)) # 获取对象占用内存字节数
print(sys.maxsize) # 平台最大整数
print(sys.float_info) # 浮点数信息
# ========== 7. 异常处理 ==========
try:
1/0
except:
print(sys.exc_info()) # 获取当前异常信息 (type, value, traceback)
# ========== 8. 已加载模块 ==========
import math
print(sys.modules.keys()) # 当前已加载的模块名列表
print(sys.modules["math"]) # 已加载模块对象
# ========== 9. 字节序 ==========
print(sys.byteorder) # 'little' 小端, 'big' 大端
# ========== 10. 引用计数 ==========
a = []
print(sys.getrefcount(a)) # 对象 a 的引用计数
# ========== 11. 交互模式标识 ==========
# 仅在交互模式下有效
# print(sys.ps1) # '>>> '
# print(sys.ps2) # '... '
3.Path模块
作用:
- 是可以操作路径的更为现代的方法,更易用。
from pathlib import Path
# ========== 1. 创建 Path 对象 ==========
p = Path("test.txt") # 文件路径
d = Path("my_folder") # 目录路径
p_absolute = Path("/usr/bin/python") # 绝对路径
# ========== 2. 路径信息 ==========
print(p.name) # 文件名 test.txt
print(p.stem) # 文件名不含后缀 test
print(p.suffix) # 文件后缀 .txt
print(p.parent) # 父目录 Path('my_folder')
print(p.parts) # 路径各部分 ('my_folder', 'test.txt')
print(p.is_absolute()) # 是否为绝对路径 True/False
print(p.exists()) # 路径是否存在 True/False
path = Path(__file__) # 获取当前执行文件的绝对路径
parent_path = path.parent # 获取当前文件的上一级目录 可以无限向后.parent 获取上一级
# ========== 3. 路径拼接 ==========
new_path = p.parent / "new_file.txt" # 推荐方式,自动处理斜杠
print(new_path)
# ========== 4. 文件与目录操作 ==========
# 创建目录
Path("new_folder").mkdir(exist_ok=True)
# 创建多级目录
Path("a/b/c").mkdir(parents=True, exist_ok=True)
# 删除文件/目录
# p.unlink() # 删除文件
# Path("new_folder").rmdir() # 删除空目录
# ========== 5. 遍历目录 ==========
for f in Path(".").iterdir(): # 遍历当前目录下文件/文件夹
print(f)
# 递归遍历所有文件
for f in Path(".").rglob("*.py"): # 匹配所有 .py 文件
print(f)
# ========== 6. 文件读写 ==========
# 读取文件内容
text = Path("test.txt").read_text()
# 写入文件内容
Path("test.txt").write_text("Hello Pathlib!")
# ========== 7. 文件信息 ==========
print(p.stat()) # 返回文件的详细信息(大小、修改时间等)
print(p.exists()) # 是否存在
print(p.is_file()) # 是否是文件
print(p.is_dir()) # 是否是目录
# ========== 8. 文件扩展 ==========
p_new = p.with_name("new.txt") # 修改文件名
p_new = p.with_suffix(".log") # 修改后缀
4.shutil模块
作用:
- 主要是对文件和文件夹进行操作的一个模块。
功能类别 主要函数 使用场景 文件复制 shutil.copy(),shutil.copy2()拷贝文件到指定路径(含权限、时间戳) 目录复制 shutil.copytree()拷贝整个文件夹(递归) 文件/目录移动 shutil.move()移动或重命名文件夹 文件/目录删除 shutil.rmtree()递归删除文件夹(比 os.remove强)压缩与解压 shutil.make_archive(),shutil.unpack_archive()打包成 zip / tar.gz 或解压 磁盘空间信息 shutil.disk_usage()查看磁盘剩余容量 临时文件操作 shutil.which()查找可执行文件路径 文件复制权限 shutil.copymode(),shutil.copystat()单独复制权限或文件状态信息
import os
import shutil
# ========== 1. 拷贝文件 ==========
shutil.copy('123.txt','text/123.txt') # 只拷贝文件
shutil.copy2('123.txt','text/456.txt') # 拷贝文件的同时拷贝它的元数据
# ========== 2. 拷贝目录 ==========
shutil.copytree('text','./text_copy') # 只拷贝目录,命名text_copy
# ========== 3. 文件移动重命名文件夹 ==========
shutil.copytree('text_copy','text/text_copy') # 拷贝到text文件夹下命名为text_copy
# ========== 4. 删除目录 ==========
shutil.rmtree('text_copy2') # 删除
# ========== 5. 拷贝目录 ==========
print(shutil.disk_usage('D://'))
# ========== 6. 查看当前二进制的路径(在windows系统下,当前命令需要再环境变量中) ==========
print(shutil.which('cmd'))
# ========== 7. 单独复制权限或文件状态(linux直观,这两个命令就是 copy2 分来) ==========
os.chmod('a.txt', 0o700)
print(shutil.copymode('a.txt', 'b.txt')) # 将a文件的权限复制给b文件
print(oct(os.stat('a.txt').st_mode)[-3:]) # 查看权限
print(shutil.copystat('a.txt', 'b.txt')) # 将a文件的元数据复制给b文件
# ========== 8. 压缩与解压 (zip,tar,gztar,bztar 支持的格式)==========
# 压缩 make_archive(压缩文件,格式,压缩后文件名称(可路径))
shutil.make_archive("test_file", "zip", "test_file")
# 解压 unpack_archive(被解压的文件,解压后的文件名称)
shutil.unpack_archive("test_file.zip", "t")
5.glob模块
作用:
- 文件路径匹配模块,可以在文件系统中查找所有匹配某种通配符规则(如
*.py、data/**/*.csv)的文件路径。场景:
- 批量读取文件。
- 清理缓存、备份。
- 数据分析。
- 文件监控。
通配符 含义 示例 *匹配任意字符(0 个或多个) *.txt匹配所有 txt 文件?匹配单个任意字符 file?.py匹配 file1.py, fileA.py[...]匹配指定范围的任意一个字符 file[0-9].py匹配 file1.py...file9.py**表示任意多级目录(仅当 recursive=True时有效)**/*.log
import glob
# ========== 1. 匹配当前目录下的py文件 ==========
files = glob.glob("*.py")
print(files) # ['main.py']
# ========== 2. 匹配当前目录和下级子目录的文件 ==========
files = glob.glob("**/*.py", recursive=True) # recursive=True 表示开启递归匹配 , ** 代表“任意多级目录”
print(files) # ['main.py','test_file\\123.py']
# ========== 3. 匹配特定名称 ==========
print(glob.glob("log_2025-*.txt"))
# ========== 4. 结合路径匹配 ==========
print(glob.glob(f"C:\\Users\\wangk\\*.json")) # ['C:\\Users\\wangk\\package-lock.json', 'C:\\Users\\wangk\\package.json'] 返回整体文件所在路径
# 也可以使用 pathlib 模块的方法 现代替代方案
from pathlib import Path
files = list(Path("logs").rglob("*.log")) # rglob() 等价于 glob("**/*.log", recursive=True) 文件的递归查询
6.tempfile模块
作用:
- 提供了创建临时文件和临时目录的安全方式,这些文件在程序退出后可以自动删除,避免手动清理临时文件的麻烦。为了文件安全考虑,可以现将文件进行存储到临时文件夹中,通过验证后再进行存储到正式的文件中。
场景:
- 临时批量导出。
- 批量生成压缩包。
- 图片、日志批量缓存。
- 大数据任务的中间分片。
本质目的:
就是通过临时文件进行操作,当用户上传的文件先存储到临时文件中,进行文件验证(大小,内容,图片的有效性,文档类型,文件病毒扫描等等方式),如果验证通过就进行保存到正常的项目目录中(删除临时文件),如果验证不通过就返回错误信息(删除临时文件)。变相加了一层安全机制。
用户上传文件 → 临时文件(沙盒) → 验证 → 通过 → 正式目录 → 不通过 → 删除 + 错误信息
函数 作用 特点 tempfile.TemporaryFile()创建一个匿名临时文件(程序结束自动销毁) 文件无名称,只能在当前进程中使用 tempfile.NamedTemporaryFile()创建一个具名临时文件(有文件路径) 方便在多进程或外部程序中使用 tempfile.TemporaryDirectory()创建一个临时目录 程序退出时自动删除整个目录 tempfile.gettempdir()返回系统的临时文件目录路径 如:Windows 是 C:\Users\xxx\AppData\Local\Temptempfile.mkstemp()底层接口,返回文件描述符和路径 不自动删除
import os
import tempfile
# ========== 1. 查看当前系统的临时文件目录 ==========
print(tempfile.gettempdir())
# ========== 2. 创建一个具名临时文件 ==========
# delete=False 不会删除临时文件 delete=True 程序执行完毕删除临时文件
with tempfile.NamedTemporaryFile(mode='w+', suffix='.txt', delete=True) as tmp:
print(f"文件路径:{tmp.name}")
tmp.write("This is a named temporary file.\n") # 写入内容
# ========== 3. 创建一个具名临时文件 ==========
# 文件会在 with 块结束时自动删除
with tempfile.TemporaryFile(mode='w+t') as tmp:
tmp.write("Hello, TemporaryFile!") # 写入后,指针在文件末尾
tmp.seek(0) # 将指针移回开头
print(tmp.read()) # 从开头读取文件内容 输出:Hello, TemporaryFile!
# ========== 4. 创建一个临时目录 ==========
# with 结束后 临时目录和内容自动删除
with tempfile.TemporaryDirectory() as tmpdir:
print("临时目录路径:", tmpdir)
open(os.path.join(tmpdir, 'example.txt'), 'w').write('test data')
# 注意:
delete=False 生成临时文件不删除(违背了临时文件的特性),在某种状态下,需要延迟临时文件的生命周期(其他程序在使用,或者需要其他操作),最后需要手动删除。
6-1.通用处理模版
import os
import shutil
import tempfile
from pathlib import Path
def universal_file_processor(input_file, processing_callback, final_destination=None, keep_original=False):
"""
通用文件处理器
参数:
input_file: 输入文件路径或文件对象
processing_callback: 处理文件的回调函数,接收文件路径,返回处理结果
final_destination: 最终保存路径(可选)
keep_original: 是否保留原始文件(默认False)
返回:
处理结果和最终文件路径
"""
temp_path = None
original_backup_path = None
try:
# 第一步:创建临时文件
with tempfile.NamedTemporaryFile(delete=False, suffix=Path(input_file).suffix) as tmp:
temp_path = tmp.name
# 第二步:将输入文件复制到临时位置
if isinstance(input_file, str) and os.path.exists(input_file):
# 输入是文件路径
shutil.copy2(input_file, temp_path)
if keep_original:
# 备份原始文件
original_backup_path = f"{input_file}.backup"
shutil.copy2(input_file, original_backup_path)
else:
# 输入是文件对象或其他数据流
with open(temp_path, 'wb') as f:
if hasattr(input_file, 'read'):
f.write(input_file.read())
else:
f.write(input_file)
# 第三步:处理文件
print(f"正在处理文件: {temp_path}")
result = processing_callback(temp_path)
# 第四步:决定文件去向
if final_destination:
# 移动到最终位置
os.makedirs(os.path.dirname(final_destination), exist_ok=True)
shutil.move(temp_path, final_destination)
final_path = final_destination
temp_path = None # 避免重复删除
else:
# 返回临时文件路径(调用者负责清理)
final_path = temp_path
temp_path = None
return {
'success': True,
'result': result,
'final_path': final_path,
'backup_path': original_backup_path
}
except Exception as e:
# 错误处理
print(f"文件处理失败: {e}")
return {
'success': False,
'error': str(e),
'final_path': None
}
finally:
# 清理临时文件
if temp_path and os.path.exists(temp_path):
os.unlink(temp_path)
6-2.Web场景
from flask import Flask, request, jsonify
app = Flask(__name__)
def validate_and_sanitize(file_path):
"""文件验证和清理回调函数"""
# 检查文件类型
file_size = os.path.getsize(file_path)
if file_size > 10 * 1024 * 1024: # 10MB限制
raise ValueError("文件大小超过限制")
# 这里可以添加病毒扫描、内容验证等
return f"文件验证通过,大小: {file_size} bytes"
@app.route('/upload', methods=['POST'])
def upload_file():
if 'file' not in request.files:
return jsonify({'error': '没有文件'}), 400
uploaded_file = request.files['file']
# 使用通用处理器
result = universal_file_processor(
input_file=uploaded_file,
processing_callback=validate_and_sanitize,
final_destination=f"uploads/{uploaded_file.filename}"
)
if result['success']:
return jsonify({'message': '上传成功', 'path': result['final_path']})
else:
return jsonify({'error': result['error']}), 500
6-3.图片处理场景
from PIL import Image
def resize_image(image_path):
"""图片处理回调函数"""
with Image.open(image_path) as img:
# 调整大小
resized = img.resize((800, 600))
# 保存回原路径(覆盖)
resized.save(image_path, quality=85)
return f"图片已调整为 800x600,大小: {os.path.getsize(image_path)} bytes"
# 使用
result = universal_file_processor(
input_file="original.jpg",
processing_callback=resize_image,
final_destination="processed/resized.jpg"
)
print(result)
6-4.文档转换场景
import pandas as pd
def csv_to_excel(csv_path):
"""CSV转Excel回调函数"""
# 读取CSV
df = pd.read_csv(csv_path)
# 转换为Excel
excel_path = csv_path.replace('.csv', '.xlsx')
df.to_excel(excel_path, index=False)
return f"转换成功,共处理 {len(df)} 行数据"
# 使用
result = universal_file_processor(
input_file="data.csv",
processing_callback=csv_to_excel,
final_destination="converted/data.xlsx"
)
6-5.文档加密场景
from cryptography.fernet import Fernet
def encrypt_file(file_path, key):
"""文件加密回调函数"""
def _encrypt(path):
fernet = Fernet(key)
with open(path, 'rb') as f:
original_data = f.read()
encrypted_data = fernet.encrypt(original_data)
with open(path, 'wb') as f:
f.write(encrypted_data)
return "文件加密完成"
return _encrypt
# 使用
key = Fernet.generate_key()
result = universal_file_processor(
input_file="sensitive_document.pdf",
processing_callback=encrypt_file(key),
final_destination="encrypted/secure_file.pdf.enc"
)
2.格式化处理
1.json模块
说明:
- 用于 Python 对象 ↔ JSON 字符串 的互相转换。
函数 作用 例子 json.dump(obj, fp, *, indent=None)将 Python 对象写入文件(序列化, fp是 文件对象json.dump(data, f, indent=2)json.dumps(obj, *, indent=None)将 Python 对象转换为 JSON 字符串(序列化) json_str = json.dumps(data)json.load(fp)从文件读取 JSON 数据并转换为 Python 对象(反序列化) fp是 文件对象data = json.load(f)json.loads(s)将 JSON 字符串转换为 Python 对象(反序列化) data = json.loads(json_str)
import json
data = {
"name": "Alice",
"age": 25,
"skills": ["Python", "SQL", "AI"]
}
# ========== 1. 常用方式 ==========
json_str = json.dumps(data)
print(json_str, type(json_str)) # 现有类型,转换为字符串 {"name": "Alice", "age": 25, "skills": ["Python", "SQL", "AI"]} <class 'str'>
json_restore = json.loads(json_str)
print(json_restore, type(json_restore)) # 转换为原有的类型 {'name': 'Alice', 'age': 25, 'skills': ['Python', 'SQL', 'AI']} <class 'dict'>
# ========== 2. 读写文件 ==========
# 写入文件
with open("data.json", "w", encoding="utf-8") as f: # 正常模式即可
json.dump(data, f, indent=2, ensure_ascii=False)
# 从文件读取
with open("data.json", "r", encoding="utf-8") as f: # 正常模式即可
loaded_data = json.load(f)
print(loaded_data)
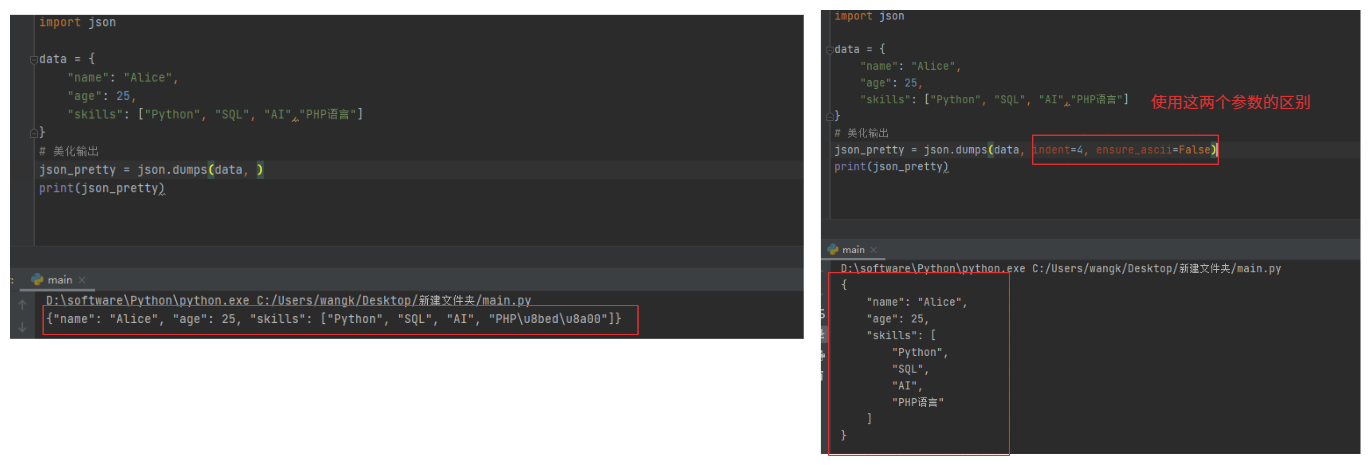
# ========== 3. 美化输出 ==========
参数说明:
indent:缩进格式
ensure_ascii=False:保证中文不会被转成 \uXXXX
json_pretty = json.dumps(data, indent=4, ensure_ascii=False)
print(json_pretty)
# ========== 4. 补充说明(标准json格式) ==========
data = {"user": "1001", "money": "999"}
print(json.dumps(data))
msg = json.dumps(data, sort_keys=True, separators=(',', ':')) # 所有的复杂结构都可以这样使用
print(msg)
"""
正常(未添加参数):{"user": "1001", "money": "999"}
标准化:{"money":"999","user":"1001"}
"""
参数解释:使用这两个参数的目的是必须保证序列化结果唯一(应用场景:加密签名,任何细微的差异都会导致签名不一致)。
sort_keys=True # 解释:按照字母进行排序
separators=(',', ':') # 解释:去掉空格
2.csv模块
作用:
- 读写以逗号或其他分隔符分隔的表格数据文件。
- 数据的导出导入,系统之间的数据交换,日志分析,报表生成,Excel 或数据库前置处理。
# 数据格式如下 id,name,age,city # 第一行元素可以理解为是数据库的字段 1,Tom,25,New York # 这些就是数据库的字段内容 2,Lily,23,London 3,张伟,30,北京
功能 对应类/方法 简介 读取 CSV 文件对象 csv.reader()读取csv文件对象,可以通过循环输出内容(迭代器)。 写入 CSV 文件对象 csv.writer()写入csv文件(写入对象) 读取字典格式 csv.DictReader()每行变成字典(迭代器对象) 写入字典格式 csv.DictWriter()按字段名写入(写入对象) 批量写入 CSV 文件 csv.writerows将整体直接写入(多行写入) 写入 CSV 文件 csv.writerow()按行写入(单行写入)
import csv
# ========== 1. 读取csv文件内容 ==========
with open('1.csv', mode='r', encoding='utf-8') as f:
reader = csv.reader(f) # 一个csv的对象
for row in reader: # 循环后每一行是一个列表,列表就是每个元素
print(row)
# ========== 2. 写入csv文件内容 ==========
rows = [
['id', 'name', 'age'],
[1, 'Tom', 25],
[2, 'Lily', 23]
]
with open('output.csv', mode='w', newline='', encoding='utf-8') as f:
writer = csv.writer(f) # 创建一个csv对象
writer.writerows(rows) # 批量写入
# ========== 3. 使用字典方式读取数据(推荐使用) ==========
with open('1.csv', mode='r', encoding='utf-8') as f:
reader = csv.DictReader(f) # 以字典形式读取
for row in reader:
print(row['id'],row['name'], row['city'],row.get("age"))
"""
1 Tom New York 25 # 第一行
2 Lily London 23 # 第二行
3 张伟 北京 30 # 第三行
"""
# ========== 4. 使用字典方式写入数据(推荐使用) ==========
data = [
{"name": "Tom", "age": 25, "city": "New York"},
{"name": "Lily", "age": 23, "city": "London"}
]
with open('people.csv', 'w', newline='', encoding='utf-8') as f:
fieldnames = ["name", "age", "city"]
writer = csv.DictWriter(f, fieldnames=fieldnames) # 字典形式写入对象
writer.writeheader() # 写入表头 表头的内容:name,age,city
writer.writerows(data) # 写入数据 就是字典对应的value
# 说明:writerows与 writerow 的区别
rows = [
['id', 'name', 'age'],
[1, 'Tom', 25],
[2, 'Lily', 23]
]
2.批量写入
with open('output.csv', mode='w', newline='', encoding='utf-8') as f:
writer = csv.writer(f)
writer.writerows(rows) # 省略循环的操作
2.单行写入
with open('output.csv', mode='w', newline='', encoding='utf-8') as f:
writer = csv.writer(f)
for i in rows:
writer.writerow(i)
3.pickle模块
是什么:
- 将数据对象转换为字节流(bytes),方便存储(可以进行序列化和反序列化),与json模块(用于接口,配置文件等等)性质相同,pickle(用于缓存,模型持久化,本地存储复杂对象)。
方法 作用 pickle.dump(obj, file)把对象写入文件(二进制) pickle.load(file)从文件中读取对象 pickle.dumps(obj)把对象转成 bytes pickle.loads(bytes)从 bytes 恢复对象 场景:
- 最佳场景是 Python 内部缓存、轻量持久化、临时保存复杂对象,不适合跨语言、海量数据或高并发场景。
- 例如:我不是用缓存的三方程序,就可以通过这个模块进行轻量级的缓存处理()。
import pickle
# ========== 1. 序列化反序列化 ==========
data = [1, 2, 3, {'a': 4}]
serialized = pickle.dumps(data) # 序列化为 bytes
print(serialized) # b'\x80\x04\x95\x14\x00\x00\x00\x00\x00\x00\x00]\x94(K\x01K\x02K\x03}\x94\x8c\x01a\x94K\x04se.'
restored = pickle.loads(serialized) # 反序列化还原
print(restored) # [1, 2, 3, {'a': 4}]
# ========== 2. 读取文件/写入文件 ==========
data = {
'name': 'Tom',
'age': 25,
'languages': ['Python', 'C++', 'Go']
}
# 序列化并保存到文件
with open('data.pkl', 'wb') as f: # 写入必须是二进制模式
pickle.dump(data, f)
# 反序列化读取文件内容
with open('data.pkl', 'rb') as f: # 读取也必须是二进制模式
data_loaded = pickle.load(f)
print(data_loaded) # {'name': 'Tom', 'age': 25, 'languages': ['Python', 'C++', 'Go']}
4.decimal模块
作用:
- 专门用来处理高精度的十进制小数,它解决了浮点数计算精度不准的问题。
使用场景:
- 财务计算,科学计算,商业系统,避免float小数累加错误(大多数常用就是四舍五入和小数精确计算)。
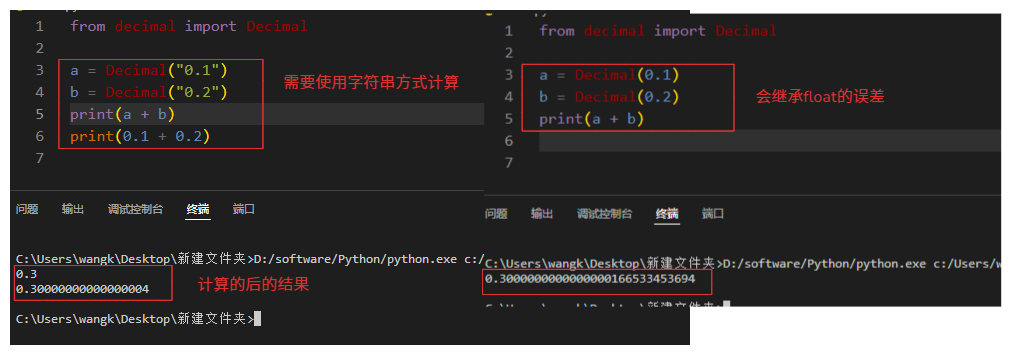
注意:初始化 Decimal 时最好用字符串,不要用 float,否则会继承 float 的误差。
常用的舍入模式:
常量 含义 应用 ROUND_HALF_UP普通四舍五入 常用 ROUND_HALF_EVEN银行家舍入 金融核算 ROUND_DOWN向 0 方向取整 截断 ROUND_UP向远离 0 方向取整 税费等
from decimal import Decimal
# ========== 1. 基础使用与对比 ==========
a = Decimal("0.1")
b = Decimal("0.2")
print(a + b) # 结果:0.3
print(0.1 + 0.2) # 结果:0.30000000000000004
# ========== 2. 四舍五入(请看上述表格) ==========
from decimal import Decimal, ROUND_HALF_UP
a = Decimal('1.2369')
b = a.quantize(Decimal('0.01'), rounding=ROUND_HALF_UP)
print(b) # 输出 1.24
# ========== 3. 格式化操作 ==========
Decimal('3.14000').normalize() # 输出:Decimal('3.14')
# ========== 3. 常用的配置 ==========
from decimal import getcontext, ROUND_HALF_UP
getcontext().prec = 28 # 设置全局有效位数,也就是数字最多有28位 整数 + 小数
getcontext().rounding = ROUND_HALF_UP # 设置全局四舍五入
2.数学随机数
1.random模块
作用:
- 它主要用来 生成随机数或随机选择,常用于模拟、测试、小游戏等场景。
import random
# ========== 1. 生成随机数 ==========
print(random.random()) # [0.0, 1.0) 之间的浮点数
print(random.uniform(1, 10)) # [1, 10] 之间的浮点数
print(random.randint(1, 10)) # [1, 10] 之间的整数,包括两端
print(random.randrange(1, 10)) # [1,10) 之间整数,不包括 10
# ========== 2. 从序列中随机选择 ==========
lst = [1, 2, 3, 4, 5]
print(random.choice(lst)) # 从列表中随机选一个
print(random.choices(lst, k=3)) # 带重复的随机选 k 个
print(random.sample(lst, 3)) # 不重复随机选 3 个
# ========== 3. 打乱顺序 ==========
lst2 = [1, 2, 3, 4, 5]
random.shuffle(lst2) # 原地打乱列表顺序
print(lst2)
2.math模块
是什么:
- 是一个数学基础库,它主要提供各种数学函数、常数、三角函数、对数函数、取整操作等。
常用的方法:
函数 作用 常见场景示例 math.ceil(x)向上取整 分页、计算页数、金额四舍五入到更高整数 math.floor(x)向下取整 截断小数、去尾取整 math.sqrt(x)平方根 计算欧几里得距离、标准差 math.pow(x, y)幂运算 (x^y) 财务利息、指数增长 math.fabs(x)绝对值 取差值、距离等场景 math.isfinite(x)判断是否为有限数(只接受数值类型( int或float)推荐使用float)数据清洗、异常检测 math.isnan(x)判断是否为 NaN(只接受数值类型( int或float)推荐使用float)防止脏数据参与运算
import math
# ========== 1.分页计算 ==========
total_items = 97 # 总数据
page_size = 10 # 分页一页10条
pages = math.ceil(total_items / page_size) # 总页码:10
# ========== 2.只取整数 ==========
print(math.floor(1.6899)) # 结果:1
# ========== 3.判断是否为 NaN(非数字,在对解析Excel/CSV 空值解析为 NaN非常好用) ==========
print(math.isnan(float('nan'))) # True
print(math.isnan(3.14)) # False
3.时间与日期
1.time
作用:
- 主要用来获取时间,时间格式化操作,适合用来测时间差、性能统计,比如启动到现在过了几秒(偏系统层)。
常用方法:
方法 说明 time.time()获取当前时间戳(秒) time.localtime([secs])时间戳 → 本地时间结构体 time.gmtime([secs])时间戳 → UTC 时间结构体 time.strftime(format[, t])时间结构体 → 格式化字符串 time.strptime(string, format)格式化字符串 → 时间结构体 time.mktime(t)时间结构体 → 时间戳 time.sleep(seconds)程序休眠 time.perf_counter()高精度计时器(性能测试) time.process_time()CPU 执行时间(不含休眠) 时间格式化符号:
格式符 说明 示例 %Y四位年份 2025%m月份(01–12) 10%d日(01–31) 16%H小时(00–23) 14%M分钟(00–59) 05%S秒(00–59) 32%a星期(简写) Thu%A星期(全称) Thursday%w星期几(0–6) 4%j一年中的第几天 289
import time
# ========== 1.获取当前时间戳 ==========
print(time.time()) # 1970 - 现在的秒数
# ========== 2.获取当前时间(时间结构体) ==========
t = time.localtime() # 结构体对象
print(t) # struct_time对象
# 结构体属性
print(t.tm_year, t.tm_mon, t.tm_mday,t.tm_hour,t.tm_min,t.tm_sec) # 年:2025 月:10 日:16 时:22 分:53 秒:36
# ========== 3.时间转字符串(时间结构体 → 格式化字符串) ==========
t2 = time.strftime("%Y-%m-%d %H:%M:%S") # 获取当前时间
print(t2,type(t2)) # 2025-10-16 22:53:36 <class 'str'>
# ========== 4.字符串转结构体(格式化字符串 → 时间结构体) ==========
s = "2025-10-16 14:00:00"
t = time.strptime(s, "%Y-%m-%d %H:%M:%S") # 时间结构体对象
print(t)
# ========== 5.结构体转时间戳(时间结构体 → 时间戳) ==========
t = time.localtime()
timestamp = time.mktime(t) # 通过时间结构体对象转为时间戳
print(timestamp)
# 转换(字符串 → 时间结构体 → 时间戳)
s = "2025-10-16 14:00:00"
t = time.strptime(s, "%Y-%m-%d %H:%M:%S") # 时间结构体对象
timestamp = time.mktime(t) # 通过时间结构体对象转为时间戳
print(timestamp)
# 转换(时间戳 → 时间结构体 → 字符串)
ts = time.time() # 时间戳
local_time = time.localtime(ts) # 时间结构体
print(time.strftime("%Y-%m-%d %H:%M:%S", local_time)) # 转换字符串时间 2025-10-16 14:35:00
2.datetime
作用:
- 时间处理,偏业务逻辑、时间计算、日期格式化(偏业务)。
核心类:
类名 说明 datetime.datetime日期+时间(最常用) datetime.date只有日期(年/月/日) datetime.time只有时间(时/分/秒) datetime.timedelta时间差(可加减) datetime.tzinfo时区信息(一般配合 pytz使用)格式符号:
符号 含义 示例 %Y年(四位) 2025 %m月(两位) 10 %d日(两位) 16 %H时(24小时) 15 %M分 09 %S秒 45
from datetime import datetime, date, time, timedelta
# ========== 1.获取当前时间和日期 ==========
now = datetime.now() # 当前日期时间
print(now) # 2025-10-16 14:55:01.123456
today = date.today() # 当前日期
print(today) # 2025-10-16
# ========== 2.创建时间对象 ==========
dt = datetime(2025, 10, 1, 15, 30, 0) # 指定时间
print(dt) # 2025-10-01 15:30:00
d = date(2025, 10, 1) # 只要日期
print(d) # 2025-10-01
t = time(14, 30, 0) # 只要时间
print(t) # 14:30:00
# ========== 3.时间加减法操作 ==========
now = datetime.now() # 必须是datetime对象
# 加减天数、小时、分钟等
print(now + timedelta(days=7)) # 一周后
print(now - timedelta(hours=3)) # 三小时前
print(now + timedelta(minutes=30)) # 半小时后
# ========== 4.时间对象的格式化操作(时间对象 → 字符串) ==========
now = datetime.now()
print(now.strftime("%Y-%m-%d %H:%M:%S")) # 字符串:2025-10-16 23:25:09
print(now.strftime("%Y/%m/%d")) # 字符串:2025/10/16
print(now.strftime("%H:%M")) # 字符串:23:25
# ========== 5.字符串转时间对象(字符串 → 时间对象) ==========
dt = datetime.strptime("2025-10-01 12:00:00", "%Y-%m-%d %H:%M:%S")
print(dt) # datetime.datetime(2025, 10, 1, 12, 0),转换后就可以进行时间加减操作
# ========== 6.时间戳转换 ==========
now = datetime.now()
ts = now.timestamp() # datetime对象 → 时间戳
print(ts) # 1739680123.182
dt = datetime.fromtimestamp(ts) # 时间戳 → datetime对象
print(dt) # 2024-06-17 10:28:43.182000
# ========== 7.时间对象属性提取 ==========
now = datetime.now() # datetime对象 可以进行当前操作(字符串时间转换后就可以进行操作)
print(now.year) # 年
print(now.month) # 月
print(now.day) # 日
print(now.hour) # 时
print(now.minute) # 分
print(now.second) # 秒
# ========== 8.时间比较 ==========
t1 = datetime.now()
t2 = t1 + timedelta(days=1)
print(t1 < t2) # True
print(t2 - t1) # timedelta(days=1)
3.calendar
作用:
- 与
time和datetime模块不同,它主要用来 生成日历、判断闰年、获取星期、月份信息等。实用方法:
函数 说明 calendar.isleap(year)判断是否闰年 calendar.leapdays(y1, y2)统计区间内闰年数量(不含 y2) calendar.monthrange(year, month)返回 (该月第一天星期几, 该月天数)calendar.weekday(year, month, day)返回星期几(0=周一 ... 6=周日) calendar.monthcalendar(year, month)返回按周划分的二维数组
import calendar
# ========== 1.打印某月日历,文本形式 ==========
print(calendar.month(2024, 6))
# ========== 2.打印整年日历,文本形式 ==========
print(calendar.calendar(2025))
# ========== 3.输出一个html格式的日历 ==========
html_cal = calendar.HTMLCalendar().formatmonth(2025, 10)
print(html_cal)
# ========== 4.方法汇总 ==========
print(calendar.isleap(2018)) # 判断是否是润年 False
print(calendar.leapdays(2000, 2020)) # 计算2000-2020之间的润年个数,不含2020年。 5
print(calendar.monthrange(2025, 10)) # 判断有多少天,当月第一天是星期几 (calendar.WEDNESDAY, 31)
print(calendar.weekday(2025, 10, 16)) # 2025-10-16是周几(0-6)
weeks = calendar.monthcalendar(2025, 10) # 返回按周划分的二维数组
for w in weeks:
print(w)
"""
每一行代表一周,0表示该周中不属于当月的日期,默认从周1开始
[0, 0, 1, 2, 3, 4, 5]
[6, 7, 8, 9, 10, 11, 12]
[13, 14, 15, 16, 17, 18, 19]
[20, 21, 22, 23, 24, 25, 26]
[27, 28, 29, 30, 31, 0, 0]
"""
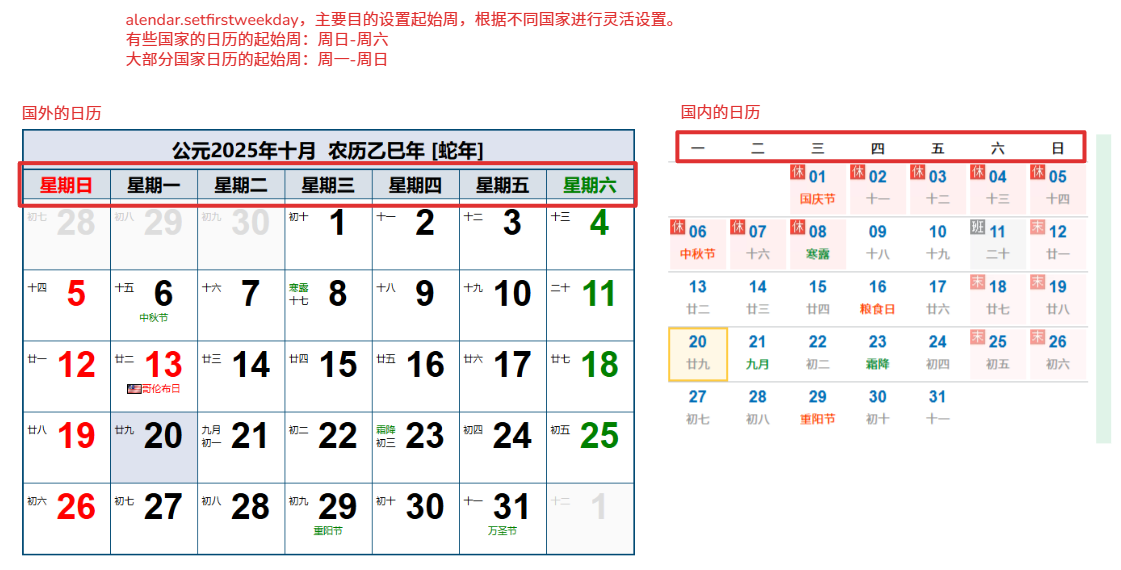
# 设置起始周的原因:一周的第一天(有些按照周日,有些按照周一,导致日历的不同),其实不是全世界统一的!
calendar.setfirstweekday(calendar.SUNDAY) # 设置起始周,默认是从周一排序到周末,设置后周日到周六。
print(calendar.month(2025, 10))
"""
默认:Mo(周一) Tu(周二) We(周三) Th(周四) Fr(周五) Sa(周六) Su(周日)
修改后:Su(周日) Mo(周一) Tu(周二) We(周三) Th(周四) Fr(周五) Sa(周六)
"""
4.加密与哈希
1.hashlib模块
作用:
- 进行各种安全哈希(摘要)计算,例如 MD5、SHA1、SHA256 等。
功能 说明 hashlib.md5()快速计算哈希(不推荐用于安全) hashlib.sha256()推荐,常用于密码、签名 .update(data)更新哈希内容(可多次) .hexdigest()获取十六进制字符串结果 .digest()获取原始 bytes 结果
import hashlib
s = "hello123"
# ========== 1. md5加密 ==========
md5 = hashlib.md5()
md5.update(s.encode('utf-8')) # 必须转为 bytes
print(md5.hexdigest()) # 输出:md5 十六进制字符串 f30aa7a662c728b7407c54ae6bfd27d1
# ========== 2. sha256加密 ==========
sha256 = hashlib.sha256()
sha256.update(s.encode('utf-8')) # 必须转为 bytes
print(sha256.hexdigest()) # 输出:md5 十六进制字符串 27cc6994fc1c01ce6659c6bddca9b69c4c6a9418065e612c69d110b3f7b11f8a
# ========== 3. 文件完整性验证 ==========
def file_sha256(path):
sha256 = hashlib.sha256()
with open(path, "rb") as f:
for chunk in iter(lambda: f.read(4096), b""):
sha256.update(chunk) # 更新哈希内容(可多次)
return sha256.hexdigest() # 最终返回哈希内容
print(file_sha256("123.txt"))
# ========== 4. 给密码加盐(防止撞库,防止密码被破解) ==========
import os
import hashlib
password = "admin123" # 密码
salt = os.urandom(16).hex() # 生成随机盐
hash_value = hashlib.sha256((password + salt).encode()).hexdigest() # 进行哈希操作
print("盐:", salt) # 6516ab15a62bc71058e970bd45b20954
print("加盐哈希:", hash_value) # ca4b320fb0624e7c9897f00df5989a91dc04bd6fca0e9b74c2f306a437dfff4f
# ========== 5. 获取原始的字节(字节要不正常的字符串快,字节是“底层数据”,少了一层编码/解码和字符抽象处理。) ==========
h = hashlib.md5()
h.update(s.encode('utf-8'))
print("hexdigest:", h.hexdigest()) # 十六进制字符串-可读 f30aa7a662c728b7407c54ae6bfd27d1
print("digest:", h.digest()) # 原始二进制 bytes-不可读 b"\xf3\n\xa7\xa6b\xc7(\xb7@|T\xaek\xfd'\xd1"
# 注意:密码加密的目的
密码加密(加盐哈希)不是为了登录时传输安全(在用户登录时明文传递密码),而是为了防止数据库泄露时密码被破解。(因为在有 HTTPS 的前提下,传输层安全已经由 TLS 加密保障了,而数据库层才是加密算法发挥作用的地方。如果没有HTTPS那么只能前端进行加密)
# ========== 6. 后端数据库加盐加密 ==========
import os
import hashlib
# 密码加盐-复杂版本
def hash_password_pbkdf2(password, salt_hex, iterations=10000):
"""
使用 pbkdf2_hmac 生成密码哈希(返回 hex 字符串)
- password: 明文密码
- salt_hex: hex 格式的 salt(存库时就是 hex) 字符串的盐值
- iterations: 迭代次数(越大越安全但越慢,哈希算法重复计算的次数。目的是减缓密码暴力破解,迭代次数越多越安全,但登录越慢。)
"""
salt = bytes.fromhex(salt_hex) # 转为字节
dk = hashlib.pbkdf2_hmac("sha256", password.encode("utf-8"), salt, iterations)
return dk.hex()
# 密码加盐-简单版本
def make_password_hash(password, salt=None):
"""
:param password: 密码
:param salt: 盐值
:return: sha256(密码), salt(盐值)
"""
if salt is None:
salt = os.urandom(16).hex() # 第一次用户注册-盐值
sha256 = hashlib.sha256((password + salt).encode()).hexdigest()
return sha256, salt
# 验证
def verify(username, password, register=False):
"""
:param username: 用户名,需要保证用户名在数据库中唯一
:param password: 明文密码
:return: verify_status 计算登录的密码与数据库记录的密码是否一致,返回 True 或 False
"""
# 1.根据用户名从数据库中找到对应的盐值,为了验证用户名称是否重复
get_user_info = f"""
SELECT
salt,
password_hash
FROM
user
WHERE
username = '{username}'
"""
verify_status = True # 验证状态
if register:
print("当前是注册")
pwd_hash, salt = make_password_hash(password)
# 判断当前用户名是否进行注册,如果注册,就通知用户更改用户名,没有注册就进行注册
insert_sql = f"""
INSERT INTO
user(username,password_hash,salt)
VALUES
('{username}','{pwd_hash}','{salt}')
"""
else:
print("验证登录")
salt = 'xxxxx' # 拿到从数据库拿到的盐值
password_hash = 'xxxxx' # 拿到从数据库拿到加密密码
pwd_hash, salt = make_password_hash(password, salt)
if pwd_hash != password_hash: # 如果不相等,密码验证失败
verify_status = False
return verify_status
verify_status = verify("admin", "admin123")
print(verify_status)
2.passlib模块(第三方)
说明:
- 一个强大的密码哈希库,支持 BCrypt、PBKDF2、SHA512 等算法,可用于 存储用户密码(安全不可逆),以及 验证密码登录。
算法名称 类名 特点 / 用途 bcrypt bcrypt非常常见、抗暴力破解、CPU 计算量适中(72字节问题 ) bcrypt_sha256 bcrypt_sha256对长密码先做 sha256 再 bcrypt(72字节问题 ) pbkdf2_sha256 pbkdf2_sha256NIST 推荐算法,可配置迭代次数 pbkdf2_sha512 pbkdf2_sha512同上,更强安全性 sha256_crypt sha256_crypt纯 CPU 延迟算法,性能高但抗 GPU 较弱,比 sha512_crypt快一些。sha512_crypt sha512_crypt类似 sha256_crypt,哈希更强。速度上点慢(肉眼可见)。 argon2 argon2最现代、安全性最高,抗 GPU 暴力破解,需要安装 pip install argon2_cffi。md5_crypt md5_crypt历史兼容,已过时 plaintext plaintext明文存储(测试用)
安装:
pip install passlib
# ========== 1. sha256方式 ==========
from passlib.hash import sha256_crypt
hashed = sha256_crypt.hash("mypassword123")
print("加密后的密码:", hashed) # $5$rounds=535000$3b1CdHWHd7lVb23r$vp41MNFGMr75A0JQM6OBkFjfU5J7ld419vT/p0ahNP6
print(sha256_crypt.verify("mypassword123", hashed)) # True
print(sha256_crypt.verify("wrongpass", hashed)) # False
# ========== 2. 常用方式 ==========
from passlib.hash import pbkdf2_sha256
def hash_password(password):
"""哈希密码"""
return pbkdf2_sha256.hash(password)
def verify_password(plain_password, hashed_password):
"""验证密码"""
return pbkdf2_sha256.verify(plain_password, hashed_password)
pwd = "admin123" # 原密码
hash_pwd = hash_password(
password) # 哈希后的密码:$pbkdf2-sha256$29000$GeMcA4Bwzvk/p3RurRVCiA$HUz8W/FqnamrtbBjWujyomikorf0L91ivy1CdDVIvn8
verify_status = verify_password("admin", hash_pwd) # 用户输入的密码进行验证
print(verify_status) # False
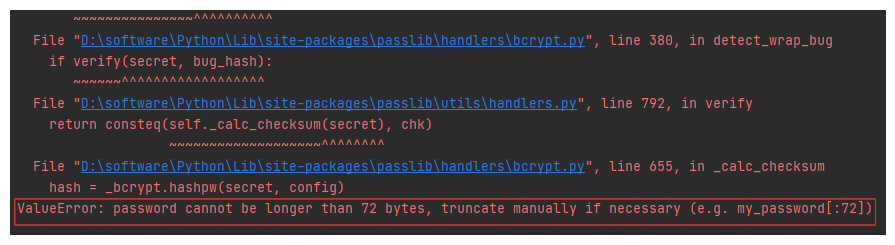
# ========== 3. bcrypt/bcrypt_sha256解决72字节的问题 ==========
# 报错:
ValueError: password cannot be longer than 72 bytes, truncate manually if necessary (e.g. my_password[:72])
# 可能使用因为环境的原因导致( windows + python )。
# 解决方式:使用特定的版本,或者不使用bcrypt_sha256和bcrypt
pip uninstall bcrypt py-bcrypt bcryptor -y
pip install bcrypt==3.2.0
pip install passlib==1.7.2
3.hmac模块
作用:
- 标准库中一个非常重要的安全模块,它的作用是用来进行 消息认证(Message Authentication),也就是判断数据在传输过程中是否被篡改。
- hmac的全称:Hash-based Message Authentication Code。
- 用一个“密钥 + 哈希算法”生成一个固定长度的签名(摘要),用于验证数据完整性和身份。
应用场景:
场景 示例 说明 接口签名验证 API 请求头附带 sign参数防止参数被篡改 第三方回调验证 微信、支付宝回调签名验证 确认来源合法 Token / Session 加密 自定义登录状态签名 防止伪造 Token 文件校验 文件传输或下载后比对 HMAC 保证文件未被改动 使用的方法:
方法 说明 hmac.new(key, msg, digestmod)创建一个新hash对象并且返回( msg/key需要传递字节,复杂的结构需要通过json转换字符串在通过encode转换字节)hmac.compare_digest(a, b)验证ab两个前面是否相同,防止“时间攻击”。注意对比类型需要ASCII字符。 .update(msg)更新hash内容(可以多次)。 .digest()返回字节序列()。 .hexdigest()返回16进制字符串。 ASCII和非ASCII字符:
- ASCII字符:英文字母、数字、基本标点符号等(共128个)
- 非ASCII字符:中文、日文、韩文、表情符号等非英文字符
import hmac
# 使用方式
hmac.new(key, msg, digestmod)
参数说明:
key:就是秘钥(私钥)
msg:消息
digestmod:就是加密算法,使用的哈希算法,如 hashlib.md5、hashlib.sha256(需要使用hashlib模块)。
# ========== 1. 基本使用 ==========
import hmac
import hashlib
h = hmac.new(b"123456", b"hello world", hashlib.sha256) # 使用的sha256哈希算法
print(h.hexdigest()) # 输出的结果:83b3eb2788457b46a2f17aaa048f795af0d9dabb8e5924dd2fc0ea682d929fe5
# ========== 2. 多次更新消息使用update方法 ==========
h = hmac.new(b"123456", b"hello world", hashlib.sha256)
h.update(b"asdasdasdsadsa")
h.update(b"123456")
print(h.hexdigest()) # 输出的结果:13816cfaec548bacb6fc36e6a6be4bd26eb0de56821227fc61b9e7ec6307805a
# ========== 3. 查看不同的返回结果 ==========
h = hmac.new(b"123456", b"hello world", hashlib.sha256)
print(h.hexdigest()) # 输出的结果:13816cfaec548bacb6fc36e6a6be4bd26eb0de56821227fc61b9e7ec6307805a
print(h.digest()) # b"\x13\x81l\xfa\xecT\x8b\xac\xb6\xfc6\xe6\xa6\xbeK\xd2n\xb0\xdeV\x82\x12'\xfca\xb9\xe7\xecc\x07\x80Z"
# ========== 4. 验证签名是否一致 ==========
sign1 = hmac.new(b'secret', b'data3', hashlib.sha256).hexdigest()
sign2 = "asdasdsad"
if hmac.compare_digest(sign1, sign2): # 必须是字符串,并且是ASCll字符符
print("签名正确")
else:
print("签名错误")
# 补充说明:为什么key和msg必须是字节格式
因为 HMAC(以及所有加密算法、哈希算法)底层操作的对象是字节(Byte),不是字符串。所以需要传递的时候将数据转换为字节。
另外,因为python语言的原因,不会直接显示字节码,字节显示可读是一种友好的设计。
data = {
"name": "123",
"age": "456",
}
print(json.dumps(data).encode()) # 输出的结果(可以很好的辨认): b'{"name": "123", "age": "456"}'
# 案例:
import hmac, hashlib, json
def make_sign(data, secret_key):
"""
生成签名
:param data: 数据体
:param secret_key: 秘钥
:return: 签名(字符串)
"""
# 将数据体转为字符串(使用标准化 JSON,避免字典 key 顺序不固定导致签名不一致)
# 按照字母排序:sort_keys=True
# 去除空格:separators=(',', ':')
# 避免因为细微的差距(空格,顺序)导致签名的结果不同
msg = json.dumps(data,sort_keys=True,separators=(',', ':'))
return hmac.new(secret_key.encode(), msg.encode(), hashlib.sha256).hexdigest()
def verify_sign(data, secret_key, sign):
"""
起名验证
:param data: 数据体
:param secret_key: 秘钥
:param sign: 原来的签名
:return:
"""
calc_sign = make_sign(data, secret_key)
return hmac.compare_digest(calc_sign, sign)
key = "abc123"
params = {"user": "1001", "money": "999"}
sign = make_sign(params, key)
print("签名结果:", sign) # 签名: 4625c46b7066e44d0b8f76d222e023796eb98dc1a77528938947d0b36fced0a3
print("验证结果:", verify_sign(params, key, sign)) # 验证结果: True
4.secrets模块
作用:
- 生成 安全的随机数,用于密码、认证令牌、密钥等,不可预测,适合安全需求,不适合普通游戏或统计模拟(这种场景用
random即可)。常用的函数方法:
函数 描述 示例 secrets.randbelow(n)返回 [0, n)之间的整数secrets.randbelow(10)→ 生成 0~9 的随机数secrets.randbits(k)返回 k 位随机整数( 位数(bits)) secrets.randbits(8)→ 0~255 的随机数secrets.choice(seq)从序列中随机选一个元素 secrets.choice('abcdef')→ 'b'secrets.token_bytes([nbytes])生成 nbytes 长的随机字节串 secrets.token_bytes(16)→ b'\x9a\x1c...'secrets.token_hex([nbytes])生成 nbytes 长的随机十六进制字符串 secrets.token_hex(16)→ '9a1c...'secrets.token_urlsafe([nbytes])生成 nbytes 长的 URL 安全字符串(使用 Base64 编码,但进行了 URL 安全处理) secrets.token_urlsafe(16)→ 'k9f4G...')
import secrets
# secrets 的生成速度比 random 慢,因为是加密安全随机数
# ========== 1. 基本使用 ==========
print(secrets.randbelow(99)) # 取0-99 之间的随机数
print(secrets.randbits(8)) # 0-255之间的随机数
print(secrets.choice(['a', '1', 'z'])) # 从列表中取随机一个元素
print(secrets.token_bytes(10)) # 成生成 10 字节随机字节串:b'$u/Lu\xc3\x19\x8d\xc0\xae'
print(secrets.token_hex(10)) # 随机十六进制字符串:6918308d2842b628adc1
print(secrets.token_urlsafe(16)) # 随机的 16 字节生成 URL 安全字符串: quckudpGdCrY5Qk4Maq-Yw
"""
token_urlsafe 专用于url使用,使用 Base64 编码,但进行了 URL 安全处理。
把 + 替换为 -
把 / 替换为 _
去掉末尾 = 填充符
"""
# randbits 补充说明:
randbits(8):
8位数:00000000 - 11111111 转换位10进制就是 0-255 之间的随机数
16位数:0000000000000000 - 1111111111111111 转换位10进制 0-65535之间的随机数
# 示例:生成随机密码
import secrets
import string
alphabet = string.ascii_letters + string.digits + "!@#$%^&*()"
password = ''.join(secrets.choice(alphabet) for i in range(12))
print(password) # 例如输出: 'A9!k3bT@z6Qp'
# 示例:生成安全令牌
token = secrets.token_urlsafe(16) # URL 安全的随机令牌
print(token) # 例如: 'D5sF2x8aQeW9b7Lk'
5.正则与文本处理
1.re模块
说明:
- 里用于 正则表达式(Regular Expression) 的核心模块,用来处理字符串的匹配、查找、替换、提取等操作。
功能 示例 查找字符串中符合规则的内容 邮箱、手机号、身份证号等验证 替换字符串内容 清理 HTML 标签、替换敏感词 拆分字符串 比如按多个分隔符拆分 提取子字符串 提取 URL、域名、关键字段 常用的方法:
函数 说明 re.match(pattern, string)从 开头 匹配 (只从第一个匹配) re.search(pattern, string)在 任意位置 搜索第一个匹配 re.findall(pattern, string)返回 所有匹配结果(列表) re.finditer(pattern, string)返回一个 迭代器对象(可取 match 对象) re.split(pattern, string)按匹配的内容拆分字符串(如果匹配的内容在字符串开头或结尾,split 会生成 空字符串。) re.sub(pattern, repl, string)替换匹配内容 re.compile(pattern)编译成正则对象,重复使用时更高效 .group()提取匹配的内容(匹配第一个时使用 match,search).groups()分组提取使用,返回一个分组匹配元祖数据 .groupdict()当匹配时是分组匹配,并没对分组命名是使用 常规语法:
符号 含义 .匹配任意一个字符(除换行) ^从匹配开头(开始符) $匹配结尾(结束符) *重复 0 次或多次 +重复 1 次或多次 ?重复 0 或 1 次 {n}重复 n 次(重复前一个字符N次) {n,}重复至少 n 次(重复前一个字符N次) {n,m}重复 n~m 次(重复前一个字符N次-M次) []字符集(匹配 [ ]内的全部字符)[^]取反字符集(取反) ()分组(捕获) \d数字 [0-9]\D非数字 \w单词字符 [A-Za-z0-9]\W非单词字符 \s空白字符(空格、制表符、换行) \S非空白字符 (?P<name>...)命名分组(可以通过名字获取分组捕获的数据) []的用法:
正则表达式 含义 匹配示例 [abc]匹配 a、b、c 任意一个字符 "a","b","c"[0-9]匹配任意一位数字 "0" ~ "9"[a-z]匹配任意小写字母 "a" ~ "z"[A-Z]匹配任意大写字母 "A" ~ "Z"[a-zA-Z0-9]匹配任意字母或数字 "a" ~ "z","A" ~ "Z","0" ~ "9"[^0-9]匹配非数字 "a","_","?"标志位 flags:
标志 名称 含义 re.IIGNORECASE 忽略大小写 re.MMULTILINE 多行模式 re.SDOTALL .匹配换行符re.XVERBOSE 忽略空格/注释,使正则更易读
import re
# ========== 1. 方法基本使用 ==========
r = "test"
match和search可以通过.group() 获取匹配到的值
match:# 匹配单个
print(re.match("t", r)) # 结果:t ,返回是一个re对象
print(re.match("e", r)) # 结果:None
search:# 匹配单个
print(re.search("e", r)) # 结果:e ,返回是一个re对象
findall与finditer:# 匹配全部符合条件
print(re.findall("t", r)) # 结果:['t', 't'] ,返回的类型是 list
print(re.finditer("a", r)) # 结果:<callable_iterator object at 0x000001E85B792560> 返回一个迭代对象,可以通过循环
split: # 匹配拆分
print(re.split("t", r)) # 结果:['', 'es', ''],如果匹配的内容在字符串开头或结尾,split 会生成 空字符串。
print(re.split("e", r)) # 结果:['t', 'st'],
sub:# 匹配替换
print(re.sub("t", "b", r)) # 结果:besb ,将t替换为b
compile:# 提前将匹规则转换为re对象
rx = re.compile("t")
print(re.search(rx, r)) # 结果:<re.Match object; span=(0, 1), match='t'>
# ========== 2. 语法基本使用 ==========
注意:关于 ^ 和 $ 如果使用真正的字符必须是符合条件的
注意:? 和 * 匹配的性质相同,只不过最大次数不同,但是都可以匹配到0次,就会导致第一个匹配的字符如果不正确,结果就是空值
注意:\D \d \w \W \s \S 但是使用时,请使用r"\d"进行转义,在 Python 字符串中,\ 是一个转义符。会误认为进行转义。
test = "1aaa#11%1 1xzczdz"
print(re.search("1.", test)) # . 代表匹配任意一个字符 匹配:1a
print(re.search("^1", test)) # ^ 匹配的字符必须是开头 匹配:1
print(re.search("z$", test)) # $ 匹配最后一个字符必须是结尾 匹配:z
print(re.search("x*", test)) # * 匹配0到N次 匹配:空,为什么是空因为它就在开头这里匹配到了一个 空字符串 就返回结果(可以是0次)
print(re.search("a+", test)) # + 匹配1到N次 匹配:aa,最少匹配1次所以就会有结果
print(re.search("a?", test)) # ? 匹配0到1次 匹配:空,为什么是空因为它就在开头这里匹配到了一个 空字符串 就返回结果(可以是0次)
print(re.search("a{2}", test)) # {n} 匹配前一个字符n次 匹配:aa
print(re.search("a{2,}", test)) # {n,} 匹配前一个字符最小n次,后面没有限制 匹配:aaa....
print(re.search("a{1,2}", test)) # {n,m} 匹配前一个字符最小n次,最大m次,后面没有限制 匹配:aa
print(re.search(r"\d", test)) # \d 匹配数字 匹配:1
print(re.search(r"\D", test)) # \D 匹配非数字(任何字符) 匹配:a
print(re.search(r"\w", test)) # \w 匹配[a-z0-9A-z] 匹配:a
print(re.search(r"\W", test)) # \w 匹配除了[a-z0-9A-z]其他符号 匹配:#
print(re.search(r"\s", test)) # \w 匹配空格、制表符、换行 匹配:
print(re.search(r"\S", test)) # \w 匹配除了空格、制表符、换行 匹配:1
print(re.search(r"[zcd]", test)) # [] 匹配[]内的任意字符 匹配:z
print(re.search(r"[^zcd]", test)) # [] 匹配除了[]内的任意字符 匹配:1
# () 分组,可以在不同情况使用分组,只获取分组的结果
print(re.search(r"(\w+)\S", test)) # 匹配结果:1aaa#
print(re.search(r"(\w+)\S", test).groups()) # 结果:('1aaa',) 只获取分组的数据
# (?P<name>) 命名分组,可以在不同情况使用分组,只获取分组的结果,对这个分组进行命名操作。
print(re.search(r"(?P<name>\w+)\S", test)) # 匹配结果:1aaa#
print(re.search(r"(?P<name>\w+)\S", test).groupdict()) # 结果:{'name': '1aaa'}
# 补充:match与search的区别
search:它是扫描整个字符串,返回第一个符合的结果。
match:从开头匹配,开头符合就符合,不符合返回None
1-1.场景
import re
# 1.手机号提取
text = "我的电话是13812345678,你的呢?"
result = re.findall(r'1[3-9]\d{9}', text)
print(result) # ['13812345678']
# 2.邮箱提取
text = "联系我:test_01@163.com 或 hello@gmail.com"
emails = re.findall(r'[\w.-]+@[\w.-]+\.\w+', text)
print(emails)
# 3.敏感词替换
text = "你是脑子不好吗"
new_text = re.sub("脑子不好", "****", text)
print(new_text) # 结果:你是****吗
# 4.分组提取
text = "订单号:PO-2025-0001"
match = re.search(r'PO-(\d+)-(\d+)', text)
print(match.groups()) # ('2025', '0001')
# 5.命名分组提取
text = "订单号:PO-2025-0001"
match = re.search(r'PO-(?P<num_1>\d+)-(?P<num_2>\d+)', text) # ?P<num_2> 对分组进行命名,然后可以通过groupdict获取字典,然后读取数据
print(match.groups()) # 结果:('2025', '0001')
print(match.groupdict()) # 结果:{'num_1': '2025', 'num_2': '0001'}
# 6.多行匹配
text = """第一行
第二行
第三行"""
# re.M 允许 ^ 和 $ 匹配多行
print(re.findall(r'^\S+', text, re.M)) # ['第一行', '第二行', '第三行']
2.string模块
作用:
- 主要提供各种字符串常量、字符集合和辅助函数,用来简化字符串处理、验证、随机生成、格式化等操作。
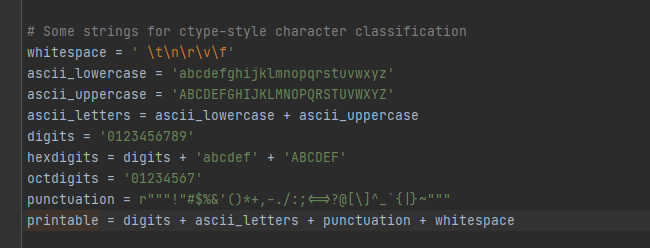
常量名 含义 示例输出 string.ascii_lowercase全部小写字母 'abcdefghijklmnopqrstuvwxyz'string.ascii_uppercase全部大写字母 'ABCDEFGHIJKLMNOPQRSTUVWXYZ'string.ascii_letters大小写字母组合 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ'string.digits数字 '0123456789'string.hexdigits十六进制字符 '0123456789abcdefABCDEF'string.octdigits八进制字符 '01234567'string.punctuation所有标点符号 '!"#$%&\'()*+,-./:;<=>?@[\\]^_{string.printable可打印字符(字母、数字、标点、空白) '0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ..."string.whitespace所有空白符 ' \t\n\r\x0b\x0c'
import string
# ========== 1. 方法基本使用 ==========
print(string.ascii_letters) # 结果:abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ
print(string.ascii_lowercase) # 结果:abcdefghijklmnopqrstuvwxyz
# 场景1:生成随机字符串
import string, random
chars = string.ascii_letters + string.digits
random_code = ''.join(random.choice(chars) for _ in range(8))
print(random_code) # 比如:PyRitTwK
# 场景2:验证字符串内容
import string
s = "Hello123"
if all(ch in string.ascii_letters + string.digits for ch in s):
print("只包含字母和数字")
# 场景3:检查是否为可打印字符
import string
text = "abc!@#"
print(all(ch in string.printable for ch in text)) # True
3.difflib模块
作用:
- 比较文本差异,生成相似度匹配结果,找出字符,文件或者列表之间的不同点。
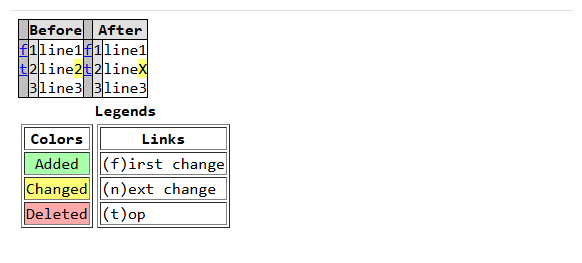
功能 方法 说明 比较两个字符串或列表 difflib.Differ().compare(a, b)行对比,返回增删改信息 生成统一 diff difflib.unified_diff(a, b, fromfile, tofile)类似 git diff 输出 相似度计算 difflib.SequenceMatcher(None, a, b).ratio()返回 0~1 相似度 模糊匹配 difflib.get_close_matches(word, possibilities)找出最相似的匹配项 生成 HTML 差异报告 difflib.HtmlDiff().make_file(a, b)输出 HTML 对比文件
import difflib
# ========== 1. 字符比较 ==========
" " 开头:相同
"- " 开头:第一个字符 独有
"+ " 开头:第二个字符 独有
"? ^" 代表不同的
text1 = """line1
line2
line3
line4"""
text2 = """line1
line2 changed
line3
line5"""
diff = difflib.Differ()
result = diff.compare(text1.splitlines(), text2.splitlines())
print('\n'.join(result))
"""
结果:
line1
- line2
+ line2 changed
line3
- line4
? ^
+ line5
? ^
"""
# ========== 2.生成与git类似的格式(文件对比) ==========
text1 = ["a\n", "b\n", "c\n"] # old.txt 旧文件内容
text2 = ["a\n", "x\n", "c\n"] # new.txt 新文件内容
diff = difflib.unified_diff(text1, text2, fromfile='old.txt', tofile='new.txt')
print(''.join(diff))
"""
结果:
--- old.txt
+++ new.txt
@@ -1,3 +1,3 @@
a
-b
+x
c
"""
# 参数说明:
fromfile:旧文件 --- 表示旧文件(由 fromfile 指定)
tofile:新文件 +++ 表示新文件(由 tofile 指定)
# ========== 3.字符串相似度匹配 ==========
from difflib import SequenceMatcher
a = "apple"
b = "appla"
ratio = SequenceMatcher(None, a, b).ratio()
print(ratio) # 0.8
# ========== 4.模糊匹配 ==========
words = ['python', 'java', 'javascript', 'ruby']
target = 'javas'
matches = difflib.get_close_matches(target, words, n=2, cutoff=0.5)
print(matches) # ['java', 'javascript']
# 参数说明:
n: 返回最多几个匹配结果
cutoff: 相似度阈值(0~1),低于此值不返回
# ========== 5.输出一个html(网页展示)==========
text1 = """line1
line2
line3"""
text2 = """line1
lineX
line3"""
html = difflib.HtmlDiff().make_file(
text1.splitlines(),
text2.splitlines(),
fromdesc='Before',
todesc='After'
)
with open('diff.html', 'w', encoding='utf-8') as f:
f.write(html)
3-1.案例
# 文件版本对比工具
import difflib
def compare_files(file1, file2):
with open(file1, encoding='utf-8') as f1, open(file2, encoding='utf-8') as f2:
diff = difflib.unified_diff(
f1.readlines(), f2.readlines(),
fromfile=file1, tofile=file2
)
print(''.join(diff))
compare_files("old.txt", "new.txt")
3-2.为什么结果使用join
import difflib
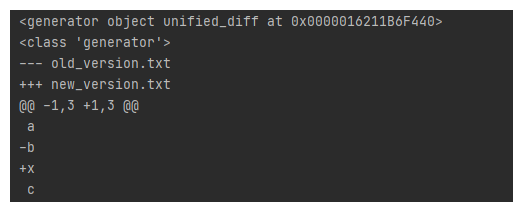
text1 = ["a\n", "b\n", "c\n"]
text2 = ["a\n", "x\n", "c\n"]
result = difflib.unified_diff(
text1,
text2,
fromfile='old_version.txt',
tofile='new_version.txt'
)
print(result) # 结果:<generator object Differ.compare at 0x000001AF555CCCC0> 是一个可迭代的对象
print(type(result)) # 结果:<class 'generator'>
# 为什么用 ''.join(diff)
join() 是 Python 拼接字符串的常用方法。
因为 diff 返回的每个元素本身是字符串(代表一行 diff 输出),所以我们要把它们拼成一个完整的大字符串,方便打印或写入文件。
4.textwrap模块
作用:
- 文本格式化模块,主要用于 控制文本的换行、缩进、宽度、填充 等操作 —— 在控制台输出、生成报告、日志格式化等场景特别常用。
函数 作用 返回类型 fill()自动换行 字符串 wrap()自动换行 列表 dedent()去除统一缩进 字符串 indent()添加前缀 字符串 shorten()文本截断 + 省略号 字符串
import textwrap
# ========== 1. 自动换行 fill ==========
text = "Python is an easy to learn, powerful programming language."
result = textwrap.fill(text, width=20) # width=20 表示每行最大 20 个可见字符(包括字母、数字、空格和标点)
print(result)
"""
结果:
Python is an easy to
learn, powerful
programming
language.
"""
注意:它不是每一行都是20个字符
根据单词,尽可能不拆开单词,在保证每行长度 ≤ width 的前提下,找到最合理的换行点(通常是空格)。
操作步骤:
Python # 字符6不满足
Python is # 字符9不满足
Python is an # 字符12不满足
Python is an easy # 字符17不满足
Python is an easy to # 字符20满足 → 换行
learn, # 字符6不满足
learn, powerful # 字符17不满足 → 换行
programming # 字符11不满足 → 换行
language. # 字符9不满足 结束
# ========== 2. 自动换行并返回列表 wrap ==========
text = "Python is an easy to learn, powerful programming language."
lines = textwrap.wrap(text, width=20) # 根据换行的结果,返回一个列表结构,它与fill相同,尽可能不拆开单词,保持长度。
print(lines) # 结果:['Python is an easy to', 'learn, powerful', 'programming', 'language.']
# ========== 3. 去缩进 dedent ==========
text = """
def hello():
print("Hello World")
"""
print(textwrap.dedent(text)) # 用于清除多行字符串中的统一缩进(按照python语言的缩进规则4个空格)
"""
结果:
def hello():
print("Hello World")
"""
# ========== 4. 添加前缀 indent ==========
data = "line1\nline2\nline3"
print(textwrap.indent(data, prefix=">>> ")) # 根据换行符 \n 来判断每一行的起始位置,然后在每一行前面自动加上前缀字符串。
"""
结果
>>> line1
>>> line2
>>> line3
"""
# ========== 5. 文本截断 shorten ==========
text = "This is a very long sentence that needs to be shortened."
# 计算30个字符(包含placeholder设置的字符数),后面的进行截断,后面加上 ...
short = textwrap.shorten(text, width=30, placeholder="...") # 它与fill相同,尽可能不拆开单词,保持长度。
print(short) # This is a very long...
6.多线程与多进程
线程与进程的关系:
- 线程是进程的一部分,是更小的执行单元,进程好比办公室,线程就是办公室房间的工作的人。
- 一个进程最少有一个主线程,而进程可以有多个线程,它们会共享进程中的资源。
- CPU 密集型任务用 multiprocessing
- I/O 密集型任务用 threading
对比项 线程 ( threading)进程 ( multiprocessing)内存空间 共享 独立(不共享) GIL(全局解释器锁) 有影响(同一时刻只有一个线程执行Python字节码) 不受 GIL 限制 适合场景 I/O 密集型(文件、网络) CPU 密集型(计算、图像处理) 创建成本 轻 重(需要独立内存空间) 进程线程从属关系解释:
- 在一个py脚本执行时(会启动一个 进程(Process))。
- 那么内部执行代码的部分是线程执行(最小单位),负责执行你的脚本代码。
- 当在这段代码内部创建一个线程,创建的线程与最初线程属于同一个进程 , 与主线程(进程自带)属于平等关系(内存、文件句柄、变量空间等,彼此独立调度)。
Python 进程(由操作系统创建) │ ├── 内存空间(变量、对象、堆等) ├── 文件描述符、网络端口、环境变量... │ ├── 主线程 MainThread(系统自动创建) │ └── 运行你的 main 代码块(__main__) │ ├── 子线程 Thread-1(你手动创建) │ └── 运行目标函数 worker_1() │ └── 子线程 Thread-2 └── 运行目标函数 worker_2()
1.threading模块
说明:
- 用来实现 并发执行多个任务(例如同时下载文件、同时处理多个请求等)。
常见的写法:
写法 用法 说明 重写 run()方法适合继承式写法 自定义逻辑封装在线程类中 传入 target函数适合函数式写法 不需要继承 Thread 类
1-1.基本用法(函数式)
主要参数:
参数 说明 target线程要执行的函数 args传递给函数的位置参数(元组) kwargs传递给函数的关键字参数(字典) name自定义线程的名称 线程对象.start()启动线程 线程对象.join()主进程等待线程完成 线程对象.is_alive()判断线程是否仍在运行 线程对象.name获取或设置线程名称 threading.active_count()当前活动线程数量 threading.current_thread()获取当前线程对象(当前脚本主线程对象)
import time
import threading
def worker(name):
print(f"{name} 开始工作")
time.sleep(2)
print(f"{name} 完成工作")
# 创建线程 target=需要调用的函数名称
t1 = threading.Thread(target=worker, kwargs={"name": "线程1"}, name="我是线程t1") # 采用关键字传递参数
t2 = threading.Thread(target=worker, args=("线程2",), name="我是线程t2") # 采用位置传递参数
# 启动线程
t1.start()
print(f"t1线程名称:{t1.name},是否存活:{t1.is_alive()}") # t1线程名称:我是线程t1,是否存活:True
t2.start()
print(f"t2线程名称:{t2.name},是否存活:{t2.is_alive()}") # t2线程名称:我是线程t2,是否存活:True
# 当前活动线程数量
print(threading.active_count()) # 结果:3 除了当前2个可见线程,还有当前执行脚本的主线程
# 获取当前线程对象
print(threading.current_thread()) # 结果:<_MainThread(MainThread, started 248)>
# 主线程等待两个线程执行完毕
t1.join()
t2.join()
print("所有线程执行完毕")
1-2.继承Thread的写法(继承式)
# 目的:
无需再显式调用 run()
import threading
import time
class MyThread(threading.Thread):
def __init__(self, name):
super().__init__()
self.name = name
def run(self):
print(f"{self.name} 开始执行")
time.sleep(1)
print(f"{self.name} 执行完成")
t1 = MyThread("线程A")
t2 = MyThread("线程B")
# 启动线程
t1.start()
t2.start()
# 主线程等待线程完成
t1.join()
t2.join()
# 说明:
为什么只需要重写 run 方法就可以直接实现执行,因为在 start() 启动线程中调用了
1.执行代码:_start_joinable_thread(self._bootstrap, handle=self._handle,daemon=self.daemon)
2.执行代码:self._bootstrap方法中调用了 self._bootstrap_inner()在它的内部执行了 self.run() 方法,所以就会实现当启动线程后,直接执行了run方法。
3.在原run()方法中其实调用了self._target()直接执行了传递的回调函数,在初始化时:
threading.Thread(target=worker) 初始化 init 方法中 self._target=target 赋值
# 其实本质上来说,就是让原来 run 执行内容(self._target()) 进行修改自定义的内容。
1-3.线程锁
说明:
- 由于线程共享数据,多个线程同时修改变量时会造成 数据竞争(race condition)。此时需要使用
Lock进行加锁保护。什么条件下加锁:
- 当多个线程可能同时修改同一个数据时,必须使用锁来保护。
- 不需要锁: 只读操作、线程局部数据、独立资源。
- 需要锁: 写操作、复合操作、检查然后操作。
场景 不加锁 加锁 结果 不确定,数据可能丢失 确定,数据正确 性能 快 稍慢(但保证了正确性) 适用场景 只读操作、独立数据 写操作、共享数据 注意: 所存在两种状态,一种加锁,一种解锁,另外一定要注意死锁。
import threading lock = threading.Lock() print(f"初始状态: {'已锁定' if lock.locked() else '未锁定'}") # 加锁 lock.acquire() print(f"加锁后: {'已锁定' if lock.locked() else '未锁定'}") # 解锁 lock.release() print(f"解锁后: {'已锁定' if lock.locked() else '未锁定'}") # 推荐使用 with lock: # 自动加锁 自动解锁(即使出现异常) pass
- 死锁的概念: 死锁是使用了两个锁(锁的顺序不同),AB,一个线程先试用了A锁然后在使用了B锁,另外一个线程先试用了B锁在使用了A锁。
import threading import time # 两个锁 lock_a = threading.Lock() lock_b = threading.Lock() def worker1(): """线程1:先获取A锁,再获取B锁""" print("Worker1: 等待锁A...") with lock_a: print("Worker1: 获得锁A") time.sleep(1) # 故意延迟,让worker2有机会获取锁B print("Worker1: 等待锁B...") with lock_b: # 这里会阻塞,因为worker2持有锁B print("Worker1: 获得锁B - 完成工作") def worker2(): """线程2:先获取B锁,再获取A锁""" print("Worker2: 等待锁B...") with lock_b: print("Worker2: 获得锁B") time.sleep(1) # 故意延迟,让worker1有机会获取锁A print("Worker2: 等待锁A...") with lock_a: # 这里会阻塞,因为worker1持有锁A print("Worker2: 获得锁A - 完成工作") # 启动两个线程 t1 = threading.Thread(target=worker1) t2 = threading.Thread(target=worker2) print("=== 死锁演示开始 ===") t1.start() t2.start() t1.join(timeout=3) # 设置超时,避免永久等待 t2.join(timeout=3) if t1.is_alive() or t2.is_alive(): print("!!! 检测到死锁 !!! 线程无法完成") else: print("所有线程正常完成")
import threading
# 不加锁
counter = 0
def increment():
global counter
for _ in range(100000):
counter += 1 # 这个操作不是原子的!
# 创建5个线程,每个线程增加10万次
threads = []
for _ in range(5):
t = threading.Thread(target=increment)
threads.append(t)
t.start()
for t in threads:
t.join()
print(f"不加锁的结果: {counter}") # 预期应该是 500000,但实际结果会小于这个值!
# 加锁
counter = 0
l = threading.Lock() # 创建锁
def increment():
global counter
for _ in range(100000):
with l: # 使用锁保护关键代码
counter += 1 # 这个操作不是原子的!
# 创建5个线程,每个线程增加10万次
threads = []
for _ in range(5):
t = threading.Thread(target=increment)
threads.append(t)
t.start()
for t in threads:
t.join()
print(f"加锁的结果: {counter}") # 500000
1-4.守护线程
是什么:
- 在后台运行的线程,当所有非守护线程结束时自动终止。
- 守护线程就像是"可有可无"的助手,主程序离开时它们会立即消失,不会拖慢程序的退出。
- 当主线程结束时,所有守护线程会自动强制终止,不会出现"主线程已经退出,但子线程还在运行"的情况。
特点:
- 主线程退出后,创建的子线程也跟着退出(
与join()方法不同,它是等待子线程执行完毕后,主线程退出)。- 守护主线程创建的子线程。
- 区分:
- 守护线程:主线程结束 → 守护线程自动终止(对于可中断的、辅助性的任务)
- 普通线程:主线程结束 → 等待所有普通线程完成(对于重要的、必须完成的任务)
使用场景:
- 后台监控和心跳。
- 日志记录,缓存更新。
- 垃圾回收,任何可以随时中断的后台任务。
- 比如:服务健康检查,游戏的背景音乐,数据采集中的进度显示
import time import threading def background(): while True: print("后台线程运行中...") time.sleep(2) t = threading.Thread(target=background, daemon=True) # daemon=True 设置守护线程 t.start() time.sleep(5) print("主线程结束,后台线程也结束。")
import threading
import time
class BackgroundService:
def __init__(self):
self._monitor_thread = None
self._should_run = True
def start_monitoring(self):
"""启动后台监控(守护线程)"""
def monitor():
while self._should_run:
# 执行监控任务
self._check_health()
time.sleep(5)
self._monitor_thread = threading.Thread(
target=monitor,
daemon=True, # 设置为守护线程
name="HealthMonitor"
)
self._monitor_thread.start()
print("后台监控已启动")
def _check_health(self):
"""监控任务的具体实现"""
print(f"[健康检查] 系统正常 - {time.strftime('%H:%M:%S')}")
def main_work(self):
"""主业务逻辑"""
print("开始主业务处理...")
for i in range(3):
time.sleep(2)
print(f"处理业务 {i+1}/3")
print("主业务处理完成")
# 使用
service = BackgroundService()
service.start_monitoring() # 启动守护线程
service.main_work() # 执行主任务
print("程序结束,监控线程自动退出")
1-5.线程池
说明:
- 线程池是多线程编程中非常重要的概念,它可以高效管理线程资源。是一种提前创建好一定数量线程并循环复用的机制。
ThreadPoolExecutor内的参数:
参数 说明 max_workers最大线程数 ThreadPoolExecutor内的方法:
方法 说明 submit(fn, *args)提交任务,返回 Future对象map(fn, iterable)批量提交任务(阻塞),返回 Future对象列表future.result(timeout)获取结果,支持超时参数 future.exception()获取执行任务异常,并且打印异常的信息 future.cancel()取消任务(未开始的任务) shutdown(wait=True,cancel_futures=False)关闭线程池,因为使用了 with上下文管理器它会自动调用shutdown关闭。wait参数是:是否等待所有任务执行完毕后再返回。如果为 False,立即返回,但后台线程仍可能在运行。,cancel_futures参数:是否取消尚未开始执行的任务(Python 3.9+)。如果为 True,队列中未执行的任务会被直接取消。future.cancel()说明:
- 在
Future(异步任务的执行状态)对象是存在3中状态,未开始(pending),运行中(running),已完成(finished 或 cancelled)。import time from concurrent.futures import ThreadPoolExecutor def slow_task(n): time.sleep(2) return f"任务 {n} 完成" executor = ThreadPoolExecutor(max_workers=1) f1 = executor.submit(slow_task, 1) f2 = executor.submit(slow_task, 2) # 立即尝试取消 f2 print("取消 f2:", f2.cancel()) # True print("f1 是否运行中:", f1.running()) # True print("f2 是否取消:", f2.cancelled()) # True time.sleep(3) print("f1 结果:", f1.result()) # 打印:f1 结果: 任务 1 完成 print("f2 是否完成:", f2.done()) # f2 是否完成: True executor.shutdown()
import time
from concurrent.futures import ThreadPoolExecutor
# ========== 1. 单一提交任务 submit ==========
def worker(name):
print(f"{name} 开始工作")
time.sleep(2)
return f"{name} 完成任务"
# 创建最大 3 个线程的线程池
with ThreadPoolExecutor(max_workers=3) as executor:
future = executor.submit(worker, "线程1")
print(future.result()) # 阻塞等待返回结果,获取线程调用回调函数的返回结果
# ========== 2. 批量提交任务 map(是阻塞的(会等待所有任务完成),适合简单批量处理。) ==========
def worker(x):
return x * x
with ThreadPoolExecutor(max_workers=4) as executor:
results = executor.map(worker, [1, 2, 3, 4, 5])
print(list(results)) # [1, 4, 9, 16, 25]
# ========== 3. 等待多个任务完成 as_completed ==========
def worker(x):
time.sleep(x)
return f"任务 {x} 完成"
with ThreadPoolExecutor(max_workers=3) as executor:
futures = [executor.submit(worker, i) for i in range(5)]
# print(futures[0].result()) # 也可以通过这种索引方式获取
# futures打印结果: [<Future at 0x1ea61b16ba0 state=finished returned str>, ....]
for f in as_completed(futures): # 通过循环 as_completed 来获取结果
print(f.result())
# ========== 4. 异常超时捕获 ==========
def risky_task(x):
if x == 2:
raise ValueError("出错了!")
return x * 10
with ThreadPoolExecutor(max_workers=2) as executor:
futures = [executor.submit(risky_task, i) for i in range(4)]
for f in as_completed(futures):
print(f.exception()) # 打印结果:任务异常: 出错了!
try:
print(f.result(timeout=3))
except Exception as e:
print("任务异常:", e)
# ========== 5. 手动关闭线程池 ==========
executor = ThreadPoolExecutor(max_workers=2)
for i in range(5):
executor.submit(print, f"任务 {i}")
executor.shutdown(wait=True) # 等待任务全部执行完
print("所有任务完成,线程池关闭。")
2.multiprocessing模块
说明:
- 用于多进程并行计算 的核心模块,它能充分利用 多核 CPU(不像
threading被 GIL 限制)。- 进程与进程之间信息不共享,完全隔离开。
常用方法:
函数 / 类 作用 Process(target=func,args=(),kwargs={})创建单个子进程(支持关键字传参和位置传参) start()启动进程 join()等待所有子进程退出,必须在 close()或terminate()后使用terminate()强制结束进程,需要与 join()一起使用,需要再join()之前。close()等待现有任务完成,不在接受新任务,需要与 join()一起使用,需要再join()之前。Pool(processes=n)创建进程池 Queue()跨进程通信队列 Manager()跨进程共享对象 进程池提交方式:
方法 说明 返回值类型 apply(func, args)同步执行一个任务 函数返回结果 apply_async(func, args)异步执行一个任务 AsyncResultmap(func, iterable)同步批量执行任务 listmap_async(func, iterable)异步批量执行任务 MapResul进程与进程池基本使用:
import os, time from multiprocessing import Process,Pool # ========== 1. 基本使用 ========== def task(name,age): print(f"子进程 {name} 开始执行, PID={os.getpid()}") time.sleep(2) print(f"子进程 {name} 结束") if __name__ == "__main__": print("主进程开始") p1 = Process(target=task, args=("A",),kwargs={"age":18}) # 同样支持位置传参和关键字传参 p2 = Process(target=task, args=("B",),kwargs={"age":19}) p1.start() # 启动进程 p2.start() p1.join() # 主进程等待子进程执行完毕 p2.join() print("主进程结束") """ 结果: 主进程开始 子进程 A 开始执行, PID=2904 子进程 B 开始执行, PID=13640 子进程 A 结束 子进程 B 结束 主进程结束 """ # ========== 2. 使用进程池 ========== def task(n): print(f"任务 {n} 执行中... PID={os.getpid()}") time.sleep(1) return n * n if __name__ == "__main__": with Pool(processes=4) as pool: # 同时开启4个进程 results = pool.map(task, range(1, 6)) # 自动分配任务 print("结果:", results) """ 结果: 任务 1 执行中... PID=17068 任务 2 执行中... PID=20088 任务 3 执行中... PID=18496 任务 4 执行中... PID=4544 任务 5 执行中... PID=17068 结果: [1, 4, 9, 16, 25] """
2-1.进程池-同步提交(apply)
from multiprocessing import Pool
import time, os
def task(n):
print(f"执行任务 {n} (PID={os.getpid()})")
time.sleep(1)
return n * 2
if __name__ == "__main__":
pool = Pool(3)
futures = [pool.apply(task, args=(i,)) for i in range(5)] # 使用apply的情况下,需要等待task执行完毕后才会指向下一个任务
print(futures) # pool.apply(task, args=(i,)) 直接返回数据结果
pool.close()
pool.join()
2-2.进程池-异步提交任务(apply_async)
# 更灵活的进程池用法,可以异步处理多个任务。
from multiprocessing import Pool
import time, os
def task(n):
print(f"执行任务 {n} (PID={os.getpid()})")
time.sleep(1)
return n * 2
if __name__ == "__main__":
pool = Pool(3)
futures = [pool.apply_async(task, args=(i,)) for i in range(5)] # apply_async的特点不会阻塞,可以同时运行多个任务
# 获取结果
for f in futures:
# f: <multiprocessing.pool.ApplyResult object at 0x000002B9F73ED160>
print("结果:", f.get()) # 返回一个 AsyncResult 对象,需要循环提取任务的结果
pool.close()
pool.join()
2-2-1.ApplyResult方法
方法 / 属性 作用 .get(timeout=None)等待任务完成并返回结果,可设置超时(阻塞) .ready()判断任务是否执行完毕(返回 True/False)(非阻塞) .successful()判断任务是否成功(任务已完成才会能使用,如果没有完成使用就会报错) .wait(timeout=None)等待任务完成但不返回结果(阻塞),当需要任务完成后,才会执行下面代码时可以使用,防止任务没有完成导致下面代码执行出现错误
import time
from multiprocessing import Pool
def slow_task(x):
time.sleep(2)
return x * 2
# ========== 1. get 获取执行结果(阻塞,需要等待任务完成后才会有结果) ==========
if __name__ == "__main__":
with Pool(2) as pool:
r = pool.apply_async(slow_task, args=(5,))
print(r.get(timeout=3)) # 结果:10 ,如果超过了timeout的时间,就会出现异常报错。
# ========== 2. ready 判断任务是否执行完毕(非阻塞,可以直接获取执行到底完成没有) ==========
if __name__ == "__main__":
with Pool(2) as pool:
r = pool.apply_async(slow_task, args=(5,))
while not r.ready(): # r.ready() 返回:True/False
print("任务还没完成...")
time.sleep(0.5)
print("任务结果:", r.get())
# ========== 3. wait 等待任务完成,但不取值(阻塞,需要等待任务完成) ==========
if __name__ == "__main__":
with Pool(2) as pool:
r = pool.apply_async(slow_task, args=(5,))
r.wait(timeout=3) # 等待任务完成,但不取值
print("已完成:", r.get())
# ========== 3. successful 判断是否成功 ==========
if __name__ == "__main__":
with Pool(2) as pool:
futures = [pool.apply_async(slow_task, args=(i,)) for i in range(5)]
for i in futures:
i.wait() # 等待进程任务完成
if i.ready(): # 进程任务判断是否执行完毕
if i.successful():
print("任务成功完成,结果:", i.get())
else:
print("任务尚未完成")
2-3.进程池-批量提交(map)
from multiprocessing import Pool
import time, os
def task(n):
print(f"执行任务 {n} (PID={os.getpid()})")
time.sleep(1)
return n * 2
if __name__ == "__main__":
pool = Pool(3)
futures = pool.map(task, [1, 2, 3, 4, 5, 6])
print(futures) # 结果:[2, 4, 6, 8, 10, 12]
pool.close()
pool.join()
2-4.进程池-批量异步提交(map_async)
from multiprocessing import Pool
import time, os
def task(n):
print(f"执行任务 {n} (PID={os.getpid()})")
time.sleep(1)
return n * 2
if __name__ == "__main__":
pool = Pool(3)
futures = pool.map_async(task, [1, 2, 3, 4, 5, 6])
# futures 是一个 MapResult 对象
print(futures.get()) # [2, 4, 6, 8, 10, 12]
pool.close()
pool.join()
2-4-1.MapResul对象的方法
- 它的用法与ApplyResult对象的用法是相同的,只不过
.get()返回的是 一个列表(批量结果)。
方法 说明 示例 .get(timeout=None)获取所有结果(阻塞) res.get()→[1,4,9,16].wait(timeout=None)等待所有任务完成(不取值,阻塞) res.wait().ready()判断所有任务是否完成(不阻塞) res.ready().successful()判断所有任务是否都成功完成 res.successful()
import time
from multiprocessing import Pool
def slow_square(x):
time.sleep(1)
return x * x
if __name__ == "__main__":
with Pool(4) as pool:
result = pool.map_async(slow_square, [1, 2, 3, 4, 5])
# result.wait() # 等待全部任务完成后,在执行下面的代码
print("任务提交完成!")
# 1.检查状态
while not result.ready(): # 当使用wait()时,ready()检查状态的意义就不存在了,因为wait等待全部任务完成。
print("任务执行中...")
time.sleep(0.5)
# 2.获取所有结果
values = result.get()
print("任务结果:", values)
# 3.确认是否成功
print("是否全部成功:", result.successful())
2-5.进程池关闭方式
| 使用方式 | 是否需要手动 close() | 是否自动 join() |
|---|---|---|
手动管理池使用close() |
需要 | 需要 |
使用 with Pool() |
不需要 | 自动执行 |
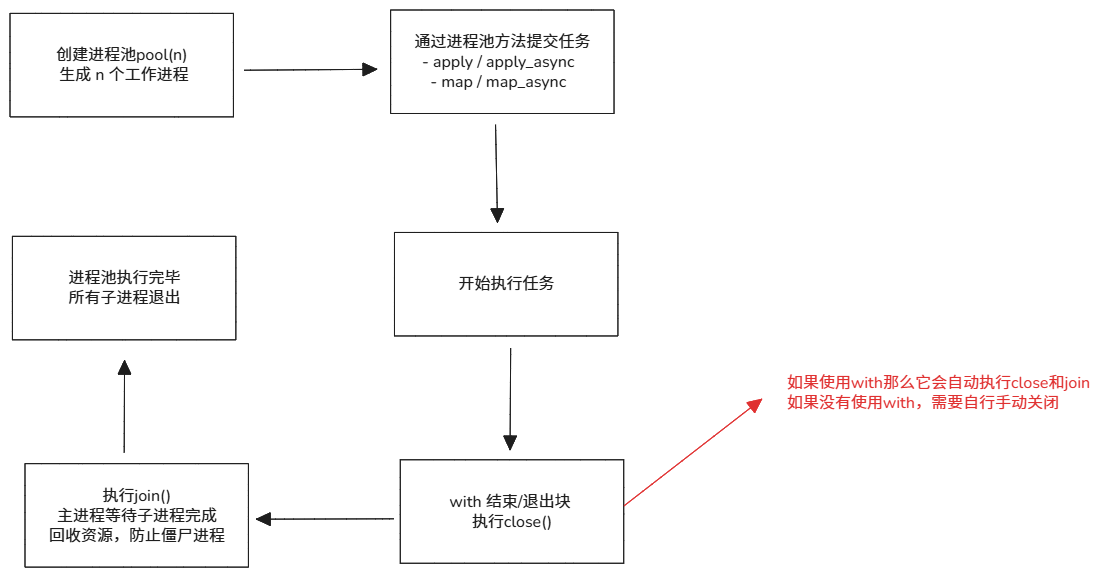
2-5-1.手动关闭
# 特定:
1.告诉进程池不再接收新任务,等待已提交的任务执行完后自动关闭进程池。
2.当代码执行到 close() 时,进程池将不再接受新的任务,但会等待并完成所有在 close() 之前提交的任务。
# 注意:
需要配合jion进行配合使用,因为它让主进程等待子进程。
def task(x):
if x == 3:
raise ValueError("任务3出错")
time.sleep(2)
return x * 2
if __name__ == "__main__":
pool = Pool(4)
for i in range(10):
pool.apply_async(task, args=(i,))
pool.join() # 这里会报错!
# 报错的原因:
因为进程池的任务正在运行(子进程任务正在运行),但是走到这一步主进程就会关闭,连带着子进程,但是子进程还未完成工作。所以需要使用colse()。
pool.colse() # 等待现有任务完成。
pool.join() # 就不会报错,因为colse会等待现有任务完成。
# 解释:
本质上它就是为了优雅的关闭进程池使用的。
2-5-2.自动关闭
from multiprocessing import Pool
import time
def task(x):
time.sleep(2)
return x * 2
if __name__ == "__main__":
with Pool(4) as pool:
futures = [pool.apply_async(task, args=(i,)) for i in range(3)]
results = [f.get() for f in futures]
print(results) # [0, 2, 4]
# 解释:
with的语句在结束后会调用:
pool.close()
pool.join()
2-6.强制关闭进程任务
# terminate 作用:
当代码执行到 terminate() 时,无论任务是否已经开始执行或还在等待队列中,都会立即被终止。
当进程池内出现执行出现异常时,那么可以使用,防止后续也会出现异常。
import time
from multiprocessing import Pool
def task(x):
if x == 3:
raise ValueError("当x是3时就进行报出异常") # 1.当x=3会主动抛出异常
time.sleep(2)
return x * 2
if __name__ == "__main__":
with Pool(4) as pool:
try:
futures = [pool.apply_async(task, args=(i,)) for i in range(6)]
results = [f.get() for f in futures]
print(results)
except Exception as e: # 2.会被捕获
pool.terminate() # 3.它就会终止全部的任务无论是正在执行还是正在排队的
print(e)
finally:
pool.join() # 4.由于terminate会终止全部的子进程任务,不在等待结果,建议使用join防止出现僵尸进程(会等待所有子进程退出,并自动清理系统资源。)
2-7.跨进程通信队列
# Queue 是一个队列,将数据放入队列,然后在取出
from multiprocessing import Process, Queue
import time
def producer(q):
for i in range(5):
q.put(i) # 传递数据
print(f"生产 {i}")
time.sleep(0.5)
def consumer(q):
while True:
item = q.get() # 获取数据
print(f"消费 {item}")
if item == 4:
break
if __name__ == "__main__":
q = Queue() # 创建对象
p1 = Process(target=producer, args=(q,)) # 将这个对象作为参数传递
p2 = Process(target=consumer, args=(q,))
p1.start()
p2.start()
p1.join()
p2.join()
2-8.跨进程共享对象
# Manager
from multiprocessing import Process, Manager
def worker(shared_list, int_counter, shared_dict):
int_counter.value += 1 # 注意:单个值重新赋值
shared_list.append(1)
if not shared_dict.get('number'):
shared_dict['number'] = 1
else:
shared_dict['number'] += 1
if __name__ == "__main__":
with Manager() as manager:
# Manager 常用的类型 列表和字典,进程执行任务将这些数据放入到这数据类型中进行存储。除了这些还有其他类型
shared_list = manager.list() # 共享列表
shared_dict = manager.dict() # 共享字典
int_counter = manager.Value('i', 0) # 注意:单个值设置
procs = [Process(target=worker, args=(shared_list, int_counter, shared_dict)) for _ in range(2)]
for p in procs:
p.start()
for p in procs:
p.join()
print("共享列表:", shared_list) # 共享列表: [1, 1]
print("共享单个值:", int_counter.value) # 共享单个值: 2 注意:单个值取值
print("共享字典:", shared_dict) # 共享单个值: {'number': 2}
3.queue模块
说明:
- 并发通信工具模块,它是 线程安全 的队列实现,用于在多线程之间安全地交换数据。
类型:
类名 特点 queue.Queue先进先出(FIFO)队列,最常用 queue.LifoQueue后进先出(LIFO)队列(类似栈) queue.PriorityQueue优先级队列(按优先级排序出队)
import queue
# ========== 1.先进先出 Queue ==========
q = queue.Queue(maxsize=3) # 可选参数maxsize,限制队列最大长度
# 添加元素(生产者)
q.put("任务1")
q.put("任务2")
q.put("任务3")
# 注意:当使用put_nowait添加元素时,超出队列设置maxsize长度就会抛出异常 queue.Full
q.put_nowait("任务4") # 等价于 q.put("任务3", block=False)
# 获取元素(消费者)
print(q.get(timeout=3)) # 输出: 任务1
print(q.get()) # 输出: 任务2
print(q.get()) # 输出: 任务2
# 注意:如果队列没有数据,通过 get_nowait 取值就会抛出异常
try:
item = q.get_nowait()
except queue.Empty:
print("队列为空")
# 表示之前通过 get() 取出的一个任务已经处理完成。
q.task_done()
# 阻塞当前线程,直到队列中所有任务都完成(即 put() 的数量和 task_done() 的数量相等)。长期运行的项目(例如 Web 服务、后台守护线程)中不会使用
q.join() # 只有一次性任务才会使用,它会等待所有任务完成后在结束。
# 注意:
q.put("任务A") # 若队列满,会阻塞直到有空位
item = q.get() # 若队列空,会阻塞直到有数据,可以通过添加超时参数 timeout
如果使用 put 方式添加元素,并且超出设置的maxsize时,会出现阻塞。
如果使用 get 方式获取数据时,如果队列数据为空,会出现阻塞。
# ========== 2.先进后出 LifoQueue ==========
q = queue.LifoQueue()
q.put(1)
q.put(2)
print(q.get()) # 输出2(后进先出)
print(q.get()) # 输出1(后进先出)
# ========== 3.优先级排序 PriorityQueue ==========
q = queue.PriorityQueue()
q.put((2, "普通任务"))
q.put((1, "紧急任务"))
print(q.get()) # 输出 (1, '紧急任务')
3-1.实例-邮箱队列
# mail_queue.py
import threading
import queue
import time
# 定义全局队列
email_queue = queue.Queue(maxsize=100)
# 邮件发送逻辑
def send_email(task):
print(f"正在发送邮件至 {task['to']},主题:{task['subject']}")
time.sleep(2)
print(f"邮件发送完成:{task['to']}")
# 后台线程任务 - 消费者
def email_worker():
print("邮件服务线程已启动...")
while True:
task = email_queue.get() # 阻塞等待任务,get 会阻塞直到有数据
if task is None: # 用于优雅退出,如果取到的值是空的就关闭线程死循环
print("邮件服务线程已关闭。")
break
try:
send_email(task)
except Exception as e:
print(f"邮件发送失败:{e}")
finally:
email_queue.task_done() # 无论成功与否执行 表示通过get取出的任务已经处理完毕了
# 启动线程函数(只调用一次)
def start_email_worker():
worker = threading.Thread(target=email_worker, daemon=True) # 使用线程开启,然后后台运行
worker.start()
return worker
# 外部添加任务接口 - 生产者
def add_email_task(to, subject, body):
email_queue.put({
"to": to,
"subject": subject,
"body": body
})
# 优雅关闭(项目退出时调用)
def stop_email_worker():
email_queue.put(None)
# app.py
from flask import Flask, jsonify
from mail_queue import start_email_worker, add_email_task, stop_email_worker
app = Flask(__name__)
# 启动后台线程
worker_thread = start_email_worker()
@app.route("/send_mail")
def send_mail():
add_email_task("user@example.com", "欢迎!", "这是一封测试邮件")
return jsonify({"msg": "邮件任务已添加"})
@app.route("/")
def home():
return jsonify({"msg": "服务正常运行"})
@app.teardown_appcontext
def shutdown_session(exception=None):
# Flask 应用关闭时调用(优雅关闭)
stop_email_worker()
print("邮件服务已关闭")
if __name__ == "__main__":
app.run(debug=True)
4.concurrent.futures模块
说明:
- 一个 高级并发执行框架,非常方便地使用 线程池(ThreadPoolExecutor) 或 进程池(ProcessPoolExecutor) 来并发执行任务。
- 它的底层封装了,线程模块和进程模块。就是将线程模块和进程模块合并到了一起然后提供更加高效的性能。
核心执行器:
类名 说明 ThreadPoolExecutor 使用多线程实现(适合 I/O 密集任务,如网络请求、文件读写) ProcessPoolExecutor 使用多进程实现(适合 CPU 密集任务,如计算、图像处理) 常用方法: 与线程和进程模块的方法相似
方法 说明 submit(fn, *args, **kwargs)提交单个任务,返回一个 Future对象,需要通过调用result获取返回值map(fn, iterable)提交多个任务(同步获取结果,类似内置 map())返回generator对象shutdown(wait=True)关闭线程池(类似 close()+join()),如果使用with它会自动执行(建议使用)。as_completed(futures)迭代已完成任务的结果(那个任务先完成,先处理)用于批量任务情况。只能处理 futures对象wait(futures)阻塞等待一组任务完成 Future.result()获取任务返回值(阻塞),只能用于 Future对象Future.cancel()取消尚未开始的任务,只能用于 Future对象Future.done()判断任务是否完成,只能用于 Future对象
# ========== 1.线程池使用 ==========
import time
from concurrent.futures import ThreadPoolExecutor, as_completed
def download_file(url):
print(f"正在下载 {url}")
time.sleep(2)
return f"{url} 下载完成"
urls = ["a.com", "b.com", "c.com"]
# 通过列表循环 submit(单任务提交) 实现批量提交
with ThreadPoolExecutor(max_workers=3) as executor:
futures = [executor.submit(download_file, url) for url in urls]
# futures 输出结果:[<Future at 0x1b843b46ba0 state=running>, ...] 需要通过result获取执行函数的返回值
for future in as_completed(futures):
print(future.result())
# map 批量提交
with ThreadPoolExecutor(max_workers=3) as executor:
futures = executor.map(download_file, urls)
# futures 输出结果: <generator object Executor.map.<locals>.result_iterator at 0x000002991449D3F0> 可迭代对象
for i in futures:
print(i) # 打印直接就是返回结果本身
# ========== 2.进程池使用 ==========
from concurrent.futures import ProcessPoolExecutor
def cpu_task(n):
return sum(i * i for i in range(n))
if __name__ == "__main__": # Windows 上使用进程池必须写这个,不然会无限递归启动进程。
# map 批量提交
with ProcessPoolExecutor(max_workers=2) as executor:
results = executor.map(cpu_task, [2, 3, 4])
print(list(results))
# 通过循环的方式 submit(单任务提交) 批量提交
with ProcessPoolExecutor(max_workers=2) as executor:
results = [executor.submit(cpu_task, i) for i in [2, 3, 4]]
for i in as_completed(results):
print(i.done())
print(i.result())
6.压缩与归档
1.zipfile模块
说明:
- 属于python内的对压缩与解压 ZIP 文件 的模块。
- 基本功能:压缩,解压查看zip的文件内容,追加zip压缩文件,读取压缩包中的文件内容(无需解压)。
常见的方法:
类 / 方法 说明 zipfile.ZipFile()创建或读取一个 ZIP 文件的对象(核心入口) .write(filename, arcname)将文件写入 ZIP 压缩包 .extract(member, path)解压单个文件 .extractall(path)解压所有文件 .namelist()获取压缩包内所有文件名列表 .infolist()获取详细文件信息(含大小、时间戳等) .read(name)读取文件内容(bytes 格式),需要转。 .close()关闭 ZIP 文件,如果使用 with自动关闭(建议使用)。zipfile.is_zipfile(path)判断一个文件是否为 ZIP 文件 操作符号:
操作 模式 'r'读取 ZIP 'w'新建 ZIP(会覆盖旧文件) 'a'追加 ZIP(没有回创建) 'x'新建 ZIP(存在则报错)
import os
import zipfile
# ========== 1.压缩 ==========
with zipfile.ZipFile("text.zip", 'w', compression=zipfile.ZIP_DEFLATED) as z: # compression 使用压缩算法 zipfile.ZIP_DEFLATED 是常见压缩算法
z.write('./123.txt', arcname='788777.txt') # arcname 指压缩包中的被压缩的文件名称名称
z.write('./456.txt', arcname=os.path.basename('456.txt')) # os.path.basename 文件路径获取文件名称
# ========== 2.读取压缩的内容 ==========
print(zipfile.is_zipfile('text.zip')) # 判断一个文件是否为 ZIP 文件,返回 False/True
with zipfile.ZipFile("text.zip", 'r', ) as z:
print(z.namelist()) # ['788777.txt', '456.txt'] 读取压缩包中,都压缩了哪些文件
print(z.infolist()) # 读取压缩内的文件详细文件信息
data = z.read('456.txt').decode('utf-8') # 读取当前压缩文件 456.txt 文件内容
print(data)
# ========== 3.解压文件 ==========
with zipfile.ZipFile("text.zip", 'r', ) as z:
z.extractall(path='./test') # 解压全部文件,到 test 文件夹内,如果没有会创建
z.extract('456.txt', path='./test') # 只解压 456.txt 文件到 test 文件夹内,如果没有会创建
# ========== 4.追加文件到压缩文件 ==========
with zipfile.ZipFile('text.zip', 'a', compression=zipfile.ZIP_DEFLATED) as zf: # 如果 text.zip 不存在会创建一个text.zip压缩文件
zf.write('data.json', arcname='data.json')
2.tarfile模块
说明:
- 标准库中的一个强大压缩模块,但更灵活、跨系统性更好,尤其在 Linux/Unix 环境下使用非常广泛。
写入(压缩算法模式):
格式 模式 压缩算法 .tar'w'无压缩, output.tar.tar.gz'w:gz'gzip 压缩, output.tar.gz.tar.bz2'w:bz2'bzip2 压缩, output.tar.bz2.tar.xz'w:xz'xz 压缩(Python 3.3+), output.tar.xz读取追加(模式):
模式 含义 示例文件扩展名 'r'只读 .tardata.tar'r:gz'只读 .tar.gzdata.tar.gz'r:bz2'只读 .tar.bz2data.tar.bz2'r:xz'只读 .tar.xzdata.tar.xzr:*自动识别压缩算法只读模式 .xz,.gz,.bz2'a'追加 output.tar'x'排它写入 如果写的文件存在就会报错 常用方法:
方法 / 属性 说明 tarfile.open(name, mode)打开或新建 tar 文件 .add(name, arcname)向压缩包添加文件或文件夹 .extract(member, path)解压单个文件 .extractall(path)解压全部文件 .getnames()获取包内所有文件名 .getmembers()获取文件详细信息列表(文件大小,名称,时间等等) .getmember(name)获取单个成员的详细信息(文件大小,名称,时间等等) .close()关闭压缩文件,如果使用 with它会自动调用。tarfile.is_tarfile(path)判断文件是否是 tar 格式
import tarfile
# ========== 1.压缩 ==========
with tarfile.open("example.tar.gz", "w:gz") as tar:
tar.add("123.txt") # 添加压缩文件
tar.add("456.txt")
tar.add("data.json", arcname="789.json") # arcname 修改当前文件在压缩文件的名称
print(tarfile.is_tarfile("example.tar.gz")) # 判断是否是tar格式,返回: True / False
# ========== 2.解压 ==========
with tarfile.open("example.tar.gz", "r:gz") as tar:
tar.extractall(path="output_folder") # 解压全部文件 path=解压到指定目录
tar.extract("123.txt",path="output_folder01") # 解压单个文件
# ========== 3.获取压缩文件内信息 ==========
with tarfile.open("example.tar.gz", "r") as tar: # 模式需要调整为 r
print(tar.getnames()) # 包内所有文件名:['123.txt', '456.txt', '789.json']
print(tar.getmembers()) # 详细信息:[<TarInfo '123.txt' at 0x286ae7c5cc0>,....]
print(tar.getmember("123.txt")) # 单个成员的详细信息:<TarInfo '123.txt' at 0x1d5b3535cc0>
# ========== 4.追加 ==========
with tarfile.open("example.tar.gz", "a") as tar:
tar.add("123.py")
# 会出现报错:
追加模式(仅适用于未压缩的 .tar 文件,不支持 .gz 或 .bz2),example.tar.gz 是.gz 不支持
# ========== 5.TarInfo常用属性 ==========
with tarfile.open("example.tar.gz", "r") as tar: # 模式需要调整为 r
t = tar.getmember("123.txt")
print(t.name) # 文件名/压缩文件所在的路径
print(t.mode) # 权限(八进制)
print(t.size) # 文件大小 字节
print(t.mtime) # 修改时间 时间戳
print(t.type) # 文件类型(普通文件、目录、链接)
print(t.linkname) # 如果是符号链接,存储链接目标
print(t.uid, t.gid) # 用户 ID 和组 ID
print(t.uname, t.gname) # 用户名和组名 windows没有
3.gzip模块
说明:
- 用于 读写
.gz压缩文件 的模块,它只处理 单文件的压缩与解压,不像tarfile可以处理多个文件打包。- **注意:只支持单文件 **
模式:
模式 含义 'rb'读二进制 gzip 文件 'wb'写入二进制 gzip 文件(覆盖) 'ab'追加二进制 gzip 文件(但通常不推荐,易破坏文件) 'rt'以文本模式读取压缩文件(自动解码) 'wt'以文本模式写入压缩文件(自动编码) 'at'以文本模式追加写入压缩文件(不推荐) 主要方法:
gzip.open(filename, mode='rb', compresslevel=9, encoding=None, errors=None, newline=None) filename:文件路径(或类文件对象) mode:打开模式('rb'、'wb'、'ab'、'rt'、'wt') compresslevel:压缩等级,1~9,默认 9(最高压缩) encoding:文本模式时使用的编码,例如 'utf-8' errors:编码错误处理方式 newline:换行控制(仅文本模式)使用场景:
- 压缩或解压单个大文件。
- 节省传输带宽(HTTP / 网络传输),如果接口数据过大,可以使用gzip压缩后再传递。
- 流式压缩(文件太大,无法一次性读入内存)
import gzip
import shutil
# ========== 1.压缩(wb) ==========
with open("123.txt", "rb") as f_in: # 需要的压缩文件
with gzip.open("123.txt.gz", "wb") as f_out: # 压缩后的文件
shutil.copyfileobj(f_in, f_out) # shutil.copyfileobj() 可以快速把文件内容复制到压缩流中。
# ========== 2.解压(rb) ==========
with gzip.open("123.txt.gz", "rb") as f_in: # 打开压缩文件
with open("123_unzip.txt", "wb") as f_out: # 打开需要写入的文件
shutil.copyfileobj(f_in, f_out) # 写入压缩内容
# ========== 3.写入与读取(wt,rt) ==========
with gzip.open("123.txt.gz", "wt",encoding="utf-8") as f_in: # 对压缩的文件写入内容
f_in.write("Hello gzip!\n你好,压缩!")
with gzip.open("123.txt.gz", "rt",encoding="utf-8") as f_in: # 打开压缩的文件读取内容
print(f_in.read())
# ========== 4.压缩内存中的数据(可以调整模式) ==========
data = b"Python gzip example"
compressed = gzip.compress(data) # 一次性压缩数据并返回压缩后的字符串。
print(compressed) # b'\x1f\x8b\x08...'
decompressed = gzip.decompress(compressed) # 一次性解压缩gzip压缩字符串。返回解压后的字符串。
print(decompressed.decode()) # Python gzip example
# 常用的方式,这是多此一举的方式,tarfile提供了gzip压缩算法(可以一并完成),直接使用就行。
import tarfile
import gzip
import shutil
# 先通过tarfile打包
with tarfile.open("backup.tar", "w") as tar:
tar.add("data_folder")
# 在通过gzip压缩
with open("backup.tar", "rb") as f_in:
with gzip.open("backup.tar.gz", "wb") as f_out:
shutil.copyfileobj(f_in, f_out)
4.bz2模块
说明:
bz2模块提供了对 bzip2 格式压缩文件 的读写支持。bzip2 压缩比一般比 gzip 更高(压得更小),但速度稍慢。.bz2文件通常用于 Linux/Unix 系统。用法与gzip相同。- **注意:只支持单文件 **
模式:
模式 含义 'rb'读二进制 gzip 文件 'wb'写入二进制 gzip 文件(覆盖) 'ab'追加二进制 gzip 文件(但通常不推荐,易破坏文件) 'rt'以文本模式读取压缩文件(自动解码) 'wt'以文本模式写入压缩文件(自动编码) 'at'以文本模式追加写入压缩文件(不推荐) 主要方法:
bz2.open(filename, mode='rb', compresslevel=9, encoding=None, errors=None, newline=None) filename:文件路径(或类文件对象) mode:打开模式('rb'、'wb'、'ab'、'rt'、'wt') compresslevel:压缩等级,1~9,默认 9(最高压缩) encoding:文本模式时使用的编码,例如 'utf-8' errors:编码错误处理方式 newline:换行控制(仅文本模式)
import bz2
# ========== 1.压缩(wb) ==========
data = b"Hello, this is a test for bz2 compression."
# 写入压缩文件
with bz2.open("example.bz2", "wb") as f:
f.write(data)
# ========== 2.解压读取(rb) ==========
with bz2.open("example.bz2", "rb") as f:
content = f.read()
print(content.decode())
# ========== 3.写入与读取(wt,rt) ==========
text = "Python bz2 模块示例"
# 写入(文本模式)
with bz2.open("text.bz2", "wt", encoding="utf-8") as f:
f.write(text)
# 读取(文本模式)
with bz2.open("text.bz2", "rt", encoding="utf-8") as f:
print(f.read())
# ========== 4.压缩内存中的数据(可以调整模式) ==========
data = b"Python bz2 example"
compressed = bz2.compress(data) # 一次性压缩数据并返回压缩后的字符串。
print(compressed) # b'\x1f\x8b\x08...'
decompressed = bz2.decompress(compressed) # 一次性解压缩bz2压缩字符串。返回解压后的字符串。
print(decompressed.decode()) # Python bz2 example
5.lzma模块
说明:
- 提供对 XZ / LZMA 格式文件 的压缩与解压支持。
- 常见的后缀:.xz
、.lzma、.tar.xz- 压缩率最高(通常比
gzip、bz2都小),压缩速度慢,但解压很快特别适合打包体积要求严格的归档文件。模式:
模式 含义 'rb'读二进制 gzip 文件 'wb'写入二进制 gzip 文件(覆盖) 'ab'追加二进制 gzip 文件(但通常不推荐,易破坏文件) 'rt'以文本模式读取压缩文件(自动解码) 'wt'以文本模式写入压缩文件(自动编码) 'at'以文本模式追加写入压缩文件(不推荐) 主要方法:
lzma.open(filename, mode='rb', format=None, check=-1, preset=None, filters=None,encoding=None, errors=None, newline=None) filename:文件路径(或类文件对象) mode:打开模式('rb'、'wb'、'ab'、'rt'、'wt') format:压缩格式 lzma.FORMAT_XZ(默认)、lzma.FORMAT_ALONE 等 check:校验类型,如 lzma.CHECK_CRC64 preset: 压缩级别(0~9,默认 6,越高越慢越小) filters:自定义压缩策略(进阶用法) encoding:文本模式时使用的编码,例如 'utf-8' errors:编码错误处理方式 newline:换行控制(仅文本模式)
import lzma
# ========== 1.压缩(wb) ==========
data = b"Hello, this is an example of LZMA compression."
with lzma.open("example.xz", "wb") as f:
f.write(data)
# ========== 2.解压读取(rb) ==========
with lzma.open("example.xz", "rb") as f:
content = f.read()
print(content.decode())
# ========== 3.写入与读取(wt,rt) ==========
text = "LZMA 支持文本模式写入和读取"
# 写入
with lzma.open("text.xz", "wt", encoding="utf-8") as f:
f.write(text)
# 读取
with lzma.open("text.xz", "rt", encoding="utf-8") as f:
print(f.read())
# ========== 4.压缩内存中的数据(可以调整模式) ==========
data = b"Python lzma compression"
compressed = lzma.compress(data) # 一次性压缩数据并返回压缩后的字符串。
print(compressed) # b'\x1f\x8b\x08...'
decompressed = lzma.decompress(compressed) # 一次性解压缩bz2压缩字符串。返回解压后的字符串。
print(decompressed.decode()) # Python lzma example
7.网络模块
1.socket
是什么:
- 用于进行 网络通信(TCP/UDP) 的底层接口,它直接封装了操作系统的 BSD Socket API。
- 它提供了底层的网络接口,用来创建客户端和服务器端程序。
- 通信模式:1.tcp通信 2.udp通信。
基本概念:
角色 说明 Server(服务器) 等待连接请求(如网站服务器) Client(客户端) 主动发起连接(如浏览器) Socket(套接字) 通信的“端点”,封装了 IP 地址 + 端口号,用于发送和接收数据 基本使用:
import socket # 创建一个 TCP socket s = socket.socket(socket.AF_INET, socket.SOCK_STREAM) # 参数说明: AF_INET 表示使用 IPv4 地址 SOCK_STREAM 表示使用 TCP 协议(可靠、面向连接) # 创建一个 UDP socket s = socket.socket(socket.AF_INET, socket.SOCK_DGRAM) # 参数说明: AF_INET 表示使用 IPv4 地址 SOCK_DGRAM 表示使用 UDP 协议方法:
方法 用途 socket.socket()创建套接字对象 bind((host, port))绑定地址与端口 listen(backlog)开始监听(TCP),连接等待队列(backlog)的最大长度。 accept()接受连接(返回 conn, addr)阻塞 connect((host, port))主动连接(客户端) send(data)/recv(bufsize)TCP 发送 / 接收 sendto(data, addr)/recvfrom(bufsize)UDP 发送 / 接收 settimeout(seconds)设置超时时间 close()关闭套接字
1-1.TCP
import socket
# 服务端
server = socket.socket(socket.AF_INET, socket.SOCK_STREAM) # 创建 socket 对象
server.bind(('127.0.0.1', 8000)) # 绑定 IP 地址和端口
server.listen(5) # 开始监听
print("服务器启动,等待连接...")
conn, addr = server.accept() # 等待客户端连接(阻塞)
print("连接来自:", addr)
data = conn.recv(1024) # 接收 1024个字节
print("收到:", data.decode()) # 打印接受数据
conn.send(b"Hello, client!") # 发送数据
# 关闭连接
conn.close()
server.close()
# 客户端
client = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
client.connect(('127.0.0.1', 8000)) # 连接服务器 127.0.0.1:8000
client.send(b"Hello, server!") # 发送消息
data = client.recv(1024) # 接受服务端消息
print("服务器回复:", data.decode()) # 打印消息
client.close() # 关闭客户端连接
1-2.UDP
# UDP 是无连接的(不需 listen / accept)
import socket
# 服务端
server = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
server.bind(('127.0.0.1', 9000)) # 创建服务器 127.0.0.1:9000
print("UDP 服务器启动...")
while True:
data, addr = server.recvfrom(1024)
print("收到:", data.decode(), "来自:", addr)
server.sendto(b"Got it!", addr)
# 客户端
client = socket.socket(socket.AF_INET, socket.SOCK_DGRAM) # 创建对象
client.sendto(b"Hello UDP!", ('127.0.0.1', 9000)) # 发送消息给 127.0.0.1:9000 服务器
data, addr = client.recvfrom(1024) # 输出内容和连接的服务器地址
print("服务器回复:", data.decode())
client.close()
1-3.关于粘包问题
# 粘包
在传递数据时,分明传递的是2条或者多条,但是由于流式协议没有消息边界,无法保证客户端发送个数据时2条或者条多,服务端接受的数据时2条或者多条,导致数据粘在一起被服务端接受。
# 解决方式:
在传递消息时,先传递数据的字节数,服务端接受后,根据字节数读取数据。
通过struct模块的方法,现将发送数据的长度发送给服务端,然后服务端在解析,在根据字节数读取。
struct.pack('!I', x) # 把整数 `x` 转为 4 字节的网络序二进制
struct.unpack('!I', data) # 把 4 字节二进制解回整数
! 使用网络字节序(大端序)
I 无符号 4 字节整数
import socket
import struct
# 服务端
server = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
server.bind(('127.0.0.1', 8000))
server.listen(1)
conn, addr = server.accept()
while True:
# 1.先读取前4个字节(当前数据的字节总数)
data = conn.recv(4)
if not data:
break
msg_len = struct.unpack('!I', data)[0]
# 2.在根据字节数输出具体的内容
msg = b''
while len(msg) < msg_len:
msg += conn.recv(msg_len - len(msg))
print(msg.decode())
conn.close()
server.close()
# 客户端
client = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
client.connect(('127.0.0.1', 8000))
a_data = b'AAA'
a_len = len(a_data) # 获取数据字节数
client.send(struct.pack('!I', a_len))
client.send(a_data)
b_data = b'BBB'
b_len = len(b_data) # 获取数据字节数
client.send(struct.pack('!I', b_len))
client.send(b_data)
client.close()

2.http.client
说明:
- 用 TCP socket 实现 HTTP 协议的客户端请求。
- 等于对socket进行一次封装,自动构建http的报文。自动解析响应头、状态码、内容。是
urllib、requests的底层依赖。- 但是不能使用到复杂的场景中:自动处理重定向、cookies、编码、压缩等。
场景:
- 内嵌环境,无法安装
requests时,使用仍能发 HTTP 请求。- 实现自定义 SDK 或代理层,实现一个轻量 REST 客户端。
- 对性能要求高的场景,直接地控制 keep-alive、chunked 等行为。
方法:
类 / 方法 作用 HTTPConnection(host, port, timeout)建立 HTTP 连接 HTTPSConnection(host, port)建立 HTTPS(SSL)连接 conn.request(method, url, body=None, headers={})发送 HTTP 请求 conn.getresponse()获取服务器响应对象 response.status/response.reason状态码和原因短语(如 200 OK) response.getheaders()/response.getheader('Content-Type')获取响应头 response.read()读取响应体内容(bytes) conn.close()关闭连接
2-1.GET 请求
import http.client
# 1. 建立 HTTP 连接
conn = http.client.HTTPConnection("www.baidu.com", 80, timeout=10) # HTTPConnection 非加密协议使用
# 2. 发送请求(方法、路径、可选 headers)
conn.request("GET", "/")
# 3. 获取响应对象
response = conn.getresponse() # 所有的数据都是这个响应对象提供的
print(response)
# 4. 读取结果
print("状态码:", response.status)
print("原因:", response.reason)
print("响应头:", response.getheaders())
print("正文内容:", response.read().decode())
# 5. 关闭连接
conn.close()
2-2.POST请求
import http.client
import json
conn = http.client.HTTPSConnection("httpbin.org", 443) # HTTPSConnection 加密协议
headers = {"Content-Type": "application/json"} # 请求头
data = {"username": "alice", "password": "123456"} # 数据
# json.dumps() 转成字符串并编码
body = json.dumps(data)
conn.request("POST", "/post", body=body, headers=headers)
res = conn.getresponse() # 所有的数据都是这个响应对象提供的
print(res.status, res.reason)
print(res.read().decode())
conn.close()
2-3.自定义请求头
conn = http.client.HTTPConnection("httpbin.org", 80)
headers = {
"User-Agent": "MyApp/1.0",
"Authorization": "Bearer abc123"
}
conn.request("GET", "/headers", headers=headers)
response = conn.getresponse()
print(response.read().decode())
conn.close()
2-4.查看原始 HTTP 报文
import http.client
http.client.HTTPConnection.debuglevel = 1 # 打开调试模式
conn = http.client.HTTPConnection("httpbin.org", 80)
conn.request("GET", "/get")
resp = conn.getresponse()
print(resp.read().decode())
conn.close()
3.urllib
说明:
- 用于 URL 处理和 HTTP 请求 的模块集合,它是建立在
http.client之上的,更高级、更好用。常用的模块
模块 说明 urllib.request发送 HTTP/HTTPS 请求、获取响应 urllib.parse用来处理 URL 参数,解析、拼接、编码、解码 URL urllib.error定义请求过程中可能抛出的异常类型 urllib.robotparser解析网站的 robots.txt文件(用于爬虫权限控制)关于:urllib.request
名称 作用 urlopen(url, data=None, timeout=...)打开 URL,返回一个类文件对象(可 .read())Request(url, data=None, headers={}, method='GET')构造请求对象,可定制 headers、方法 build_opener()/install_opener()自定义 opener(用于代理、cookie 处理等) HTTPPasswordMgrWithDefaultRealm,HTTPBasicAuthHandlerHTTP 认证处理 ProxyHandler,HTTPCookieProcessor代理与 Cookie 支持 关于:urllib.parse
函数 作用 urlparse(url)将 URL 分解为各部分(scheme、host、path、query...) urlunparse(tuple)将解析结果重新拼装成 URL urlencode(dict)将字典转为查询字符串( a=1&b=2)parse_qs(query)将查询字符串解析为字典 quote()/unquote()URL 编码与解码(如空格 → %20)基本使用:
import urllib.request url = "https://www.example.com" response = urllib.request.urlopen(url) # 响应对象 print(response.status) # 状态码 print(response.getheader("Content-Type")) # 响应头 html = response.read().decode() # 读取响应体 print(html)
3-1.携带参数
import urllib.request
import urllib.parse
params = {"q": "python urllib", "page": 1}
# 将字典数据转换为查询字符串,打印的结果:q=python+urllib&page=1
query_string = urllib.parse.urlencode(params) # get请求可以直接与查询的url进行拼接
url = f"https://httpbin.org/get?{query_string}"
with urllib.request.urlopen(url) as response:
print(response.read().decode())
3-2.POST请求(发送表单数据)
import urllib.request
import urllib.parse
url = "https://httpbin.org/post"
data = {"username": "alice", "password": "123"}
data = urllib.parse.urlencode(data).encode("utf-8") # 表单数据要转 bytes 输出结果:b'username=alice&password=123'
req = urllib.request.Request(url, data=data, method="POST") # 请求对象,需要通过Request方法明确的指定请求方法(delete,put)
with urllib.request.urlopen(req) as response:
print(response.read().decode())
# 注意:如果需要指定具体的请求需要使用Request
urllib.request.urlopen("https://httpbin.org/put") # 默认识别为get请求
urllib.request.urlopen("https://httpbin.org/put", data=b"xxx") # 默认识别为post请求
3-3.添加请求头
import urllib.request
url = "https://httpbin.org/headers"
headers = {
"User-Agent": "Mozilla/5.0",
"Authorization": "Bearer 12345"
}
req = urllib.request.Request(url, headers=headers) # Request 输出的对象会使用你设定的 method、headers 等信息。
with urllib.request.urlopen(req) as response:
print(response.read().decode())
3-4.异常处理
import urllib.request
import urllib.error # 使用error模块
try:
urllib.request.urlopen("https://no-such-site.example.com")
except urllib.error.HTTPError as e:
print("HTTP 错误:", e.code, e.reason)
except urllib.error.URLError as e:
print("URL 错误:", e.reason)=
3-5.url解析
from urllib.parse import urlparse, parse_qs, urlencode
url = "https://example.com/search?q=python&lang=en"
result = urlparse(url)
print(result.scheme) # https
print(result.netloc) # example.com
print(result.path) # /search
print(parse_qs(result.query)) # {'q': ['python'], 'lang': ['en']}
# 拼接新 URL
params = {"q": "urllib", "lang": "zh"}
print("https://example.com/search?" + urlencode(params))
4.requests
说明:
- 它是一个第三方的库,需要进行安装,用于发送http请求的库,是python中最常用的一种。
响应对象的方法:
属性 说明 response.status_code状态码,如 200,404response.text响应正文(解码为字符串) response.content原始字节数据(如下载图片) response.json()自动解析 JSON 响应为字典 response.headers响应头(字典) response.url实际访问的 URL response.cookies服务端返回的 cookies
import requests
from requests.exceptions import RequestException
# ========== 1.get请求 ==========
response = requests.get("https://httpbin.org/get")
print(response.status_code) # 状态码:200
print(response.headers) # 响应头
print(response.text) # 响应内容(字符串)
# ========== 2.get请求 + 参数==========
params = {"name": "Alice", "age": 20}
response = requests.get("https://httpbin.org/get", params=params)
print(response) # 响应对象
print(response.url) # 自动拼接:https://httpbin.org/get?name=Alice&age=20
print(response.json()) # 自动转成 Python 字典
# ========== 3.post请求(表单提交)==========
data = {"username": "alice", "password": "123456"}
response = requests.post("https://httpbin.org/post", data=data)
print(response.json())
# ========== 4.post请求(json数据)==========
payload = {"user": "alice", "age": 22}
response = requests.post("https://httpbin.org/post", json=payload)
print(response.json())
# ========== 5.自定义请求头 ==========
headers = {
"User-Agent": "MyApp/1.0",
"Authorization": "Bearer token123"
}
response = requests.get("https://httpbin.org/headers", headers=headers) # get和post都可以
print(response.json())
# ========== 6.上传文件 ==========
files = {"file": open("123.txt", "rb")}
response = requests.post("https://httpbin.org/post", files=files)
print(response.json())
# ========== 7.下载文件 ==========
url = "https://httpbin.org/image/png"
r = requests.get(url)
with open("image.png", "wb") as f:
f.write(r.content)
# ========== 8.携带cookie访问 ==========
# 声明会话对象
session = requests.Session()
# 第一次登录
session.post("http://10.8.0.95:8082/general/login/index.php?c=Login&a=loginCheck", data={"username": "kx.wang", "password": "123456","userLang":"cn"})
# 自动带上登录后的 cookie
resp = session.get("http://10.8.0.95:8082/newplugins/css/style.css")
print(resp.text)
# ========== 9.异常处理 ==========
try:
r = requests.get("https://example.com", timeout=3)
r.raise_for_status() # 如果不是 2xx 会抛异常
except RequestException as e:
print("请求出错:", e)
# ========== 10.其他参数 ==========
requests.get("https://httpbin.org", verify=True) # 是否验证ssl证书
requests.get("https://httpbin.org", timeout=5) # 超时设置
proxies = {
"http": "http://127.0.0.1:8080",
"https": "https://127.0.0.1:8080"
}
requests.get("https://httpbin.org", proxies=proxies) # 代理设置
# 使用通用接口,自定义方法
r1 = requests.request("DELETE", "https://httpbin.org/delete")
print(r1.json())
r2 = requests.request("PUT", "https://httpbin.org/put", json={"id": 123})
print(r2.json())
5.websocket
说明:
- WebSocket 是一种网络通信协议,它在单个 TCP 连接上提供全双工的通信信道。简单来说,它允许客户端(如浏览器)和服务器之间进行持续的、双向的实时数据交换。
安装: pip install websockets
5-1.服务端
import asyncio
import websockets
async def handler(websocket):
print("客户端已连接:", websocket.remote_address)
try:
async for message in websocket:
print("收到客户端消息:", message)
await websocket.send("服务器收到:" + message)
except websockets.exceptions.ConnectionClosed:
print("客户端断开连接")
async def main():
async with websockets.serve(handler, "0.0.0.0", 8000):
print("WebSocket 服务器已启动:ws://127.0.0.1:8000")
await asyncio.Future()
asyncio.run(main())
5-2.异步客户端
import asyncio
import websockets
async def client():
async with websockets.connect("ws://127.0.0.1:8000") as ws:
await ws.send("Hello WebSocket")
msg = await ws.recv()
print("收到服务器:", msg)
asyncio.run(client())
5-3.同步客户端
# websocket-client 需要使用它来完成
pip install websocket-client
import websocket
ws = websocket.WebSocket()
ws.connect("ws://127.0.0.1:8000")
ws.send("Hello from client")
print("服务器说:", ws.recv())
ws.close()
5-4.广播
import asyncio
import websockets
clients = set() # 服务端加入一个 set() 保存所有连接
async def handler(websocket, path):
clients.add(websocket)
try:
async for message in websocket:
print("收到:", message)
# 广播
for client in clients:
await client.send("广播:" + message)
finally:
clients.remove(websocket)
async def main():
async with websockets.serve(handler, "0.0.0.0", 8000):
print("服务器已启动")
await asyncio.Future()
asyncio.run(main())
5-5.心跳检测
服务端:
import asyncio
import websockets
async def heartbeat(ws):
"""每 30 秒向客户端发送一次心跳"""
while True:
try:
await ws.send("ping") # 主动 ping
except:
print("心跳失败,断开连接")
break
await asyncio.sleep(30)
async def handler(ws):
print("客户端已连接:", ws.remote_address)
# 启动心跳任务(后台运行,不阻塞)
hb_task = asyncio.create_task(heartbeat(ws))
try:
async for message in ws:
print("收到消息:", message)
await ws.send("服务器收到:" + message)
except websockets.exceptions.ConnectionClosed:
print("客户端断开")
finally:
# 停掉心跳任务,避免内存泄漏
hb_task.cancel()
async def main():
async with websockets.serve(handler, "0.0.0.0", 8000):
print("WebSocket 服务已启动 ws://127.0.0.1:8000")
await asyncio.Future()
asyncio.run(main())
# 客户端:
import asyncio
import websockets
async def test():
async with websockets.connect("ws://127.0.0.1:8000") as ws:
while True:
msg = await ws.recv()
print("收到:", msg)
asyncio.run(test())
5-6.断线重连(客户端)
import time
import websocket
while True:
try:
ws = websocket.WebSocket()
ws.connect("ws://127.0.0.1:8000")
ws.send("hello")
print(ws.recv())
except:
print("连接失败,3秒后重试")
time.sleep(3)
5-7.简单的聊天室
# 安装环境:
pip install flask flask-socketio
# 服务端
from flask import Flask
from flask_socketio import SocketIO, emit
app = Flask(__name__)
socketio = SocketIO(app, cors_allowed_origins="*")
# 当客户端连接时
@socketio.on('connect')
def handle_connect():
print('有客户端连接进来了!')
emit('server_message', {'message': '欢迎连接!我是服务器~'})
# 当客户端发送消息时
@socketio.on('client_message')
def handle_client_message(data):
print(f'📨 收到客户端消息: {data["message"]}')
# 回复客户端
emit('server_message', {'message': f'收到你的消息了: "{data["message"]}"'})
# 当客户端断开时
@socketio.on('disconnect')
def handle_disconnect():
print('客户端断开连接了')
if __name__ == '__main__':
print('WebSocket 服务器启动在: http://localhost:5000')
socketio.run(app, host='0.0.0.0', port=5000, debug=True)
# 客户端:
<!DOCTYPE html>
<html lang="en" >
<head>
<title>最简单的WebSocket客户端</title>
<meta charset="UTF-8">
<style>
body { font-family: Arial; max-width: 600px; margin: 50px auto; padding: 20px; }
#messages { border: 1px solid #ccc; height: 300px; overflow-y: scroll; padding: 10px; margin: 10px 0; }
.message { margin: 5px 0; padding: 8px; border-radius: 5px; }
.server { background: #e3f2fd; }
.client { background: #f3e5f5; text-align: right; }
.system { background: #fff3e0; text-align: center; }
input, button { padding: 10px; margin: 5px; }
</style>
</head>
<body>
<h1>简单聊天室</h1>
<div id="messages"></div>
<div>
<input type="text" id="messageInput" placeholder="输入消息..." style="width: 70%;">
<button onclick="sendMessage()">发送</button>
<button onclick="connect()">连接</button>
<button onclick="disconnect()">断开</button>
</div>
<!-- 引入 Socket.io 客户端库 -->
<script src="https://cdn.socket.io/4.5.0/socket.io.min.js"></script>
<script>
let socket = null;
function connect() {
// 连接服务器
socket = io('http://localhost:5000');
// 当连接成功时
socket.on('connect', function() {
addMessage('系统', '连接服务器成功!', 'system');
});
// 当收到服务器消息时
socket.on('server_message', function(data) {
addMessage('服务器', data.message, 'server');
});
// 当连接断开时
socket.on('disconnect', function() {
addMessage('系统', '连接已断开', 'system');
});
}
function sendMessage() {
const input = document.getElementById('messageInput');
const message = input.value.trim();
if (message && socket) {
// 发送消息到服务器
socket.emit('client_message', { message: message });
addMessage('我', message, 'client');
input.value = '';
}
}
function disconnect() {
if (socket) {
socket.disconnect();
socket = null;
}
}
function addMessage(sender, text, type) {
const messages = document.getElementById('messages');
const messageDiv = document.createElement('div');
messageDiv.className = `message ${type}`;
messageDiv.innerHTML = `<strong>${sender}:</strong> ${text}`;
messages.appendChild(messageDiv);
messages.scrollTop = messages.scrollHeight;
}
// 页面加载时自动连接
window.onload = connect;
</script>
</body>
</html>
9.三方模块
1.PyJWT模块
说明:
- 编码和解码 JSON Web Tokens (JWT) 的流行库。JWT 是一种开放标准(RFC 7519),它定义了一种紧凑且自包含的方式,用于在各方之间安全地将信息作为 JSON 对象传输。
- 主要由三个部分组成:
Header,Payload,Signature,组成如下:``xxxxx.yyyyy.zzzzz`
- Header:包含令牌类型(如 JWT)和所使用的签名算法(如 HS256 或 RS256)。
- Payload:包含声明(Claims)。声明是关于实体(通常是用户)和其他数据的语句。有三种类型的声明:注册的、公共的和私有的。
- 注册声明:预定义的一组键,如
iss(签发者),exp(过期时间),sub(主题),aud(受众)等。它们是可选的,但建议使用。- 公共声明:可以自定义的键,但为了避免冲突,应在 IANA JSON Web Token Registry 中定义或使用抗冲突命名空间的 URI。
- 私有声明:在同意使用它们的各方之间共享的自定义声明。
- Signature:用于验证消息在传输过程中没有被篡改。签名是通过对编码后的头部、编码后的负载、一个密钥(secret)以及头部中指定的算法生成的。
安装:
pip install PyJWT场景:
- 前后端分离架构,当做用户认证,代替session。
- 单点登录系统,通过中央认证服务签发 JWT,各个子系统使用公钥验证。
- API访问控制,微服务间通信认证使用。
- 核心场景:还是用户认证使用。
1-1.生成JWT
import jwt from datetime import datetime,timezone,timedelta now_utc = datetime.now(timezone.utc) # jwt 签发时间必须带上时区 SECRET_KEY = "my_secret_key" payload = { "user_id": 123, "iat": now_utc, # 签发时间,带上时区的时间,否则会出现 The token is not yet valid (iat) "exp": now_utc + timedelta(hours=1), # 过期时间 } token = jwt.encode(payload, SECRET_KEY, algorithm="HS256") print(token) # eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJ1c2VyX2lkIjoxMjMsImV4cCI6MTc2MzQyNjIxOCwiaWF0IjoxNzYzNDIyNjE4fQ.fT_v9BxaDVyF-xP41t69ALz9xC6-lPCfL0sdoLo_UzA # 参数说明: payload:载荷,负载数据(字典) # 必要 SECRET_KEY:秘钥 # 必要 algorithm:算法(默认是HS256) HS256 # 默认,HMAC + SHA256 HS512 # HMAC + SHA512 RS256 # RSA + SHA256 ES256 # ECDSA + SHA256 # payload 载荷说明 payload = { # 注册声明(建议使用) 'iss': 'my-auth-server', # 签发者 (Issuer),防止别人伪造你系统的 Token 'sub': 'user-authentication', # 主题 (Subject),区分 Token 类型,例如 “用户认证 Token” 'aud': 'my-app', # 受众 (Audience),限制 Token 只能被某个客户端使用 'exp': datetime.utcnow() + timedelta(hours=1), # 过期时间 (Expiration Time),token什么时候过期 'nbf': datetime.utcnow(), # 生效时间 (Not Before),Token 什么时候开始有效(避免被提前使用) 'iat': datetime.utcnow(), # 签发时间 (Issued At),标记 Token 生成的时间 'jti': 'unique-token-id', # Token ID (JWT ID),用来做 “黑名单”、“撤销 Token” # 自定义声明,用户相关的数据 'user_id': 12345, 'username': 'john_doe', 'permissions': ['read', 'write'] }1-2.payload字段验证
字段 全名 用途 作用 是否自动验证 ississuer 签发者 防止别人伪造你系统的 Token 解密时手动指定参数指定(不会强制验证,就算设置了不指定也不会验证) subsubject Token 所表示的信息主题 区分 Token 类型,例如 “用户认证 Token” 需要手动验证(手动判断) audaudience 受众 限制 Token 只能被某个客户端使用 是(强制,如果有,需要解密时传递参数) expexpiration 过期时间 Token 什么时候失效 是(强制验证) nbfnot before 生效时间 Token 什么时候开始有效(避免被提前使用) 是(强制验证) iatissued at 签发时间 标记 Token 生成的时间 是(强制验证) jtiJWT ID Token 唯一 ID 用来做 “黑名单”、“撤销 Token” 用户的唯一表示符号(每次登录随机生成),自行记录。可以通过它进行黑名单或者说OSS单点登录设置。 # sub 通常来表示用途: "login" 登录 Token "refresh" 刷新 Token "email-verify" 邮箱验证 Token "reset-password" 重置密码 Token import jwt from datetime import datetime, timedelta, UTC SECRET_KEY = "my_secret_key" payload = { 'iss': 'my-auth-server', 'aud': 'my-app', 'exp': datetime.now(UTC) + timedelta(days=1), 'nbf': datetime.now(UTC), 'iat': datetime.now(UTC), 'user_id': '123', # 自定义字段 'jti': 'unique-token-id-12345', # 用户唯一标识符号,每次登录随机生成,可以是用户id 'sub': '用户认证 Token', } token = jwt.encode(payload, SECRET_KEY, algorithm="HS256") print("Token:", token) USER_JTI = {"123": "记录用户唯一标识jti,每次登录都会生成一个随机的"} # 单点登录记录(用户的id作为key),将 jti唯一标识 记录,如果登录了就记录。 TOKEN_BLACKLIST = [] # 黑名单一般使用缓存或者数据库记录 try: decoded = jwt.decode( token, SECRET_KEY, algorithms=["HS256"], audience="my-app", # 验证 aud (自动验证) issuer="my-auth-server", # 验证 iss(需要手动指定,不指定不验证,指定验证) ) # jti 参数实现黑名单 jti = decoded.get("jti") if jti in TOKEN_BLACKLIST: raise Exception("当前用户存在黑名单,Token 已被撤销") # jti 参数实现黑名单 user_id = decoded["user_id"] if USER_JTI.get(user_id) != decoded["jti"]: raise Exception("账号已在其他地方登录,当前 token 失效") if decoded.get("sub") != "用户认证 Token": # 需要进行手动验证 raise Exception("sub 不符合要求!") print("解码成功:", decoded) except jwt.ExpiredSignatureError as e: print("过期,超出了使用时间,设置exp") except jwt.ImmatureSignatureError as e: print("token未生效,设置nbf生效时间异常,iat签发时间异常") except jwt.InvalidAudienceError as e: print("token被限制,无法使用,设置了aud") except jwt.InvalidIssuerError as e: print("签发人或者系统不匹配,设置了iss") except jwt.InvalidSignatureError as e: print("其他的签名错误") except jwt.InvalidTokenError as e: print("token 无效,传递错误的token就会触发") except Exception as e: print("Token 错误:", e)1-3.解密校验JWT
import jwt SECRET_KEY = "my_secret_key" token="eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJ1c2VyX2lkIjoxMjMsImlhdCI6MTc2MzM5NDYwMywiZXhwIjoxNzYzMzk4MjAzfQ.7gnHMgpGMIMOEFxwG4gIEZACFs91j7i86geu9b0-1K8" try: decoded = jwt.decode(token, SECRET_KEY, algorithms=["HS256"]) print(decoded) # {'user_id': 123, 'iat': 1763394603, 'exp': 1763398203} except jwt.ExpiredSignatureError as e: print("Token 已过期!",e) except jwt.InvalidTokenError as e: print("Token 无效!",e)
1-1.案例(双 Token(Access + Refresh)机制)
- 一次登录生成2个token,一个是访问token(有效期短),一个是刷新token(时间长)。
- Refresh Token 未过期 → 生成新的 Access Token。
- Refresh Token 也过期 → 必须重新登录。
| Token | 用途 | 有效期 |
|---|---|---|
| Access Token | 调用接口、做权限认证 | 短期(2–4 小时、甚至 15 分钟) |
| Refresh Token | 用来换新的 Access Token | 长期(1~30 天) |
import jwt
from datetime import datetime, timedelta, timezone
from flask import Flask, request, jsonify
SECRET = "mysecret"
app = Flask(__name__)
def create_tokens(user_id):
# 访问token,时间短 30分钟
access_token = jwt.encode(
{
"uid": user_id,
"type": "access",
"exp": datetime.now(timezone.utc) + timedelta(minutes=30)
},
SECRET,
algorithm="HS256"
)
# 刷新token 时间长 7 天
refresh_token = jwt.encode(
{
"uid": user_id,
"type": "refresh",
"exp": datetime.now(timezone.utc) + timedelta(days=7)
},
SECRET,
algorithm="HS256"
)
return access_token, refresh_token
@app.route("/login", methods=["POST"])
def login():
data = request.json
username = data.get("username")
password = data.get("password")
if username == "admin" and password == "123":
access, refresh = create_tokens(user_id=1)
# return jsonify({"access_token": access, "refresh_token": refresh}) # 1.第一种方式将两个token都发给前端存储
resp = jsonify({"access_token": access})
# HttpOnly cookie 无法通过前端 document.cookie 因为设置 httponly=True
resp.set_cookie("refresh_token", refresh, httponly=True,
max_age=604800) # 2.将refresh_token发存到cookie中,前端只存储access_token,
return resp
return jsonify({"msg": "用户名或密码错误"}), 401
# 保护接口(只能用 access token 访问)
@app.route("/protected")
def protected():
auth = request.headers.get("Authorization")
if not auth:
return jsonify({"msg": "缺少 Authorization 头"}), 401
token = auth.split(" ")[1] # Bearer access_token
try:
payload = jwt.decode(token, SECRET, algorithms=["HS256"])
if payload.get("type") != "access":
return jsonify({"msg": "请使用 Access Token"}), 403
return jsonify({"msg": "访问成功!", "uid": payload["uid"]})
except jwt.ExpiredSignatureError:
return jsonify({"msg": "Access Token 已过期"}), 401
except Exception:
return jsonify({"msg": "Token 无效"}), 401
# 刷新接口(用 refresh token 换新的 access token)
@app.route("/refresh", methods=["POST"])
def refresh():
data = request.json
refresh_token = data.get("refresh_token") # 1.访问接口这个接口是携带这个token值
refresh_token = request.cookies.get("refresh_token") # 2.存储到cookies中这样取值
try:
payload = jwt.decode(refresh_token, SECRET, algorithms=["HS256"])
if payload.get("type") != "refresh":
return jsonify({"msg": "必须使用 Refresh Token"}), 403
# 生成新的 access token
new_access_token = jwt.encode(
{
"uid": payload["uid"],
"type": "access",
"exp": datetime.now(timezone.utc) + timedelta(minutes=30)
},
SECRET,
algorithm="HS256"
)
return jsonify({"access_token": new_access_token})
except jwt.ExpiredSignatureError:
return jsonify({"msg": "Refresh Token 已过期,请重新登录"}), 401
except Exception:
return jsonify({"msg": "Refresh Token 无效"}), 401
if __name__ == "__main__":
app.run(debug=True)
1-2.案例(双Token的前端部分)
let isRefreshing = false; # 锁
let queue = [];
axios.interceptors.response.use(null, async error => {
const originalRequest = error.config;
// 如果 token 过期
if (error.response.status === 401) {
// 1.如果已经在刷新,当前请求加入队列
if (isRefreshing) {
return new Promise(resolve => {
queue.push(() => resolve(axios(originalRequest)));
});
}
// 2. 设置请求锁
isRefreshing = true;
try {
// 3.更新 Token
const res = await axios.post('/refresh');
const newToken = res.data.access_token;
setToken(newToken); # 将新的token设置到请求头中
// 4.执行队列中所有请求
queue.forEach(cb => cb());
queue = [];
// 因为第一次(发现token过期了)不会存储到queue内,而是返回一个axios(originalRequest)执行重洗发送请求
// originalRequest第一次请求时请求的配置信息
return axios(originalRequest);
} catch (err) {
// refresh 也过期 → 退出登录
logout();
return Promise.reject(err);
} finally {
isRefreshing = false;
}
}
return Promise.reject(error);
});
# 流程说明:
第一次请求:
isRefreshing = false → 不走队列
发起刷新 token
刷新成功后 return axios(originalRequest) → 原请求重新发一次
后续请求(刷新期间又返回 401):
isRefreshing = true → 挂起队列 queue.push(...)
等刷新成功后通过 queue.forEach(cb => cb()) 执行
队列作用:
保证在刷新 token 期间不会重复刷新
等刷新完成再重试这些请求
最终效果:
用户发起多个请求时,token 过期也不会丢数据
所有请求都会自动用新的 access token 重试
2.moviepy模块
作用:
- 非常强大的 视频编辑库。它能用来 生成、剪辑、合成、处理视频和音频,并且可以直接用 Python 代码操作,非常适合自动化视频处理、视频生成脚本、视频特效制作等场景。
pip install moviepy # 安装
# <=1.0 版本的导入方式
from moviepy.editor import VideoFileClip, concatenate_videoclips
# 新版本的导入方式
from moviepy.video.io.VideoFileClip import VideoFileClip # 读取视频
from moviepy import concatenate_videoclips # 视频拼接
# ========== 1. 读取视频 ==========
clip = VideoFileClip("input.mp4") # 加载视频文件
print(clip.duration) # 视频时长(秒)
print(clip.fps) # 帧率
print(clip.size) # 视频尺寸 (宽, 高)
# ========== 2. 剪辑视频 ==========
subclip = clip.subclipped(10, 20) # 截取 10~20 秒的视频片段 <=1.0 版本 clip.subclip(10, 20)
subclip.write_videofile("output.mp4") # 保存视频
# ========== 3. 拼接视频 ==========
clip1 = VideoFileClip("clip1.mp4")
clip2 = VideoFileClip("clip2.mp4")
final_clip = concatenate_videoclips([clip1, clip2]) # 拼接视频
final_clip.write_videofile("merged.mp4")
# 等等其他功能