Ansbile
人工运维时代:
- 运维人员大多需要维护数量众多的机器,反复重复的劳动力,很多机器需要同时部署相同的服务或是执行命令,还得反复登录不同的机器执行。
- 例如在backup服务器上部署Rsync服务,需要在所有其他的服务器上部署Rsync客户端配置一遍。
- 一台台机器登录执行命令实在太繁琐,运维人员也常用Xshell、SecureCRT之类的工具添加多个服务器的标签,提高快速连接服务器的效率
自动化运维时代:
- SSH自动化运维时代是指2003~2012年,当时SSH自动化运维是很流行的,通过再管理机器统一创建秘钥对,将私钥留在管理机上,公钥发到所有被管理的机器,然后开发脚本实现批量管理。
- 系统管理员日常会进行大量的重复性操作,例如安装软件,修改配置文件,创建用户,批量执行命令等等。如果主机数量庞大,单靠人工维护实在让人难以忍受。早期运维人员会根据自己的生产环境来写特定脚本完成大量重复性工作,这些脚本复杂且难以维护。
- 面临的问题:
- 系统配置管理。
- 远程执行命令,因此诞生了很多开源软件,系统维护方面有fabric、puppet、chef、ansible、saltstack等,这些软件擅长维护系统状态或方便的对大量主机进行批量的命令执行。
自动化运维的好处:
- 提高工作效率,大大减少人为的出错,数据化管理,数据化汇报,问题可追溯。
ansible文档地址:
ansible是什么:
- Ansible是一个同时管理多个远程主机的软件(任何可以通过SSH协议登录的机器),因此Ansible可以管理远程虚拟机、物理机,也可以是本地主机(linux、windows)。
- Ansible通过SSH协议实现管理节点、远程节点的通信。
- 只要是能够SSH登录的主机完成的操作,都可以通Ansible自动化操作,比如批量复制、批量删除、批量修改、批量查看、批量安装、重启、更新等。
- ansible是通过ssh协议进行操作的。
- 主要的作用就是远程的控制1台主机或者多台主机。
1.ansible安装部署与配置
1-1.安装
1.安装:
yum install epel-release ansible libselinux-python -y
2.查看版本,版本信息解读
ansible --version
[root@test-1 ~]# ansible --version
ansible 2.9.27
config file = /etc/ansible/ansible.cfg # 配置文件
configured module search path = [u'/root/.ansible/plugins/modules', u'/usr/share/ansible/plugins/modules'] # 模块目录
ansible python module location = /usr/lib/python2.7/site-packages/ansible # 使用的python模块
executable location = /usr/bin/ansible # 命令路径
python version = 2.7.5 (default, Nov 14 2023, 16:14:06) [GCC 4.8.5 20150623 (Red Hat 4.8.5-44)] # python版本
1-2.ansible配置
# 1.主要的配置就是主机清单:
文档:https://docs.ansible.com/ansible/latest/inventory_guide/intro_inventory.html
是用于定义被管理主机及其分组信息的文件,它告诉 Ansible 哪些主机需要进行管理和配置
主机清单的默认配置文件:/etc/ansible/hosts # 注意有时候需要自行闯进啊
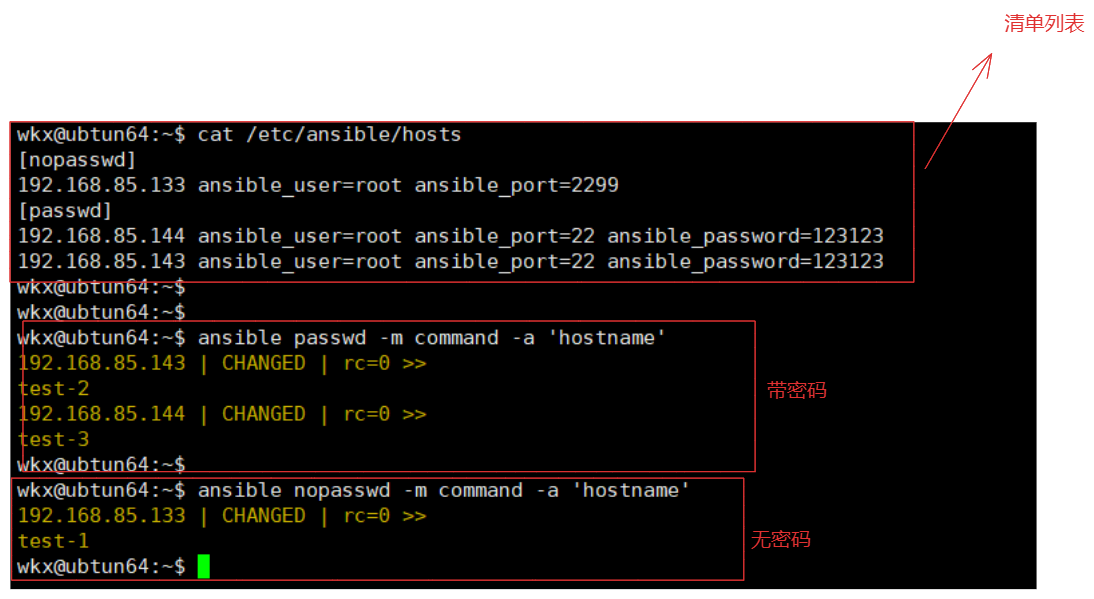
# 2.主机认证
由于ansible是通过ssh协议进行操作的,所以需要管理主机需要进行配置 密码或者秘钥。
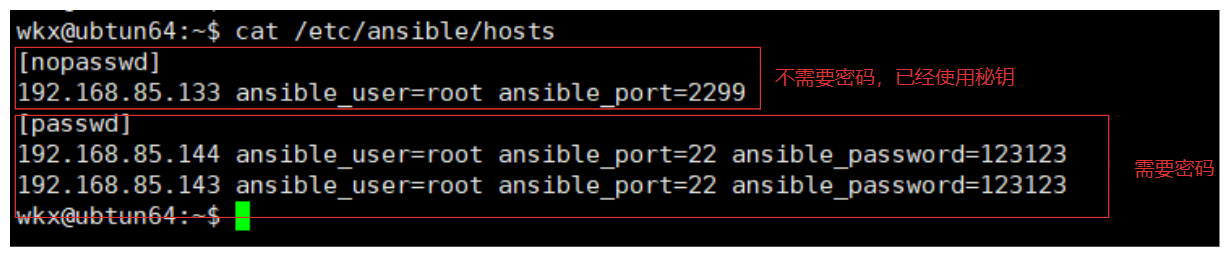
1.在主机清单中配置密码。
2.使用秘钥(免密操作)进行配置,只需要在主机清单中配置主机的ip即可。
1-2-1.主机清单参数
| 参数 | 参数类型 | 参数说明 |
|---|---|---|
| ansible_host | 主机地址 | 远程主机ip |
| ansible_port | 主机端口 | 设置SSH连接端口,默认22 |
| ansible_user | 主机用户 | 默认SSH远程连接的用户身份 |
| ansible_password | 用户密码 | 指定SSH远程主机密码 |
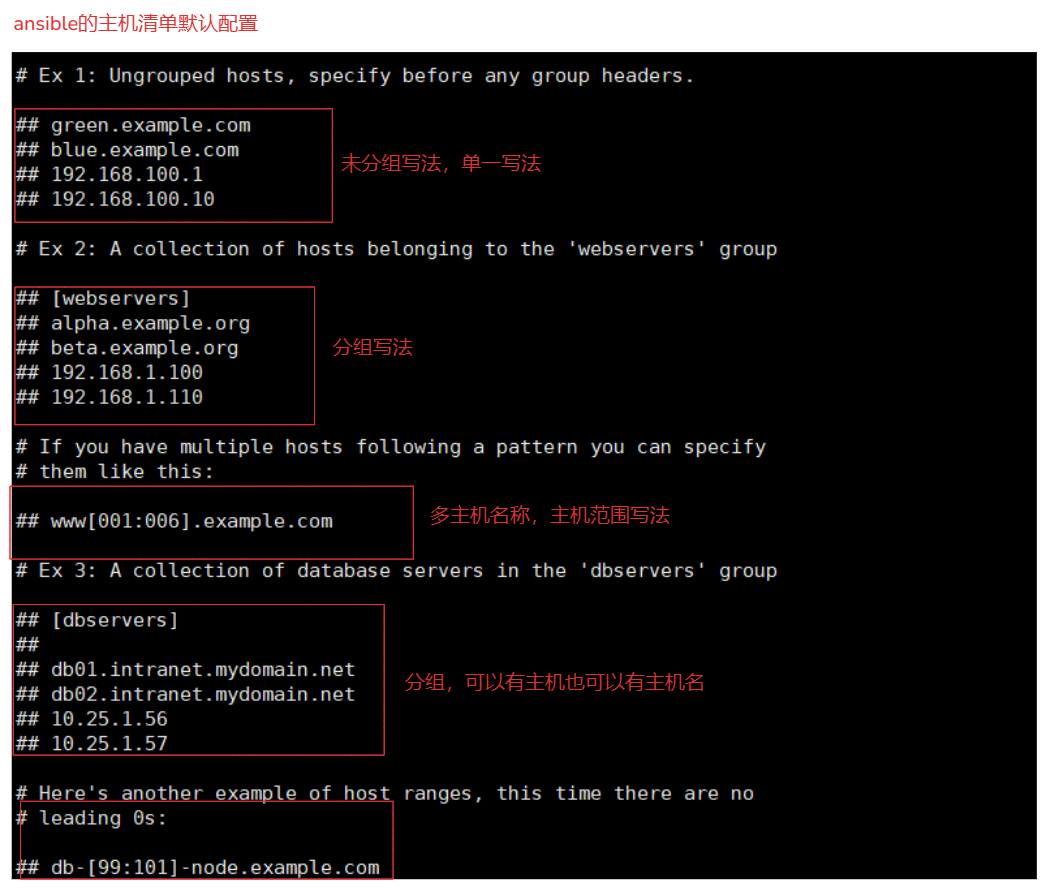
1-2-2.主机清单配置的语法
# 语法:
ip 参数1='' 参数2='' 参数3= '' ..
1.单一条:
172.16.1.41 ansible_port=22999 ansible_user=root ansible_password=123123 # 使用ip地址
alpha.example.org ansible_port=22999 ansible_user=root ansible_password=123123 # 使用主机名称
2.分组写法
# 等同于将下面的机器分到web组中,ansible直接调用web组就可以对这三台机器进行操作
[web]
123.123.123.1 ansible_port=22999 ansible_user=root ansible_password=123123
123.123.123.2 ansible_port=22999 ansible_user=root ansible_password=123123
123.123.123.3 ansible_port=22999 ansible_user=root ansible_password=123123
3.分组优化写法
# 利用[]可以设置主机ip的范围
[web]
123.123.123.[1:3] ansible_port=22999 ansible_user=root ansible_password=123123
4.使用公共变量
[web:vars] # 这是web分组公共变量
ansible_port=22999
ansible_user=root
ansible_password='123123'
[web] # 这个组内的的主机就会使用公共的变量
123.123.123.[1:3]
# 注意:
如果使用的ssh面密操作,就可以省区 ansible_password 参数,不指定密码。
1-2-3.主机认证方式
ansible基于ssh协议进行,只有秘钥与密码两种方式,其他没有。
1.密码
2.秘钥
1.使用密码
123.123.123.1 ansible_port=22999 ansible_user=root ansible_password=123123
2.使用秘钥流程
1.生成秘钥
ssh-keygen
2.发送秘钥
ssh-copy-id 123.123.123.1
3.主机清单中配置
123.123.123.1 ansible_port=22999 ansible_user=root ansible_password=123123
# 注意:
第一次机器与机器之间进行连接时,会出现指纹认证操作。使用ansible就会报错。
解决:
1.修改ansible配置文件,不需要指纹认证。
2.先ssh链接主机清单内的主机(先手动操作进行指纹认证)
1-2-4.一键公钥分发脚本
1.需要安装 sshpass
yum install -y sshpass
2.脚本如下
echo "正在分发公钥中...分发的机器列表是{7,31,41}"
for ip in {7,31,41} # ip地址列表
do
# StrictHostKeyChecking=no 不需要指纹认证
sshpass -p '123123' ssh-copy-id 172.16.1.${ip} -o StrictHostKeyChecking=no > /tmp/create_ssh.log 2>&1
echo "正在验证免密登录结果中...."
echo "远程获取到主机名: $(ssh 172.16.1.${ip} hostname)"
done
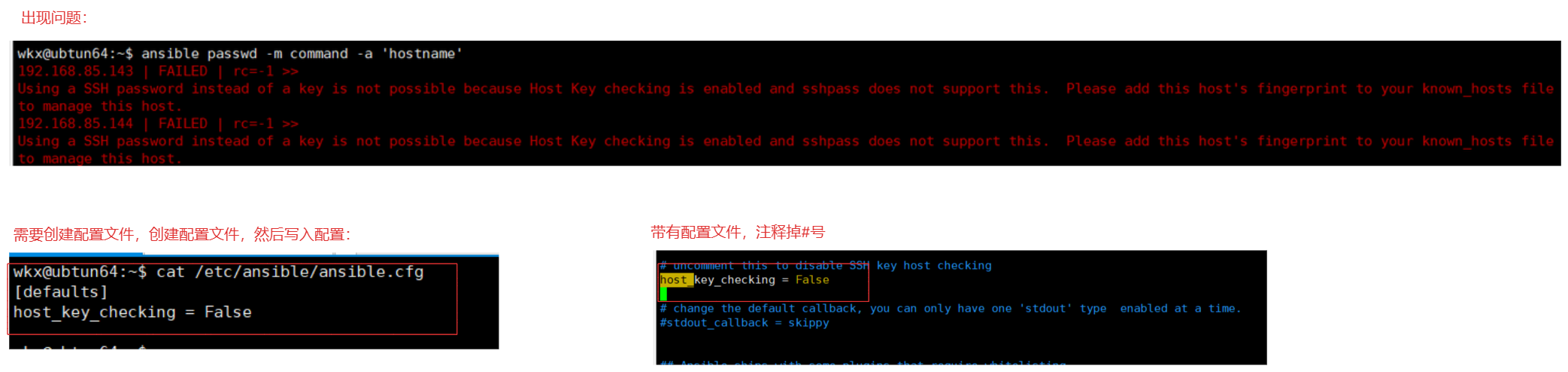
1-2-5.首次连接问题
# 问题:ansible的链接是基于ssh,使用的ssh原理
首次使用ansible进行新机器访问时,会出现需要指纹认证的操作
报错信息:# 第一次进行连接时(密码操作)需要主机的指纹进行验证
Using a SSH password instead of a key is not possible because Host Key checking is enabled and sshpass does not support this. Please add this host's fingerprint to your known_hosts file to manage this host.
解决方式如下:
1.请将此主机清单内的机器的指纹添加到宿主机known_hosts文件中以管理此主机(手动复制)
cat ~/.ssh/known_hosts
2.在宿主机中进行连接一次主机清单内的机器
ssh root@ip
3.修改ansible中配置,不进行指纹认证
vim /etc/ansible/ansible.cfg # 注意如果没有这配置文件,就需要创建
[defaults] # 没有添加头部
host_key_checking = False # 有取消取消注释 默认就是取消指纹认证
1-3.初始化方案操作
由于ansible时基于ssh进行登录认证的,要注意指纹确认
1.使用公钥分发的方式,写一个脚本进行公私钥一键分发
2.可以手动连接ssh,进行确认指纹,在使用ansible进行免密远程执行命令
3.直接在配置文件中修改忽略指纹认证参数即可
host_key_checking = False
非常常见错误:
端口错误
密码错误
用户错误
1-4.测试
2.ansible的命令执行结果
| 颜色 | 说明 |
|---|---|
| 绿色 | 命令以用户期望的执行了,但是状态没有发生改变; |
| 黄色 | 命令以用户期望的执行了,并且状态发生了改变; |
| 紫色 | 警告信息,说明ansible提示你有更合适的用法; |
| 红色 | 命令错误,执行失败; |
| 蓝色 | 详细的执行过程; |
# 注意:
ansible命令:
会对命令进行记录,如果执行过了,就不会在执行。
shell脚本:
只要执行了脚本,就会再次执行操作,执行100遍安装,那么就会安装100次,不会对命令进行记录,就会反复执行。
3.ansible命令参数
命令:
ansible
使用:
ansible <主机ip/主机清单分组名称> <参数>
参数:
-i <路径> 指定主机清单路径
-m <模块名称> 指定模块名称 # 常用
-a <参数> 传递模块需要的参数 # 常用
--list-hosts 列出主机模式的主机
-u <用户名称> 指定远程主机的用户名
--ask-pass 提示输出远程主机的密码
--become 提权
-vvvv 输出调试
--timeout 30 默认30秒,ssh超时时间
--forks 5 默认5,指定并发的数量
例如:
ansible all -m command -a "hostname"
解释:
all:代表全部的主机(主机清单中),也可以指定单一的主机ip或者主机名称,或者分组名称。
-m command :指定的模块是command
-a "hostname" :模块的参数(命令)
4.ansible常用模块
**文档:**https://docs.ansible.com/ansible/latest/collections/index.html
- 版本不同,可能导致参数或者模块被弃用,按照文档为主。
4-1.setup模块
作用:
获取远程的主机的系统信息,返回的数据是json格式,可以使用jq进行处理
sudo apt install jq
yum install jq -y
模块:
ansible all -m setup
参数:
-a 'filter=' # 过滤信息
ansible all -m setup -a "filter=ansible_all_ipv4_addresses"
# 例如:只收集ansible_all_ipv4_addresses的相关信息
ansible nopasswd -m setup -a "filter=ansible_all_ipv4_addresses"
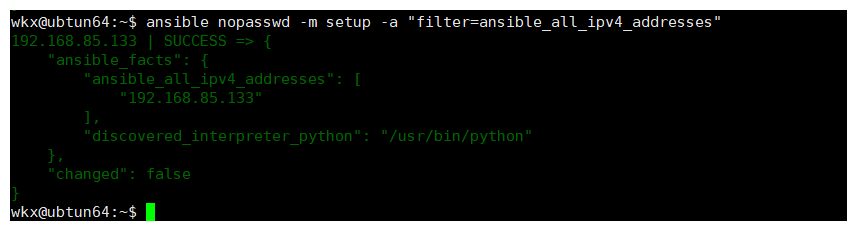
4-2.ping模块
作用:
用于测试目标主机是否可以正常响应 Ansible 的请求。
1.测试连接:ping 模块用于测试 Ansible 是否能够成功连接到目标主机,并执行基本任务。
2.检查配置:它可以帮助你验证主机清单、SSH 配置、权限等是否正确。
3.简单的健康检查:快速确认目标主机是否处于可管理状态。
模块
ansible all -m ping
4-3.command模块
作用:
属于命令模块,可以指定命令进行操作
注意:
不支持执行变量和特殊符号例如:${HOME} < > | & ...
模块:
ansible all -m command -a 'hostname'
ansible all -m command -a 'netstat -tunlp | grep 80' # -a 参数中不能存在特殊符号

4-3-1.参数
- 这些命令用于编写ansible-playbook,完成服务器部署的各种复杂条件限定。
| 选项参数 | 选项说明 |
|---|---|
| chdir | 在执行命令执行,通过cd命令进入指定目录 |
| creates | 定义一个文件是否存在,若不存在,则运行相应命令;存在则跳过 |
| free_form(必须) | 参数信息中可以输入任何系统命令,实现远程管理 |
| removes | 定义一个文件是否存在,如果存在,则运行相应命令;如果不存在则跳过 |
1.例如:chdir
chdir=/ :在 命令执行前会cd到根目录
ansible nopasswd -m command -a "tar -czf /opt/log.tar.gz /var/log chdir=/"
2.例如:removes
removes=/nginx: nginx文件存在执行命令,不存在不执行
ansible nopasswd -m command -a 'tar -czf /nginx/log.tar.gz var/log chdir=/ removes=/nginx'
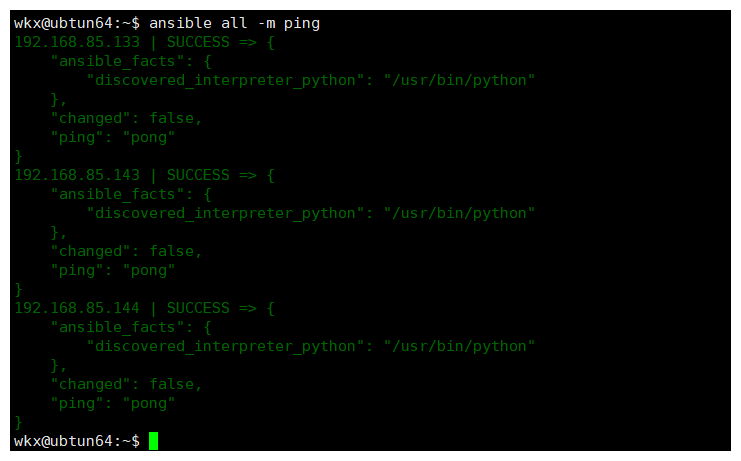
4-4.模块出现警告
# 为什么会出现警告:
Ansible 建议在执行某些操作时使用更专门的模块
例如:
ansible 192.168.85.144 -m command -a 'touch /opt/123.log'
解决警告的问题:
1.使用参数避免警告 加入:warn=false
ansible 192.168.85.144 -m command -a 'touch /opt/456.log warn=false'
2.在配置文件中 ansible.cfg 修改配置
command_warnings= false
3.使用专门的模块 # file模块专门创建文件
ansible 192.168.85.144 -m file -a "path=/opt/789.log state=touch"
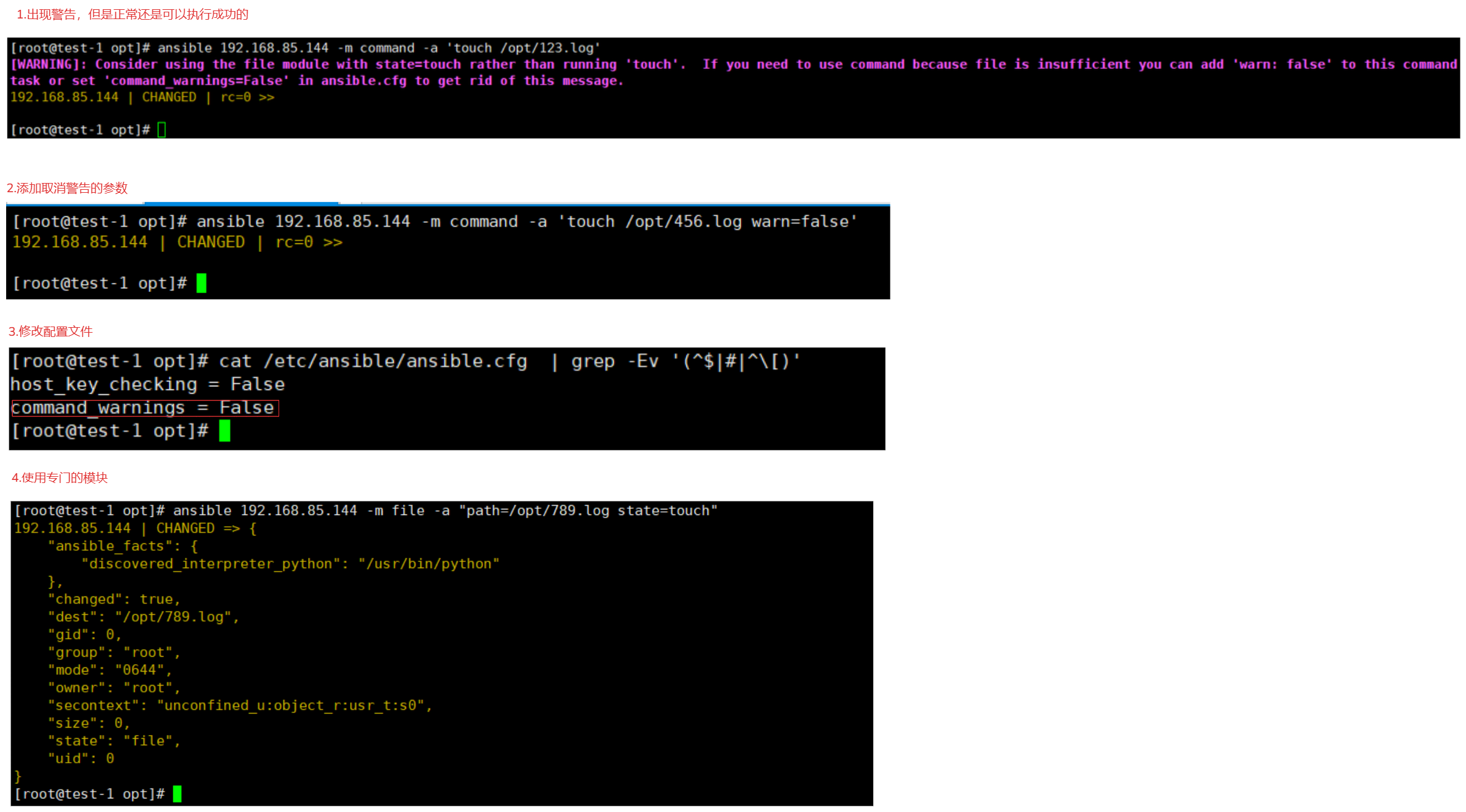
4-5.shell模块
作用:
在远程节点上执行命令(复杂的命令)万能模块,类似远程执行shell脚本一样,这个模块大部分都可以使用,相当于远程执行某些命令,但是每个对应的操作都有对应的模块,shell命令别过度依赖,那就等于用ansible远程帮你执行了个普通的shell命令;
使用:
ansible all -m 'shell' -a 'netstat -tunlp | grep 111' # 允许使用特殊符号的
执行复杂的指令:
ansible all -m 'shell' -a 'mkdir /opt/test && echo "hostname" > /opt/test/1.sh && chmod +x /opt/test/1.sh && /opt/test/1.sh'
# 注意:
它与command差不多,但是不点在于command不能包含特殊符号。
而shell可以,同等于在一个bash解释器执行一样。
4-6.copy模块
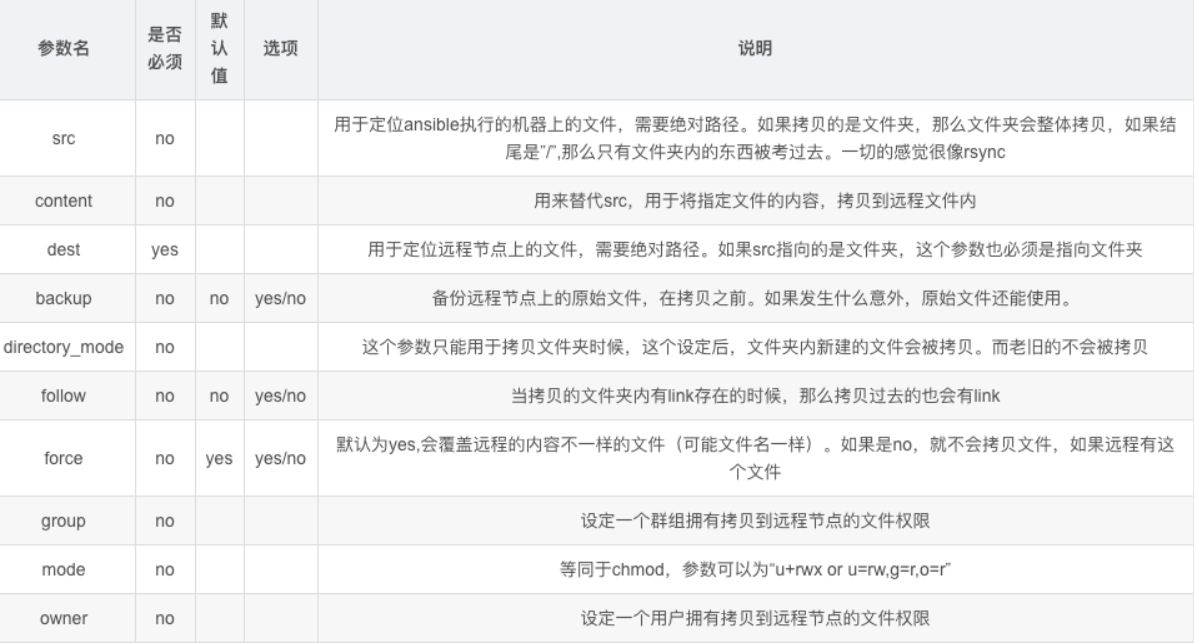
| 参数 | 说明 |
|---|---|
| src | 宿主机的文件绝对路径。 |
| dest | 远程机器的绝对路径。 |
| group | 设置属组 |
| owner | 设置属主 |
| mode | 设置文件权限 mode=777 或者 mode=u+rwx 或者u=rw,g=r,o=r。 |
| backup | yes 同意对远程的原文件进行备份,保留内容。解释:如果本地主机向远程主机复制一份123.log文件,而远程主机存在这个123.log文件,那么当 backup=yes是就将远程主机存在的文件备份,防止远程主机的文件覆盖。 |
| content | content='asdasdsa' 将内容写入到远程文件中,并覆盖内容,代替src |
作用:
类似于 scp或者rsync差不多,将宿主机的文件发送到远程主机。
copy模块是远程推送数据模块,只能把数据推送给远程主机节点,无法拉取数据到本地。既然是文件拷贝,可用参数也就是围绕文件属性。批量操作模块。
语法:
ansible all -m copy -a '需要的参数'
# 注意:
将管理机器上的数据推送给远程主机,前提ansible中得/etc/ansible/hosts 中有远程主机的信息才可以操作。
只有文件的md5值发送变化才会执行,未变化不做处理。
# 例如:将管理机的/etc/host文件发送到每个节点的远程主机
ansible all -m copy -a 'src=/etc/hosts dest=/etc/hosts backup=yes'
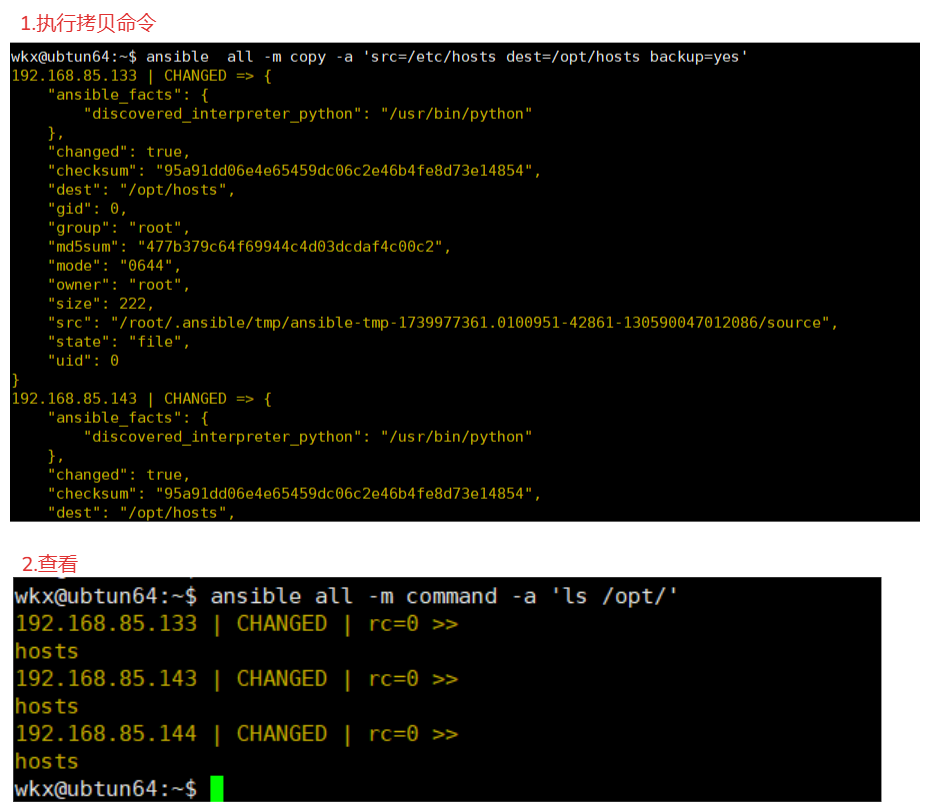
4-6-1.参数-属主属组权限
例如:指定属主属组,访问权限
ansible all -m copy -a 'src=/etc/hosts dest=/opt/hosts group=www owner=www mode=600'
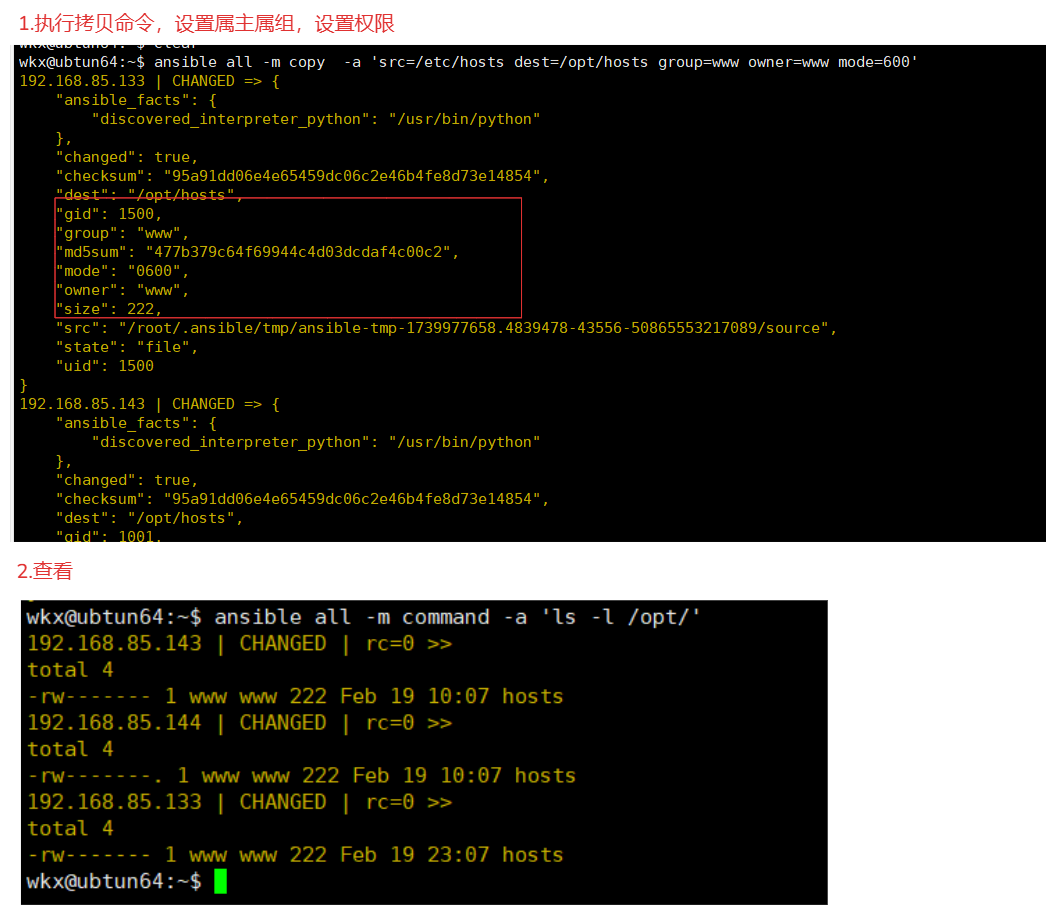
4-6-2.参数-写入参数
例如:写入aaa到远程/opt/123.log文件中
ansible all -m copy -a 'content="aaa" dest=/opt/123.log'
# 注意:
如果使用content参数的情况下可以不使用stc参数,因为content是向dest写入内容,可以理解为 在远程指定 echo 'aaa' > /opt/123.log
src 与 content是冲突的,src是本地主机的内容复制到运城主机,content是直接编辑文件,而不需要创建本地文件。
4-7.file模块
作用:
创建文件文件夹,设置文件属性,在远程主机上修改属性,关于文件的全部操作,权限设置,属性修改,创建 删除等操作。
同等于 touch 命令 + chmod命令 + chown命令,可以设置属主属组,以及权限。
使用
ansible all -m file -a '参数命令'
4-7-1.参数
| 参数 | 说明 |
|---|---|
| path | 必须参数,用于指定远程节点要操作的文件或目录。 |
| state | 用于指定是创建文件还是文件夹。 state=directory 创建文件夹 state=hard 创建硬链接 state=link 创建软连接 state=touch 创建文件 |
| owner | 指定文件的属主。 |
| group | 指定文件的属组。 |
| mode | 指定文件的权限。mode=777 或者 mode=u+rwx 或者u=rw,g=r,o=r |
| src | 只有在 state=hard 或者 state=link的时候才有作用,需要指定软连接与硬链接指定到那个文件或目录。 |
| force | state=link的时候,可配合此参数强制创建链接文件,当force=yes时,表示强制创建链接文件,不过强制创建链接文件分为两种情况。1.当你要创建的链接文件指向的源文件并不存在时,使用此参数,可以先强制创建出链接文件。2.当你要创建链接文件的目录中已经存在与链接文件同名的文件时,将force设置为yes,回将同名文件覆盖为链接文件,相当于删除同名文件,创建链接文件。3.当你要创建链接文件的目录中已经存在与链接文件同名的文件,并且链接文件指向的源文件也不存在,这时会强制替换同名文件为链接文件。 |
| recurse | 当要操作的文件为目录,将recurse设置为yes,可以递归的修改目录中文件的属性。 |
4-7-2.案例一
1.创建文件
ansible all -m file -a 'path=/opt/123.log state=touch'
2.创建文件夹
ansible all -m file -a 'path=/opt/456 state=directory'
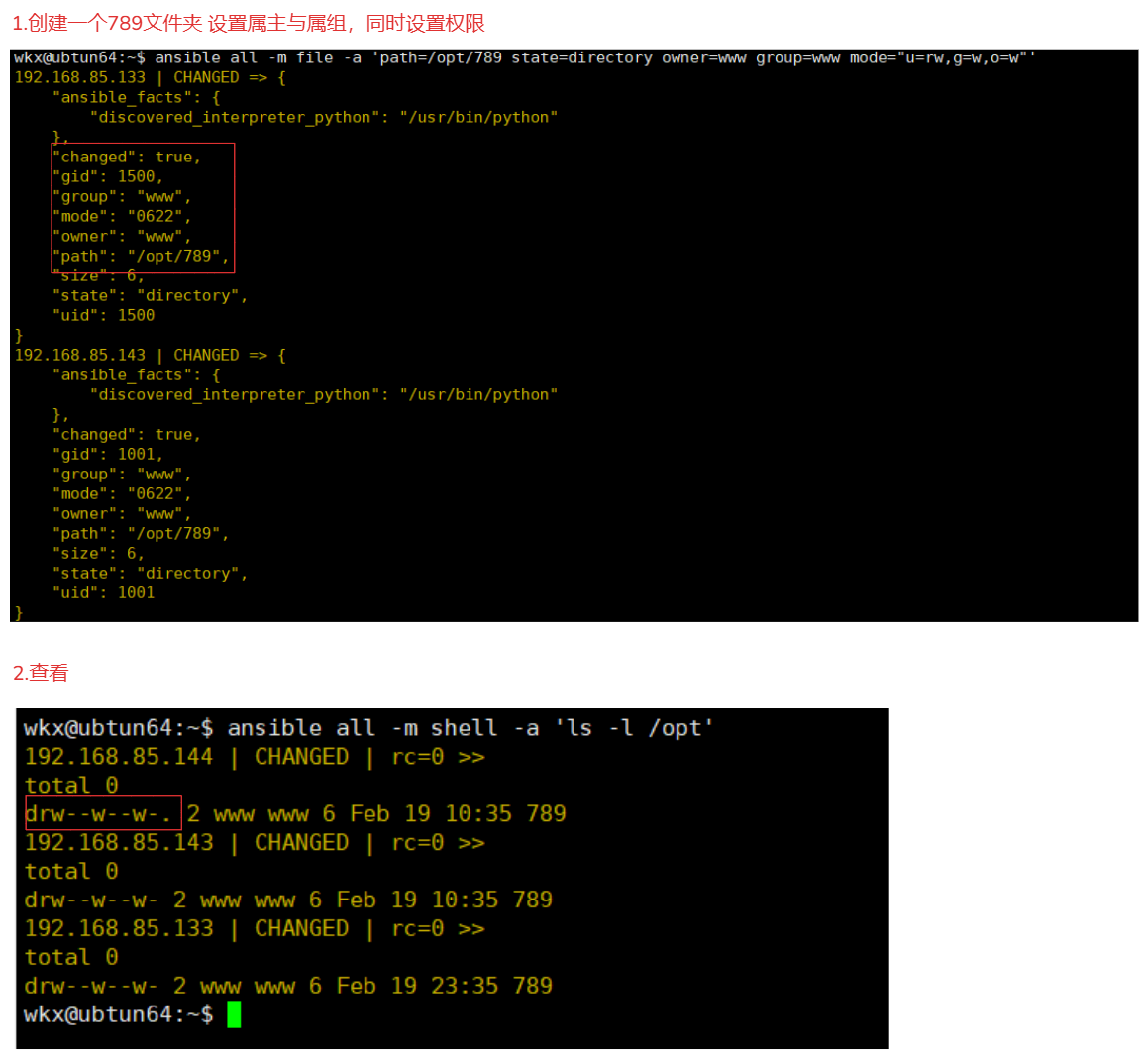
3.创建文件并使用设置权限参数
ansible all -m file -a 'path=/opt/789 state=directory owner=www group=www mode="u=rw,g=w,o=w"' # 符号指定
ansible all -m file -a 'path=/opt/789 state=directory owner=www group=www mode=622' # 10进制
mode="u=rw,g=w,o=w":不使用10进制数字可以使用这种方式指定权限
4-7-3.案例二
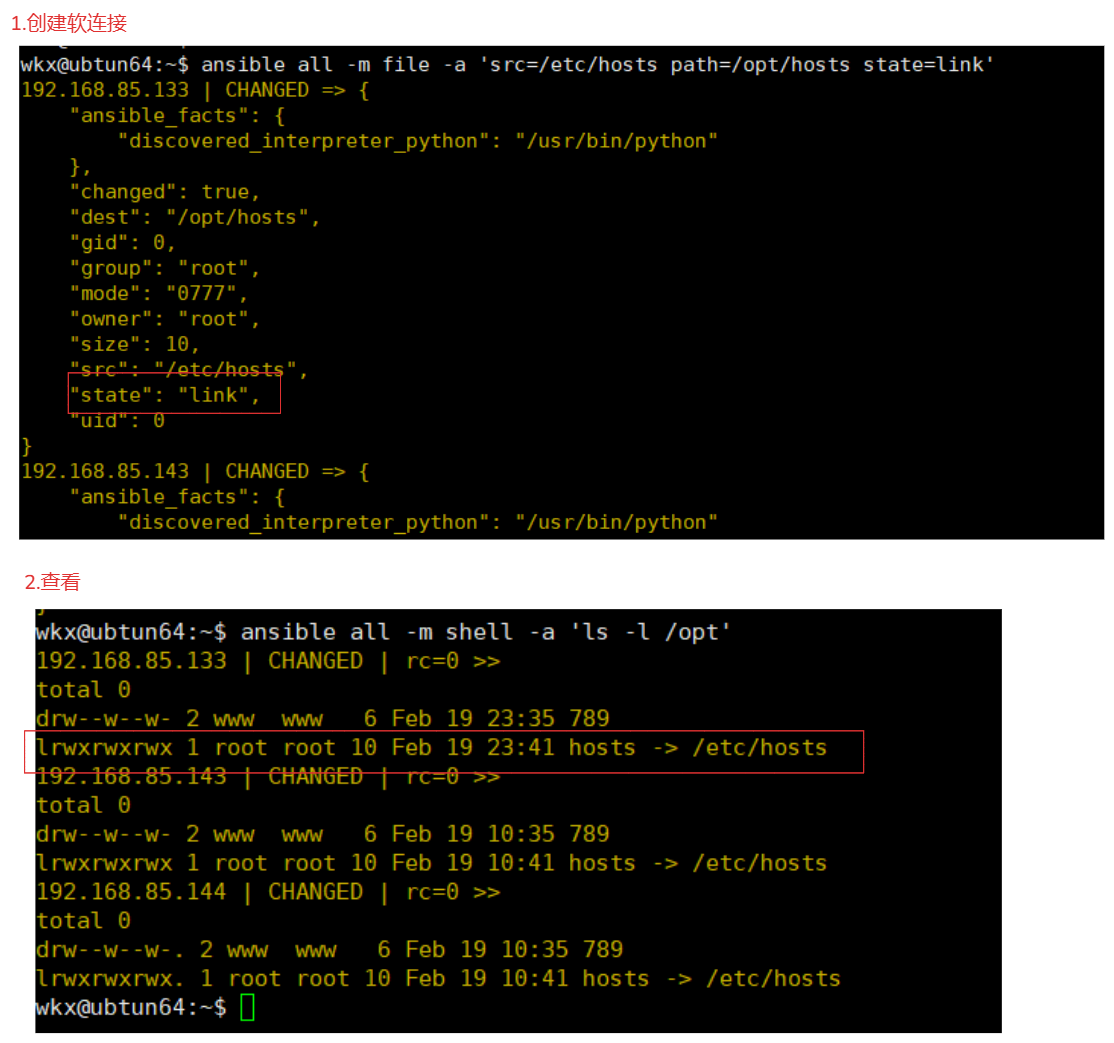
# 在创建软连接或者硬链接时
state=link 或者 state=hard 需要使用src
src参数作用:src代表的是远程主机的某个文件或者文件夹的路径。
path参数作用:path代表需要创建软连接或者硬连接的路径。
1.创建软连接
ansible all -m file -a 'src=/etc/hosts path=/opt/hosts state=link'
4-7-4.不存在软连接
# 场景:
如果软连接指向的文件不存在了,就需要使用force参数强制创建软连接管理。
在目标机器上,指定源文件,创建软连接
参数:
src 参数 : 指定原文件,远程主机文件绝对路径
path 参数 :指定远程主机的,存放的目标绝对路径
state 参数:设置文件的属性(软连接 硬链接 文件 文件夹 等)
force 参数:强制参数
state=link # 创建软连接
force=yes # 强制创建文件(软连接)
命令:
ansible web -m file -a 'src=/etc/hostssss path=/opt/hostssss state=link force=yes'

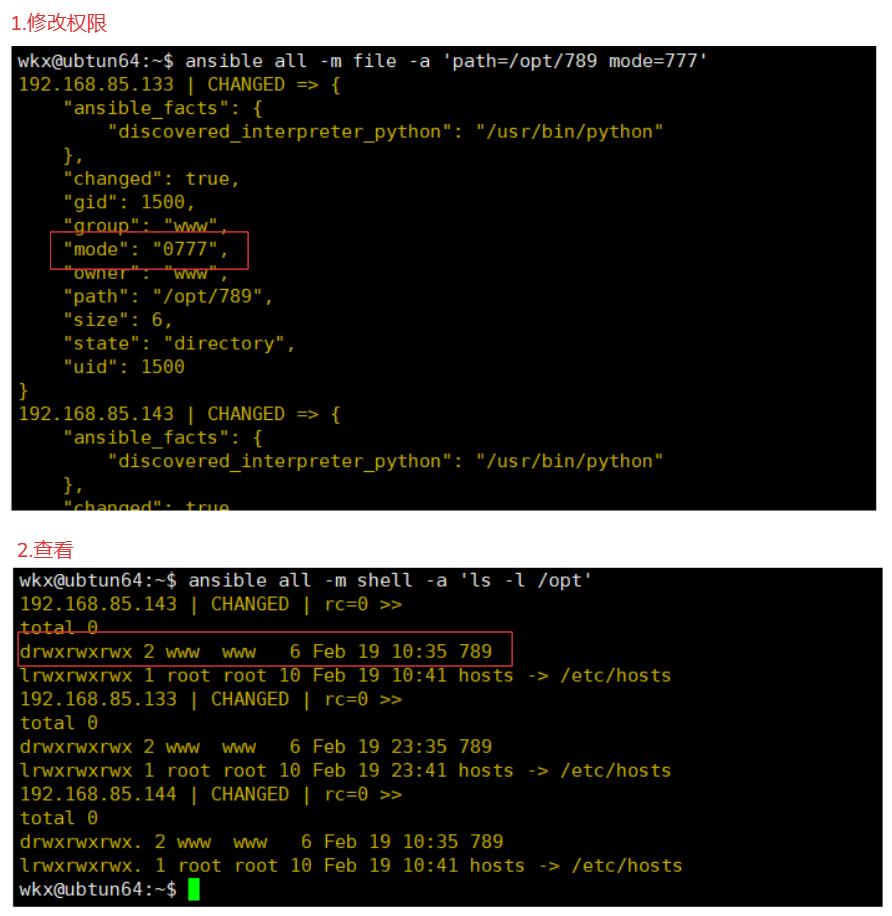
4-7-5.对文件修改权限
场景:
如果只是单纯的修改一个文件或者文件夹的权限,就可以使用当前方式,只需要指定:
path参数:远程主机的文件路径
mode参数:权限
命令:
ansible all -m file -a 'path=/opt/789 mode=777'
4-8.scrip模块
作用:
可以执行脚本,在本地的脚本可以在远程节点机器上运行。
shell脚本在本地,远程节点不需要这脚本也可以直接运行。
# 远程执行脚本
使用:
ansible all -m scrip -a '脚本参数'
4-8-1.参数
| 参数名称 | 描述 |
|---|---|
cmd 或 free_form |
指定本地脚本的路径,可选地附加空格分隔的参数。 |
chdir |
在远程节点上执行脚本之前,切换到此目录。 |
creates |
如果远程节点上存在指定的文件,则不会运行该脚本。 |
removes |
如果远程节点上不存在指定的文件,则不会运行该脚本。 |
executable |
指定用于运行脚本的可执行文件路径或名称。 |
decrypt |
控制是否自动解密源文件(默认为 true) |
4-8-2.案例
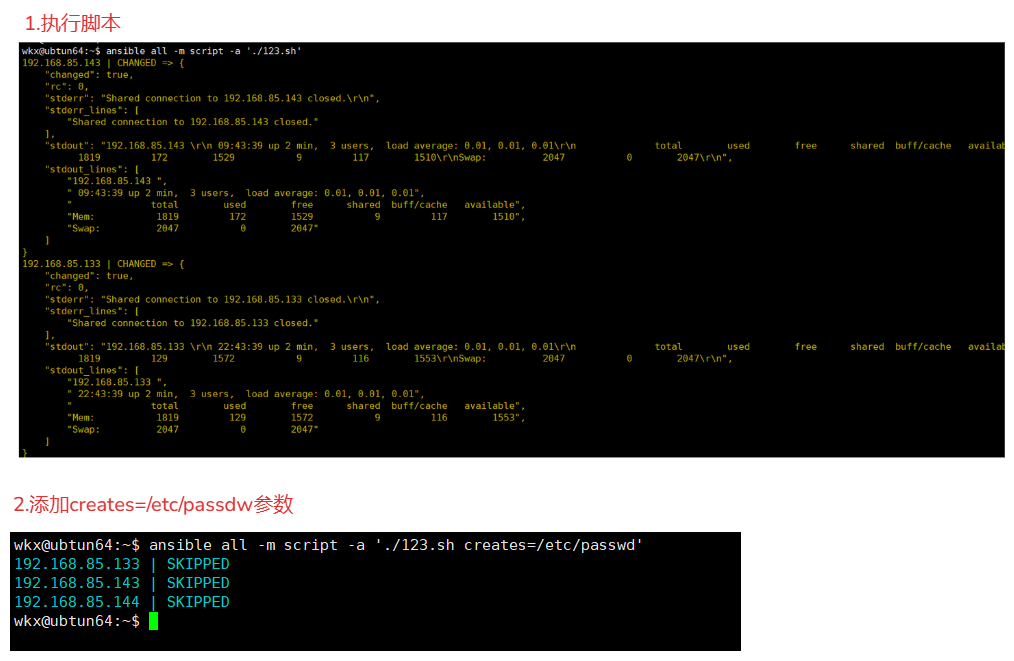
1.编写一个脚本(本地机器,宿主机)
vim 123.sh
#!/bin/bash
echo "$(hostname -I)" >> /tmp/server_info.log
echo "$(uptime)" >> /tmp/server_info.log
echo "$(free -m)" >> /tmp/server_info.log
cat /tmp/server_info.log
2.设置执行权限 # 也可以不设置执行权限,也可以执行
chmod +x 123.sh
3.执行命令
ansible all -m script -a './123.sh'
4.使用参数执行命令
ansible all -m script -a './123.sh creates=/etc/passwd'
creates=/etc/passwd :远程节点机器上必须有 /etc/passwd 就不会执行 ./123.sh脚本
4-9.cron模块
作用:
可以对远程的节点机器操作它们的定时器。就是用来管理管理 cron 作业(定时任务)
使用:
ansible all -m cron -a '参数'
4-9-1.参数
| 参数 | 说明 |
|---|---|
| name | 任务的描述性名称,用于唯一标识一个 cron 作业 |
| minute | 任务应该在分钟(0-59)执行。默认是* |
| hour | 任务应该在小时(0-23)执行。默认是* |
| day | 任务应该在一个月中的哪一天执行(1-31)。默认是* |
| month | 任务应该在哪个月执行(1-12,其中1代表一月)。默认是* |
| weekday | 任务应该在星期几执行(0-7,其中0和7都代表星期天)。默认是* |
| job | 要执行的命令或脚本。 |
| user | 指定 cron 作业运行的用户。 |
| state | 定义任务的状态,可以是 present(确保任务存在,如果不存在创建,如果存在无动作)或 absent(确保任务不存在,如果存在删除,不存在不做动作)。 |
| env | 定义一组环境变量,这些变量将在执行命令之前设置。 |
| replace | 如果设置为 no,则模块不会替换现有的 cron 作业,即使 name 相同。默认为 yes。 |
# 这些参数本质上与cron原始操作是相同的。
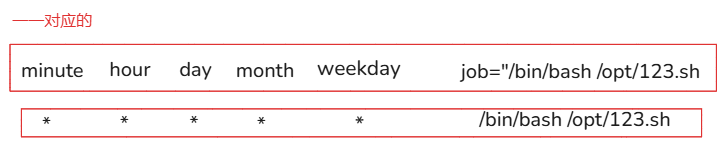
例如:
0 * * * * /bin/bash /opt/123.sh # 在每个小时的整点执行 123.sh
使用cron模块表示
ansible all -m cron -a 'minut=0 job="/bin/bash /opt/123.sh"'
minute hour day month weekday job="/bin/bash /opt/123.sh"
* * * * * /bin/bash /opt/123.sh
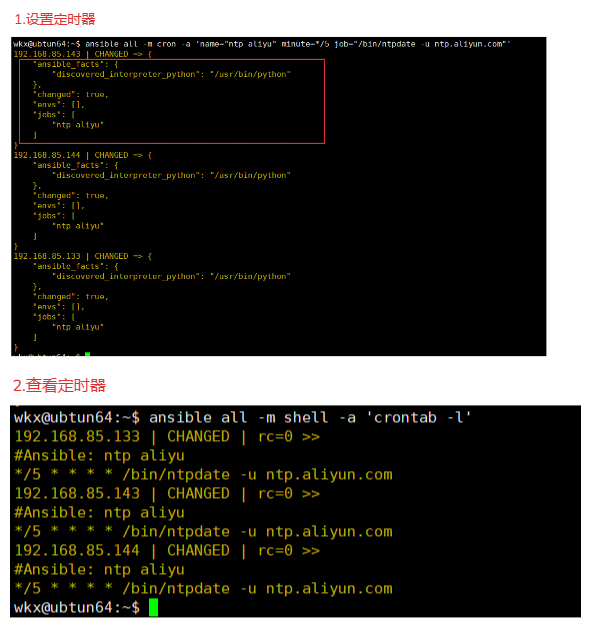
4-9-2.案例-添加定时任务
# 每5分钟与阿里云时间服务器进行同步一次,并且设置一个定时器的名称。
1.命令
ansible all -m cron -a 'name="ntp aliyu" minute=*/5 job="/bin/ntpdate -u ntp.aliyun.com"'
2.查看验证
ansible all -m shell -a 'crontab -l'
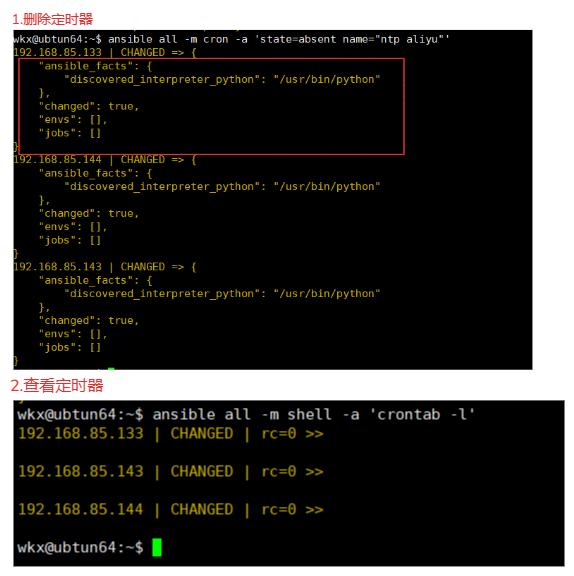
4-9-3.案例-删除定时器
1.命令,使用参数state,name,name指定定时器的名称,state指定属性进行删除
ansible all -m cron -a 'state=absent name="ntp aliyu"'
2.查看
ansible all -m shell -a 'crontab -l'
# 如果没有设置定时器的名称,具体指定定时器的记录
ansible all -m cron -a "job='* * * * * /path/to/script.sh' state=absent"
4-10.group模块
作用:
对远程的节点主机,创建用户组。
命令:
ansible all -m group -a '参数'
4-10-1.参数
| 参数 | 说明 |
|---|---|
| name | 组名 |
| gid | 设置组id |
| state | absent,移除远程主机的组 present,创建远端主机的组(默认) |
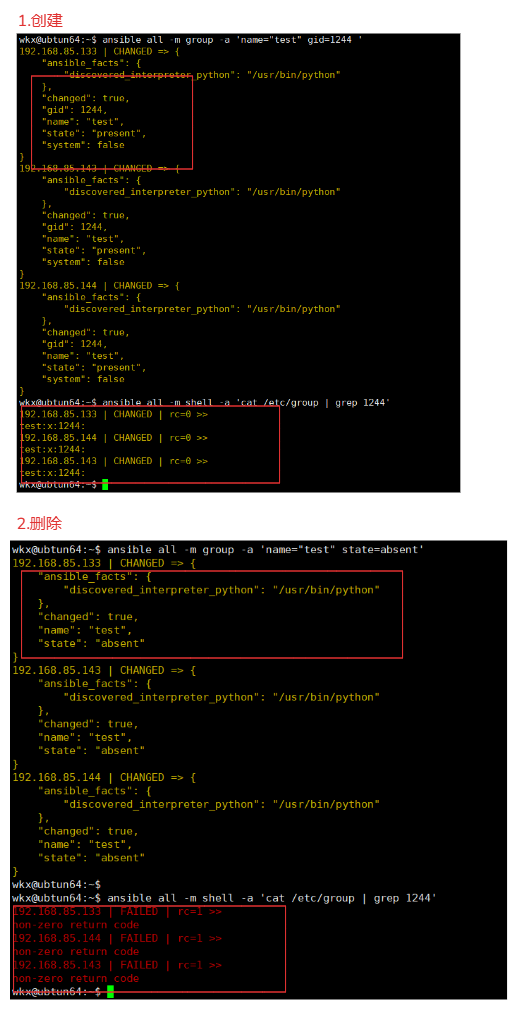
4-10-1.案例-创建删除
1.创建
ansible all -m group -a 'name="test" gid=1244 '
2.查看
ansible all -m shell -a 'cat /etc/group | grep 1244'
3.删除
ansible all -m group -a 'name="test" state=absent'
4.查看
ansible all -m shell -a 'cat /etc/group | grep 1244'
4-11.user模块
作用:
对远程的节点主机,创建用户。
使用:
ansible all -m user -a '参数'
4-11-1.参数
| 模块参数 | 参数描述 |
|---|---|
| create_home | 创建家目录,设置no则不创建家目录 |
| group | 创建用户组,可以指定组名称,也可以指定组id。 |
| name | 创建用户的名字 |
| password | 创建用户的密码 |
| uid | 创建用户的UID |
| shell | 用户登录解释器 |
| state | absent(删除用户)present(默认参数,创建) |
| expires | 账户过期时间 |
| remove | remove=yes:删除用户的主目录和邮件目录(如果存在)。remove=no:不删除用户的主目录和邮件目录(默认值)。 |
4-11-2.案例-创建用户
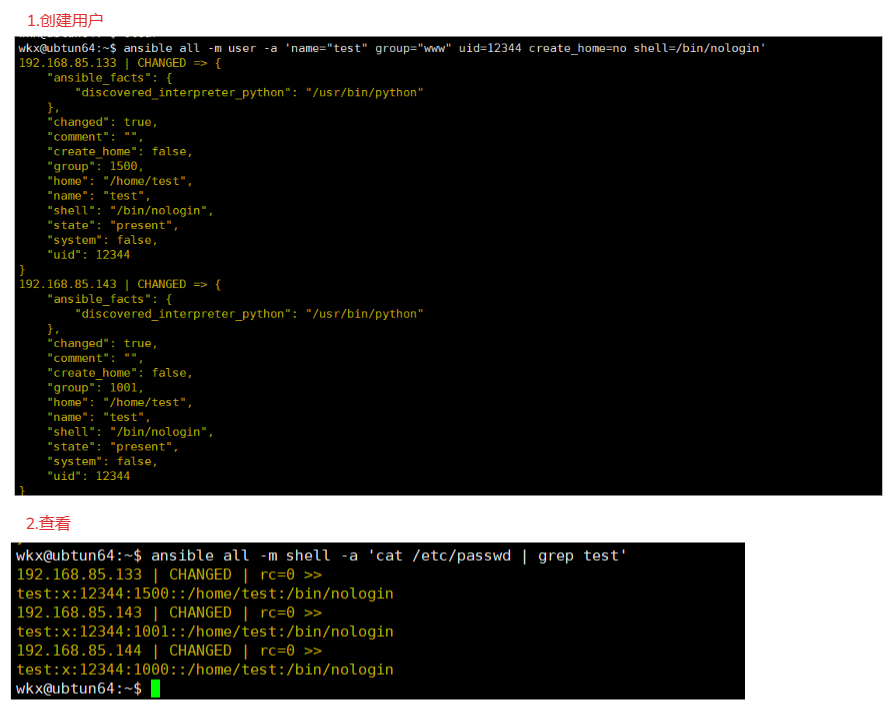
1.命令
ansible all -m user -a 'name="test" group="www" uid=12344 create_home=no shell=/bin/nologin'
解释:
name="test":用户名称test
group="www":使用的主组是www
uid=12344:设置用户id为12344
create_home=no:不创建主目录
shell=/bin/nologin:用户不登录
2.查看
ansible all -m shell -a 'cat /etc/passwd | grep test'
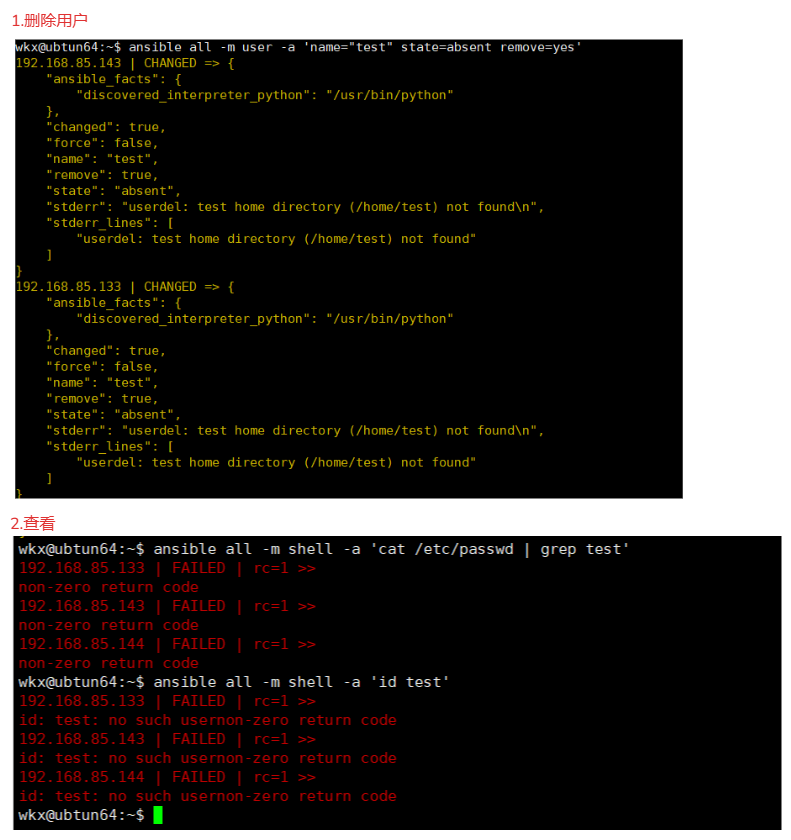
4-11-3.案例-删除用户
1.删除用户,使用参数 state=ansent
ansible all -m user -a 'name="test" state=absent remove=yes'
2.查看
ansible all -m shell -a 'cat /etc/passwd | grep test'
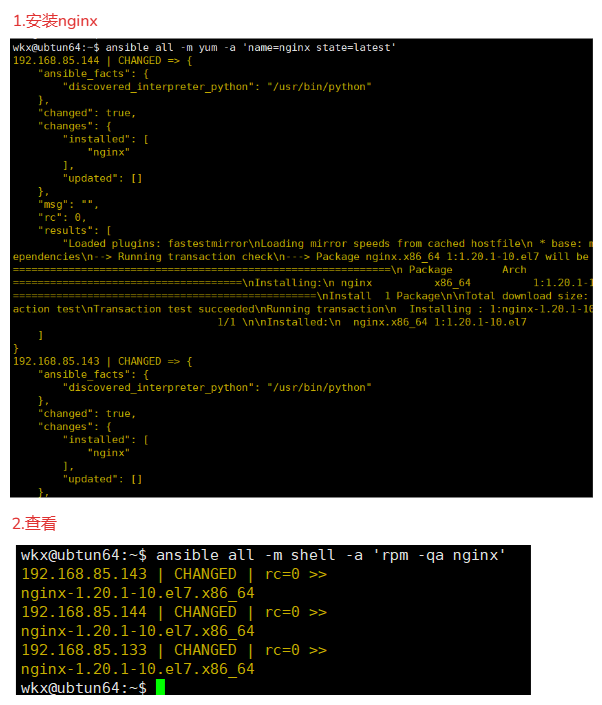
4-12.yum模块
作用:
软件管理模块,删除安装,升级模块
使用:
ansible all -m yum -a '参数'
4-12-1.参数
| 参数 | 作用 |
|---|---|
| conf_file | 设置远程依赖的配置文件 |
| disable_gpg_check | 在安装包前进行检查,只会影响stae参数为present或者latest,disable_gpg_check=yes/no。 |
| list | 只能有ansible调用。不支持playbook。 |
| name | 安装包的名称。例如:name="python=2.7" |
| state | 用于安装包的状态。present/latest/installed安装包,absent/removed删除包。 |
| update_cache | 安装包前更新list,只会影响stae参数为present或者latest,update_cache=yes/no |
4-12-2.案例-安装
1.安装 net-tools 包
ansible all -m yum -a 'name=nginx state=latest'
2.查看
ansible all -m shell -a 'rpm -ql nginx'
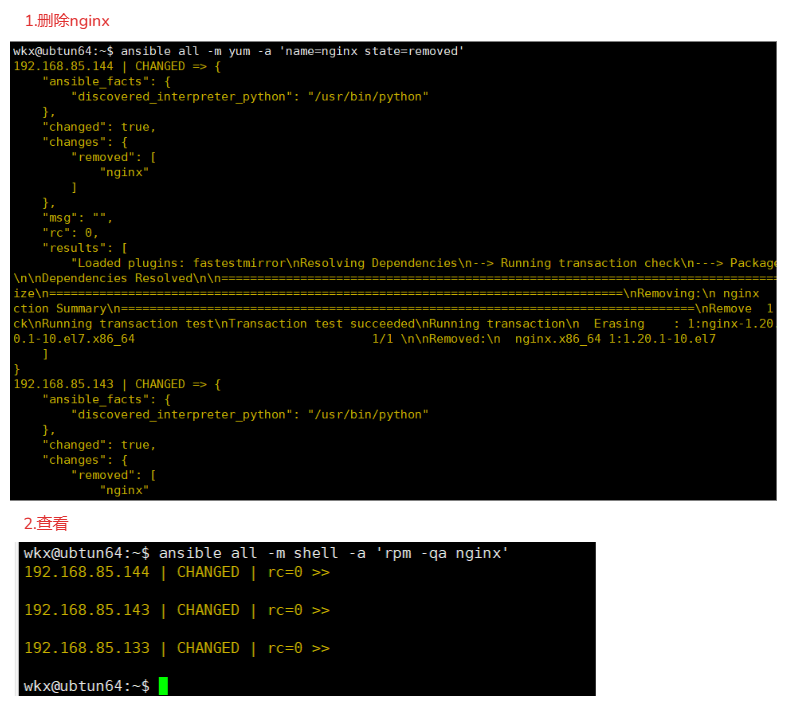
4-12-3.案例-卸载
1.安装 net-tools 包
ansible all -m yum -a 'name=nginx state=removed'
2.查看
ansible all -m shell -a 'rpm -ql nginx'
4-13.systemd模块
作用:
对应的是service命令,管理服务状态,启停的作用,主要针对yum 或者 rpm 安装的服务进行管理 ubuntu apt dpkg
使用:
ansible all -m system -a '参数'
4-13-1.参数
| 参数 | 作用 |
|---|---|
| daemon_reload | 在执行任何其他操作之前运行守护进程重新加载,以确保systemd已经读取其他更改 |
| enabled | 服务是否开机自动启动yes|no。enabled和state至少要有一个被定义 |
| masked | 是否将服务设置为masked状态,被mask的服务是无法启动的 |
| name | 必选项,服务名称 |
| no_block | 不要同步等待操作请求完成 |
| state | 对当前服务执行启动,停止、重启、重新加载等操作( started(ansible会根据,启动服务的pid进行执行,如果当前pid存在,那么就不会执行< 图-1 >), stopped, restarted(不会根据服务是否在启动,直接进行重启操作 < 图-2 >), reloaded) |
| user | 使用服务的调用者运行systemctl,而不是系统的服务管理者 |
4-13-2.案例
1.nginx的安装服务
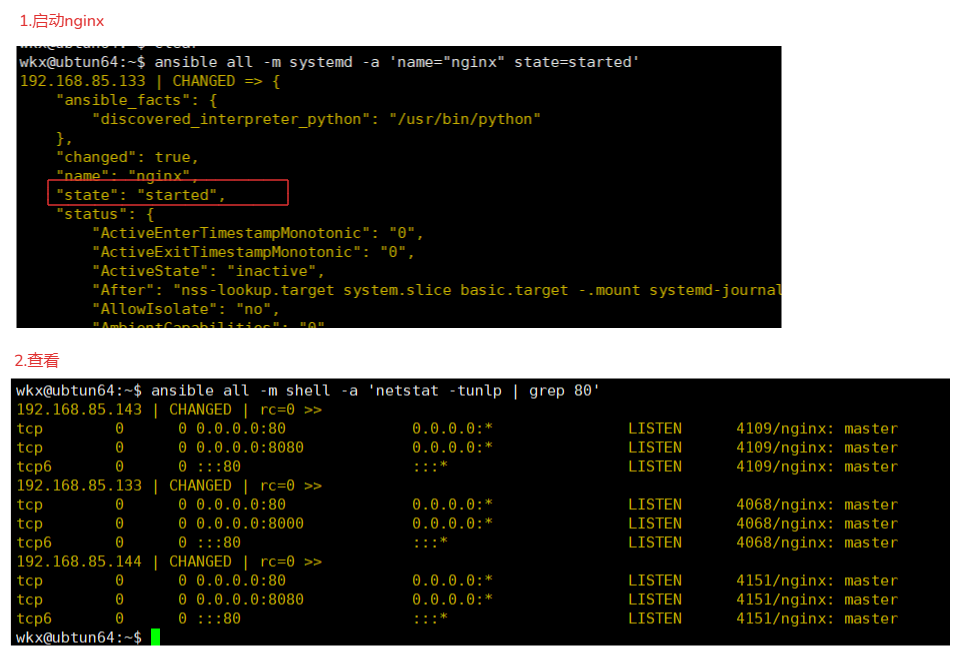
ansible all -m systemd -a 'name="nginx" state=started'
2.查看
ansible all -m shell -a 'netstat -tunlp | grep 80'
4-14.mount模块
作用:
挂载硬盘,挂在文件系统
使用:
ansible all -m mount -a '参数'
4-14-1.参数
| 参数 | 说明 |
|---|---|
| path | 挂载点(将挂载设备映射到本机的哪里) |
| src | 挂在的设备(设备的路径) |
| state | mounted 1.立即挂载 2.写入挂载点 /etc/fstab 3.如果挂载点不存在就会创建挂载点 unmounted 1.卸载挂载设备 2.不会删除/etc/fstab present 1.只写入/etc/fstab 2.不会立即挂载 absent 1.删除挂载点 2.删除/etc/fstab 记录 3.卸载设备 remounted 1.重新挂载该设备 |
| fstype | 挂载的文件系统 |
4-14-2.案例
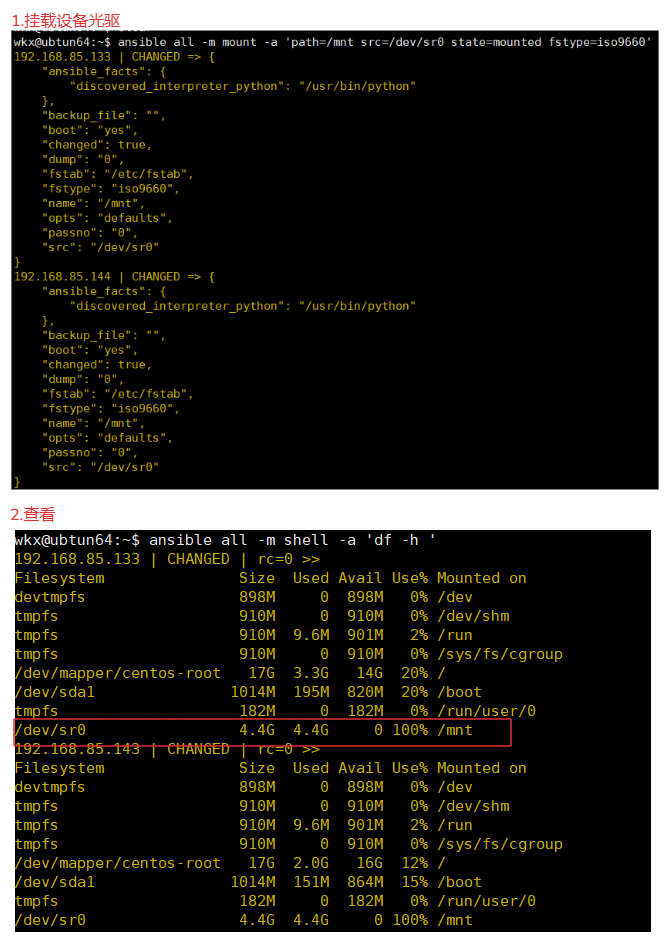
1.命令,挂载iso镜像,挂载设备光驱
ansible all -m mount -a 'path=/mnt src=/dev/sr0 state=mounted fstype=iso9660'
2.查看
ansible all -m shell -a 'df -h '
4-15.archive模块
作用:
用来进行压缩使用,与tar -czvf 相同意思。
使用:
ansible all -m archive -a '参数'
4-15-1.参数
| 参数 | 作用 |
|---|---|
| path | 压缩文件的源路径,远程目录需要压缩的路径。 |
| dest | 压缩后的文件存放位置,例如:/opt/123.gz 需要带上压缩后的文件以及文件后缀。 |
| format | 压缩的文件格式,bz2 gz(默认) tar xz zip |
4-15-2.案例
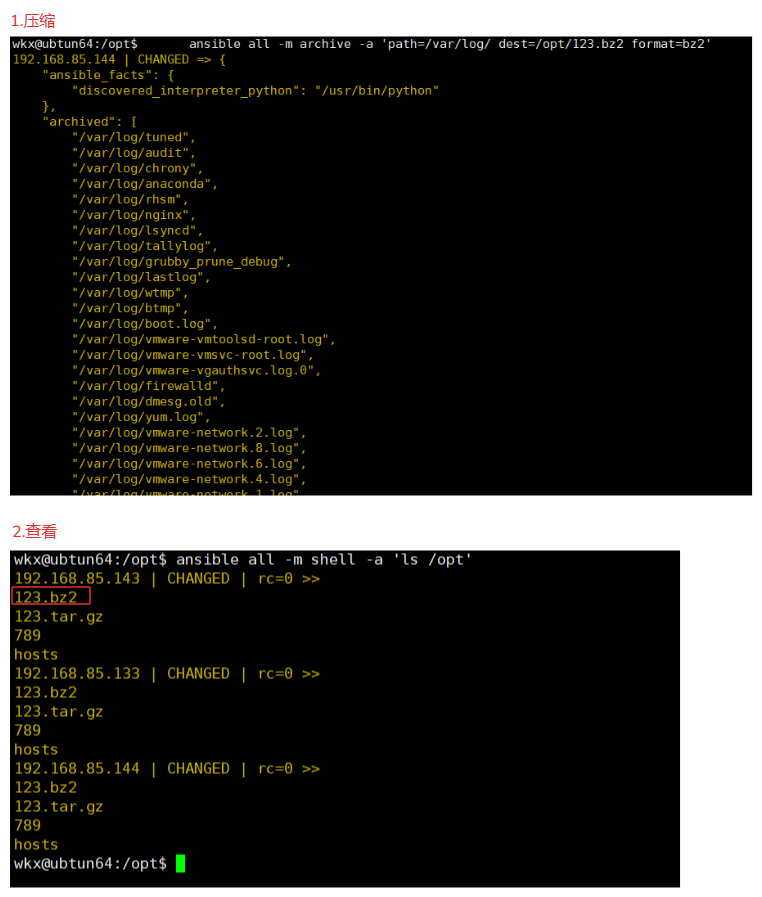
1.远程命令压缩
ansible all -m archive -a 'path=/var/log/ dest=/opt/123.bz2 format=bz2'
2.查看
ansible all -m shell -a 'ls /opt'
4-16.unarchive模块
作用:
用来进行解压使用,与tar -xzvf 相同意思。
使用:
ansible all -m unarchive -a '参数'
4-16-1.参数
| 参数 | 说明 |
|---|---|
| src | 需要解压的文件绝对路径 |
| dest | 解压后文件存放的路径 |
| remote_src | yes or no (yes代表解压远程主机的压缩文件) 这个参数重要,是解压远程,还是解压控制机器本身 |
4-16-2.案例
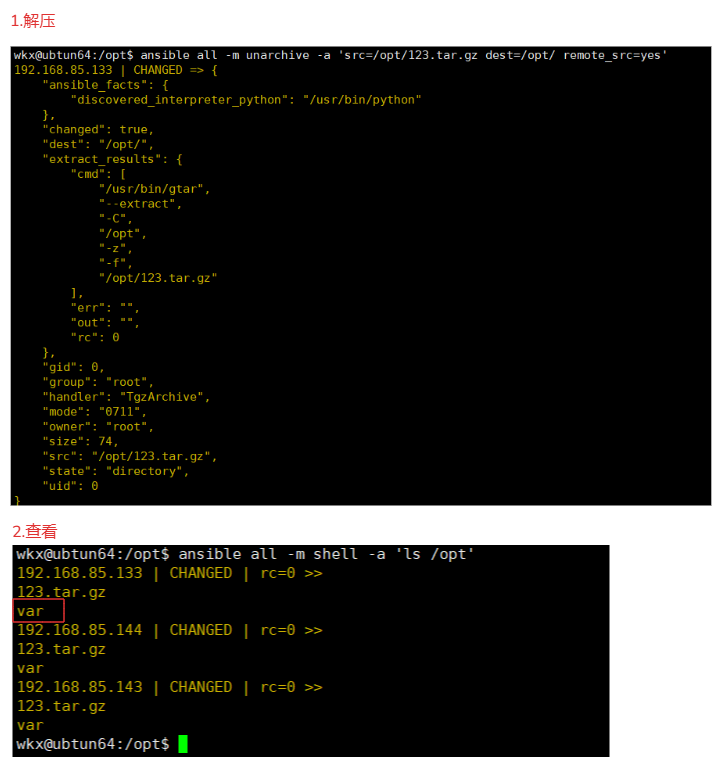
1.命令
ansible all -m unarchive -a 'src=/opt/123.tar.gz dest=/opt/ remote_src=yes'
解释:
代表对远程节点主机解压/opt/123.tar.gz,解压到/opt目录下。
2.查看
ansible all -m shell -a 'ls /opt'
2.ansible的ad-hoc模式
说明:
- 使用一种临时的执行方式,可以直接在远程主机上执行任务,不需要编写ansible的剧本。
- 例如:
ansible all -m shell -a 'ls /opt'特点:
- 快速执行:不需要编写复杂的剧本。
- 灵活性:可以对单机或者分组的主机进行操作。
- 临时性:适用于执行一次性的任务,例如重启服务,更新软件包,收集信息等。
- 模块化:可以给予ansible的模块来完成需要的任务。
基本语法:
ansible <主机或主机群组> -m <模块名> -a "<模块参数>"理解:
- 就是按照命令进行调用模块对远程的主机进行操作。
3.ansible的剧本模式
是什么:
- 是playbook模式针对特定比较大的任务,实现写好剧本(也就是脚本),然后在批量的在机器上进行执行。
- 例如:一键安装nginx并且配置,一键安装mysql等等操作。
- 提供了一个可以重复使用,简单配置管理的多机器部署系统,非常适合在数量庞大机器节点,部署复杂的程序。
- 如果说ad-hoc模式(命令模式)是车间的机器,那么playbook就是说明书或者手册,资源清单上的主机就是原材料。
- 它可以对任务进行编排,就如同docker-compose脚本一模一样,一次性执行多条命令。
优势
- 减少命令的重复写入。
- 更加简洁,可读性更强。
- 功能强大,书写更为专业,支持条件判断,循环,变量,标签等。
- 提供语法检查,以及模拟执行,在执行时可以在任意机器上进行执行。
重点:
- 需要理解ansible模块的以及使用方式,熟悉yaml语法与json语法。
注意:
- 请删除结果转为json的参数,不然返回的内容就是json格式,内容不直观。
3-1.playbook剧本理解
# ansible的剧本概念 与电影的概念相似 对比理解
重要的因素:
电影名称 -> 对基本的概括,name 注释,一种说明
演员 -> 对应了/etc/ansible/hosts 清单中得主机组(ansible核心在与操作那些主机组)
场景 -> 模块参数
时间
事件
台词
道具
总结:
ansible 剧本
1.剧本的注释(说明这是干什么的)
2.剧本的操作的主机组
3.使用模块的参数
ansible剧本,一系列的任务,按照我们期望的结果编排在一起
hosts: 定义主机角色
tasks: 具体执行的任务
# 一个剧本例如:
-演员列表:A,B
场景:
- 场景1: A开始打游戏
动作1: 打游戏,被杀的丢盔卸甲,开始红温
- 场景2: B也开始打游戏
动作1: 打游戏,大杀四方,哈哈大笑
# 对比 ansible剧本
- hosts: 需要执行的机器,nfs机器组
tasks:
- 任务1:安装nfs
动作: yum install nfs
- 任务2:创建数据目录
动作: mkdir -p xxxx
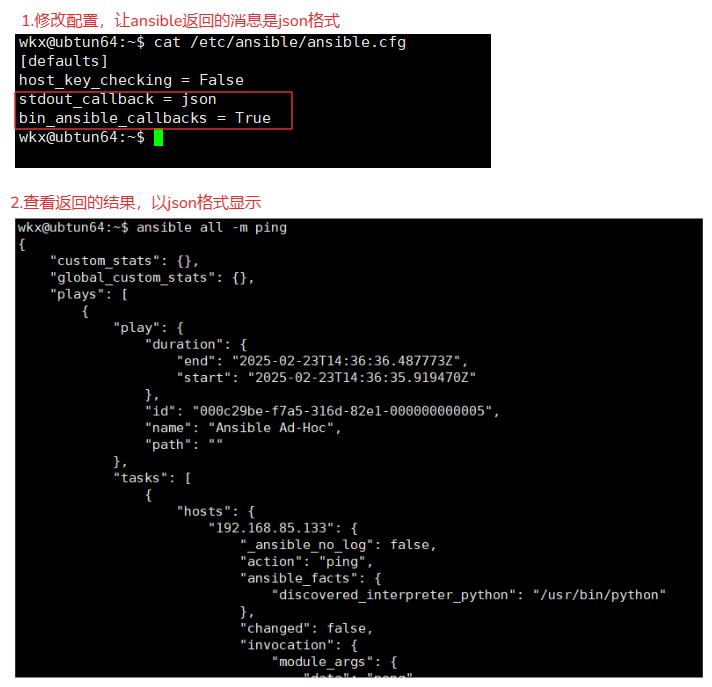
3-2.ansible结果转换json格式
1.修改配置文件 # 返回的结果就是json格式。
vim /etc/ansible/ansible.cfg
stdout_callback = json
bin_ansible_callbacks = True
2.查看配置,并且测试
cat /etc/ansible/ansible.cfg
3-2-1.json格式语法特点
JSON (JavaScript Object Notation, JS 对象标记) 是一种轻量级的数据交换格式;
完全独立于编程语言的文本格式来存储和表示数据;
简洁和清晰的层次结构使得 JSON 成为理想的数据交换语言。
易于人阅读和编写,同时也易于机器解析和生成,并有效地提升网络传输效率。
数据传输是我们在敲代码时,经常遇到的一个场景,前后端交互。
给数据一个统一的格式有利于我们编写和解析数据
3-2-2.语法说明
JSON 是一种数据格式。它本身是一串字符串,只是它有固定格式的字符串,符合这个数据格式要求的字符串,我们称之为JSON。
JSON可以和任意编程语言交互,C、golang、java、python等,再转变为编程语言特有的数据类型;
JSON键值对数据结构如上图,以 "{" 开始,以 "}" 结束。中间包裹的为Key : Value的数据结构。
# 语法规则:
JSON 语法是 JavaScript 对象表示语法的子集。
数据在名称/值对中
数据由逗号分隔
大括号 {} 保存字典
中括号 [] 保存列表
# json值显示
数字(整数或浮点数)
字符串(在双引号中)
逻辑值(true 或 false)
列表(在中括号中)
键值对(在大括号中)
null
# 例如:
{
"name":123,
"name2":"asdsad",
"name3":true,
"name4":[1,211,2,3,4],
"name5":null
}
3-2-3.使用命令进行提取
命令:
jq
文档:
https://jqlang.org/manual/
安装:
apt 或 yum 进行安装。
sudo apt install jq -y
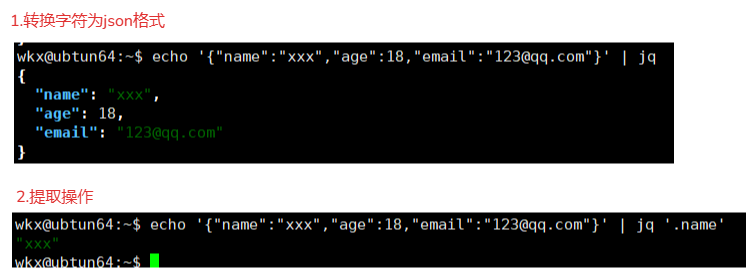
# 1.例如:json转换
echo '{"name":"xxx","age":18,"email":"123@qq.com"}' | jq
# 2.例如:提取操作,提取name值
echo '{"name":"xxx","age":18,"email":"123@qq.com"}' | jq '.name'
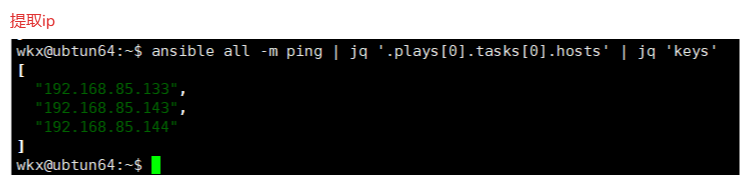
3-2-4.案例-提取主机ip
提取 ansible all -m ping 的全部的主机ip
ansible all -m ping | jq '.plays[0].tasks[0].hosts' | jq 'keys'
.plays[0] : .plays提取返回结果的plays(它是一个列表)[0]获取列表的第一个元素
.tasks[0]:同理
.hosts:获取内部的hosts对应的value
jq 'keys':只获取这资格value内部的key
3-2-5.提取语法
1. 提取单个字段
语法:
jq '.字段名'
案例: 提取 JSON 中的 name 字段。
echo '{"name": "Alice", "age": 25}' | jq '.name'
输出:
"Alice"
2. 提取嵌套字段
语法:
jq '.字段1.字段2'
案例: 提取嵌套字段 address.city。
echo '{"address": {"city": "Beijing", "country": "China"}}' | jq '.address.city'
输出:
"Beijing"
3. 提取数组中的元素
语法:
jq '.数组名[索引]'
案例: 提取数组的第一个元素。
echo '{"hobbies": ["reading", "coding", "traveling"]}' | jq '.hobbies[0]'
"reading"
4. 提取所有数组元素
语法:
jq '.数组名[]'
案例: 提取数组中的所有元素。
echo '{"hobbies": ["reading", "coding", "traveling"]}' | jq '.hobbies[]'
"reading"
"coding"
"traveling"
5. 提取多个字段
语法:
jq '{字段1, 字段2}'
案例: 提取 name 和 email 字段。
echo '{"name": "Alice", "age": 25, "email": "alice@example.com"}' | jq '{name, email}'
{
"name": "Alice",
"email": "alice@example.com"
}
6. 提取所有键
语法:
jq 'keys'
案例: 提取 JSON 对象的所有键。
echo '{"name": "Alice", "age": 25, "email": "alice@example.com"}' | jq 'keys'
[
"name",
"age",
"email"
]
7. 提取所有值
语法:
jq 'values'
案例: 提取 JSON 对象的所有值。
echo '{"name": "Alice", "age": 25, "email": "alice@example.com"}' | jq 'values'
[
"Alice",
25,
"alice@example.com"
]
8. 条件过滤
语法:
select(条件)
案例: 提取年龄大于 20 的对象。
echo '[{"name": "Alice", "age": 25}, {"name": "Bob", "age": 18}]' | jq '.[] | select(.age > 20)'
{
"name": "Alice",
"age": 25
}
9. 遍历 JSON 数组
语法:
jq '.[].name'
案例: 遍历 JSON 数组中的每个元素。只取name
echo '[{"name": "Alice"}, {"name": "Bob"}]' | jq '.[].name'
"Alice"
"Bob"
10. 提取键值对
语法:
jq 'to_entries'
案例: 提取键值对。
echo '{"name": "Alice", "age": 25}' | jq 'to_entries'
[
{
"key": "name",
"value": "Alice"
},
{
"key": "age",
"value": 25
}
]
11. 格式化输出
语法:
-C(彩色输出)或 -S(按键排序)
案例: 格式化输出 JSON 数据。
echo '{"age": 25, "name": "Alice"}' | jq -S .
{
"age": 25,
"name": "Alice"
}
12. 提取所有键(顶层)
语法:
jq -r 'keys[]'
案例: 提取 JSON 对象的所有顶层键。
echo '{"192.168.1.1": {"ping": "pong"}, "192.168.1.2": {"ping": "pong"}}' | jq -r 'keys[]'
192.168.1.1
192.168.1.2
3-3.yaml语法使用
特点:
- 空格缩进,严格的缩进表示不同的层级关系(2格空格代表一层缩进关系)。
- 禁止使用tab键进行缩进,因为tab键默认4个空格。
- 冒号后面一定带上一个空格,进行区分。: 内容
- 短横线后面一定带上一个空格,进行区分。- 内容
- ansible剧本名称结尾必须是yaml或者yml,程序可读。
YAML 结构
标量:直接写键值对,值可以是字符串、数字等。
序列:以短横线 - 开头,每个元素占一行。
映射:键值对用冒号 : 分隔,通过缩进表示层级关系。
锚点和别名:使用 & 定义锚点,* 引用锚点。
文档分隔符:用 --- 分隔多个文档。
多行文本:用 | 表示字面量,用 > 表示折叠文本。
流式风格:类似于 JSON 的紧凑格式。
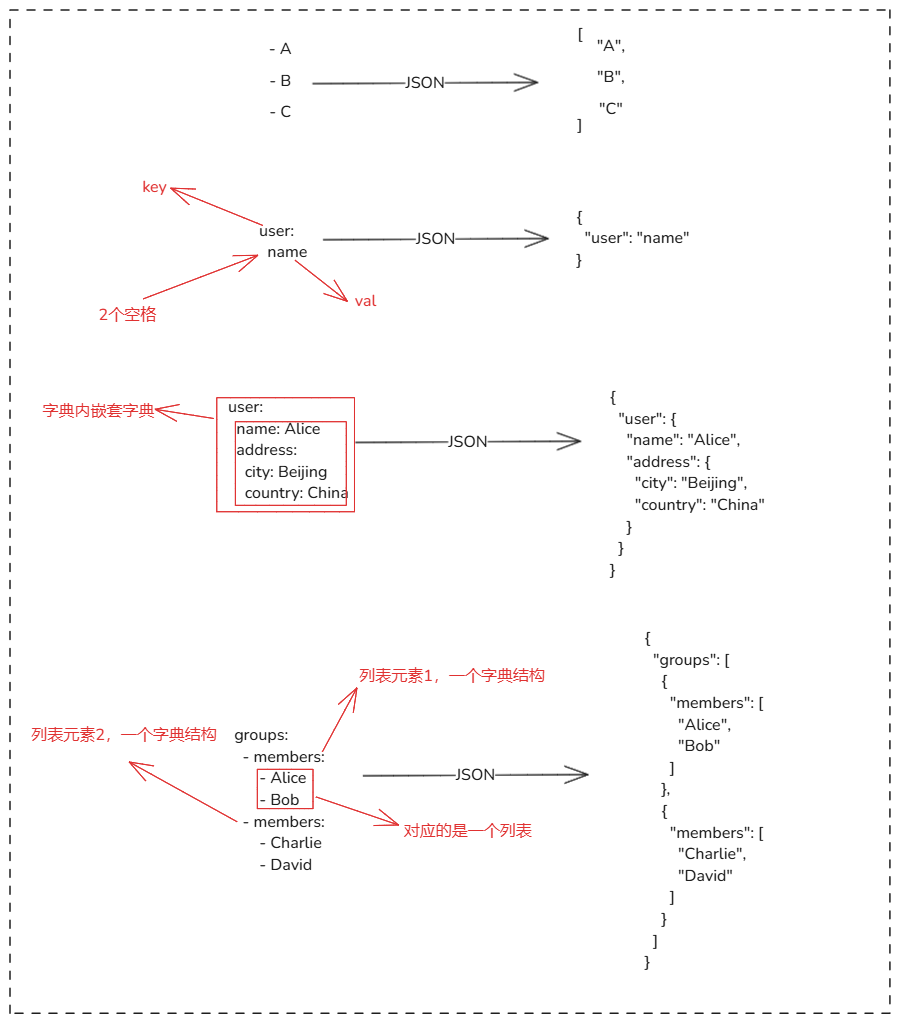
例如:json 转为 yaml
json字典结构:
{
"name":"xxxx"
}
yaml字典结构:
name:
xxxx
json的列表结构:
["xx","xxx","xxxx"]
yaml的列表结构:
- "xx"
- "xxx"
- "xxxx"
3-3-1.剧本yaml语法说明
1.ad-hoc模式
ansible all -m yum -a 'name=nginx state=installed'
ansible all -m systemd -a 'name=nginx state=started'
2.转为playboook模式
- name: 这是ngxin的剧本 # 剧本说明
hosts: nfs # 主机清单组
tasks: # 开始的任务
- name: 01 安装nginx # 任务第一步说明
yum: # 使用的模块
name: nginx # 程序名
state: installed # 软件安装状态
- name: 02 启动nginx # 任务第二步说明
systemd: # 使用的模块名
name: nginx # 软件名字
state: started # 软件启动状态
3.验证剧本的是否可以执行
ansible-playbook -C 剧本的名称.yml
3-3-2.案例-命令转换脚本
1.ad-hoc命令
ansible all -m file -a 'path=/etc/foo.conf mode=644 state=touch'
2.剧本-字典风格
- name: 剧本
hosts: all
tasks:
- name: 操作模块为file
file:
path: /etc/foo.conf
mode: 644
state=touch
3.剧本-变量风格
- name: 剧本
hosts: all
tasks:
- name: 执行file模块
file: path=/etc/foo.conf mode=644 state=touch
- name: 验证
shell: ls -ld /etc/foo.conf
4.执行操作
ansible -playbook -C 123.yaml

3-4.playbook剧本的语法规范
基本结构:
- 目标主机(Hosts):指定要操作的主机或主机组。
- 任务列表(Tasks):定义要在目标主机上执行的具体任务。
- 变量定义(Variables):可选,用于定义在任务中使用的变量。
- 模块调用(Modules):每个任务通过调用 Ansible 模块来实现具体功能。
YAML 文件规范:
- 文件扩展名:通常为
.yaml或.yml。- 文件开头:以
---开始,表示 YAML 文件的开始。- 大小写敏感:YAML 文件区分大小写。
- 缩进规则:使用空格缩进(不支持 Tab),相同层级的元素对齐。
- 注释:使用
#表示注释,从该字符到行尾的内容会被忽略。
3-4-1.简单的剧本
# 这个是一个简单的剧本,主要就是定义剧本到底干了什么(那个远程节点,执行了哪些模块,使用了哪些参数)
- name: Configure web servers # 名称:这个剧本的简介
hosts: webservers # 执行的远程节点组
tasks: # 执行的核心任务
- name: Ensure Apache is installed # 名称:说明这块执行什么
yum: # 模块
name: httpd # 参数1
state: present # 参数2
3-4-2.Tasks
# tasks 任务就是一个执行ansible 模块的具体操作部分。
tasks:
- name: Install Apache
ansible.builtin.yum:
name: httpd
state: present
3-4-3.Variables
# Variables 一个剧本中可能重复的使用某个值,变量重用可以使用它。
vars:
http_port: 80
max_clients: 200
3-4-5.Handlers
# Handlers 是一种特殊的任务,通常用于响应某些事件(如服务重启)。
handlers:
- name: restart apache
ansible.builtin.service:
name: httpd
state: restarted
3-5-6.命令
# 使用 ansible命令校验
ansible-playbook -C 123.yaml
# 在使用 ansible-playbook剧本
ansible-playbook 123.yaml
3-5-7.剧本编写流程
1. 要先编写 ad-hoc 命令
2. 在根据编写的 ad-hoc 命令 去编写 playbook脚本
需要遵守yaml语法,注意缩进,注意语法的错误
3.需要创建,playbook 剧本中得需要使用的配置文件
创建剧本中需要的文件(配置文件,...)
4.使用 命令验证脚本的是否可以运行
ansible-playbook -C xxx.yml
5.正确安装剧本
ansible-playbook xxx.yml
6.验证剧本中安装的配置的内容是否正确配置
3-5.案例-安装脚本
实现:
192.168.85.133 # nfs服务器 lrsync软件实时备份到 143 安装rsync + lrsync + nfs
192.168.85.143 # 备份nfs服务的备份服务器 安装rsync服务 创建备份文件夹
192.168.85.144 # 挂载nfs服务器,然后安装nginx使用这个目录存放静态文件。安装 nfs + nginx 还需要挂载
# 注意需要卸载原来的安装的内容,不然会有些影响
批量卸载脚本:
- name: Batch uninstall packages
hosts: all
tasks:
- name: Uninstall multiple packages
yum:
name:
- nginx
- nfs
- rpcbind
- rsync
- lrsync
state: absent
# 安装脚本
- name: 192.168.85.143 安装nfs备份的rsync服务器
hosts: 192.168.85.143
tasks:
- name: 安装软件
yum:
name:
- rsync
- name: 创建用户
user:
name: test01
shell: /bin/nologin
create_home: no
- name: 创建备份文件夹
file:
name: /data_test_backup
state: directory
owner: test01
group: test01
- name: 拷贝rsync服务需要的配置文件
copy:
src: /opt/rsyncd.conf
dest: /etc/rsyncd.conf
backup: yes
- name: 创建密码文件
shell: echo "rsync_backup:123456" > /etc/rsync.passwd && chmod 600 /etc/rsync.passwd
- name: 启动rsync服务端
systemd:
name: rsyncd
state: started
- name: 192.168.85.133 nfs + ngxin + lrsync 安装
hosts: 192.168.85.133
tasks:
- name: 安装软件,nfs lrsync rsync
yum:
name:
- nfs-utils
- rpcbind
- rsync
- lsyncd
state: installed
- name: 创建用户
user:
name: test01
shell: /bin/nologin
create_home: no
- name: 创建文件夹到根目录
file:
name: /data_test
state: directory
owner: test01
group: test01
- name: 写入nfs配置文件
copy:
dest: /etc/exports
content: "/data_test *(insecure,rw,sync,root_squash)"
- name: 写入lrsync配置
copy:
src: /opt/lsyncd.conf
dest: /etc/lsyncd.conf
backup: yes
- name: 创建密码文件
shell: echo "123456" > /etc/rsync.passwd && chmod 600 /etc/rsync.passwd
- name: 启动服务
systemd:
name: "{{ item }}"
state: started
loop:
- lsyncd
- rpcbind.service
- rpcbind.socket
- nfs
- name: 192.168.85.144 安装nginx与nfs进行挂载
hosts: 192.168.85.144
tasks:
- name: 安装软件 nginx 与 nfs
yum:
name:
- nginx
- nfs-utils
- rpcbind
state: installed
- name: 拷贝nginx的配置文件
copy:
src: /opt/test.conf
dest: /etc/nginx/conf.d/test.conf
backup: yes
- name: 挂载目录
mount:
path: /mnt
src: 192.168.133:/data_test
opts: "vers=4,proto=tcp"
fstype: nfs
state: mounted
- name: 启动nginx
systemd:
name: nginx
state: started
3-5-1.rsync服务配置配置
# 存放在宿主机 /opt/rsyncd.conf
uid = test01
gid = test01
port = 873
fake super = yes
use chroot = no
max connections = 200
timeout = 600
ignore errors
read only = false
list = false
auth users = rsync_backup
secrets file = /etc/rsync.passwd
log file = /var/log/rsyncd.log
pid file = /var/run/rsyncd.pid
[backup]
comment = about rsync 1
path = /data_test_backup
3-5-2.lrsync服务配置配置
# /opt/lsyncd.conf
settings {
logfile ="/var/log/lsyncd/lsyncd.log",
statusFile ="/var/log/lsyncd/lsyncd.status",
inotifyMode = "CloseWrite",
maxProcesses = 8,
}
sync {
default.rsync,
source = "/data_test",
target = "rsync_backup@192.168.85.143::backup",
delete= true,
exclude = {".*"},
delay=1,
rsync = {
binary = "/usr/bin/rsync",
archive = true,
compress = true,
verbose = true,
password_file="/etc/rsync.passwd",
_extra={"--bwlimit=200"}
}
}
3-5-3.nginx的配置文件
/opt/test.conf
server {
listen 8080;
server_name _;
root /mnt/;
location / {
index index.html;
}
}
3-5-4.执行脚本
1.启动脚本
ansible-playbook 123.yaml
# 注意:可能会出现无法挂载的情况,服务正常启动,手动可以,可以替换为 shell 手动挂载
- name: 挂载目录
mount:
path: /mnt
src: 192.168.133:/data_test
opts: "vers=4,proto=tcp"
fstype: nfs
state: mounted
替换为:
shell: monut -t nfs 192.168.85.144:/data_test /mnt
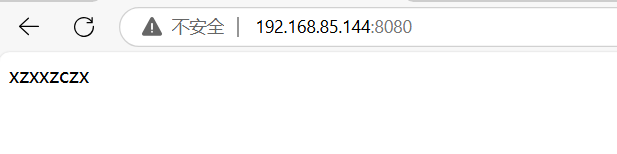
2.写入一个文件到 192.168.85.133 /data_test 文件中
ansible 192.168.85.133 -m copy -a 'dest=/data_test/index.html content="xzxxzczx"'
3.访问192.168.85.144:8080即可
3-6.playbook的关键字
3-6-1.loop关键字
作用:
循环作用,可以循环变量
使用:
loop: # loop 声明循环,下面的声明的就是一个[test1,test2,test3...]
- test1
- test2
- test3
例如:
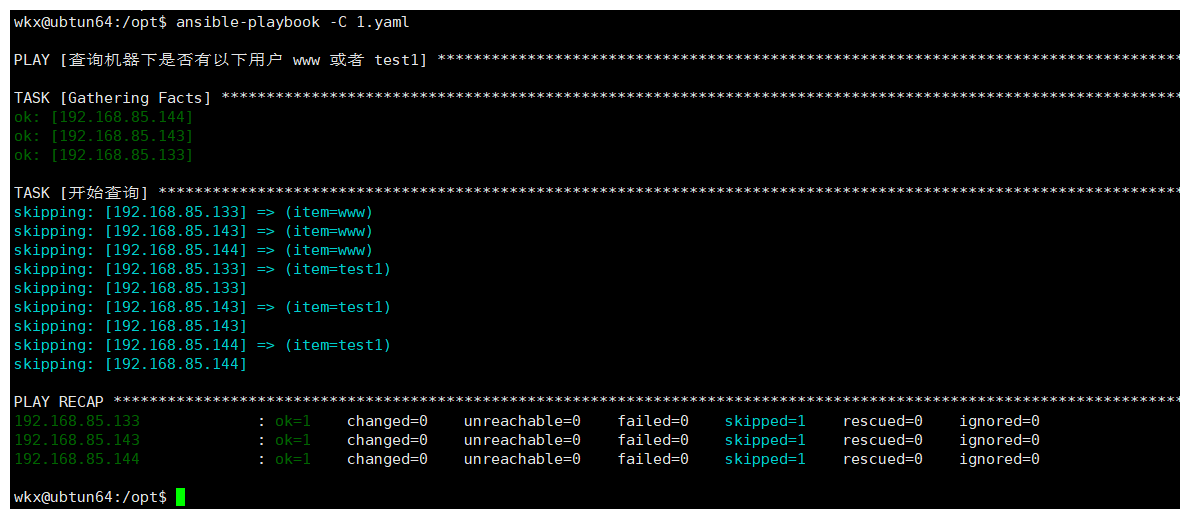
- name: 查询机器下是否有以下用户 www 或者 test1
hosts: all
tasks:
- name: 开始查询
command: getent passwd "{{ item }}"
loop:
- www
- test1
# 注意:
1.loop 作用: 对变量进行循环。
2."{{ item }}" 作用:是默认的变量名,用于引用当前迭代的元素。
3.为什么loop循环需要再操作的'模块'下面因为是对模块进行循环。必须与模块同级,才能作用于模块执行。
3-6-2.vars关键字
作用:
用来声明变量使用,是对yaml的一种扩展语法。
文档:
https://docs.ansible.com/ansible/latest/user_guide/playbooks_variables.html
使用:
vars:
user_list: # 声明一个列表
- test1
- test2
- test3
user_dict: # 声明一个列表套字典
- {user:'a1',uid:'200'}
- {user:'a2',uid:'201'}
- {user:'a3',uid:'202'}
age: 18 # 字典
# 例如:列表结构
- name: 查询机器下是否有以下用户 www 或者 test1
hosts: all
vars:
user_name_list:
- www
- test1
tasks:
- name: 开始查询
command: getent passwd "{{ item }}" # 使用变量内的元素
loop: "{{ user_name_list }}" # 引用变量user_name_list
# 例如:单个变量不是列表就不需要使用循环,直接使用变量名称
- name: 查询机器下是否有以下用户 test
hosts: all
vars:
user_name: test
tasks:
- name: 开始查询
command: getent passwd "{{ user_name }}"
#例如:比较复杂的变量使用,声明的是一个列表嵌套字典的结构,怎么取值
- name: 创建用户
hosts: all
vars:
user_list: # 变量名称
- {user: 'a1',uid: '200'}
- {user: 'a2',uid: '201'}
- {user: 'a3',uid: '202'}
tasks:
- name: 创建用户
user: # item 就是每一个 user_list 列表中得元素,每一个元素就是一个字典{},那么就需要取出字典中得值
uid: "{{ item.uid }}" # 取uid
name: "{{ item.user }}" # 取user
state: present
loop: "{{ user_list }}" # loop 循环变量

3-6-3.ansible内置变量
除了自定义的变量以外(使用vars关键字定义),还有模块中存在内置变量。
模块:
setup
# 模块用于收集目标主机的系统信息(称为 facts)。这些信息作为内置变量存储在 ansible_facts 中,可以直接在 playbook 中引用
1.setup模块常用变量:
ansible_hostname:目标主机的主机名。
ansible_default_ipv4.address:目标主机的默认 IPv4 地址。
ansible_os_family:目标主机的操作系统家族。
ansible_distribution:目标主机的操作系统发行版。
ansible_date_time:目标主机的日期和时间信息
2.set_fact模块:用于在 playbook 中动态定义变量
# 注意:在playbook定义的变量后,这些变量可以在后续的任务中继续使用
# 例如:
- name: 使用set_fact模块动态定义变量。
set_fact:
my_custom_fact: "some_value"
- name: Use the custom fact
debug:
msg: "{{ my_custom_fact }}"
3.魔法变量:
inventory_hostname:当前任务执行的主机名。
hostvars:一个字典,包含所有主机的变量和 facts。
group_names:当前主机所属的主机组列表。
groups:一个字典,包含所有主机组及其成员。
4.register关键字:用于捕获模块的执行结果并存储到变量中
# 注意:set_fact模块 与 vars 区别
vars:仅限于当前整个playbook使用,只要定义后就不可以在进行修改。
set_fact模块:定义的变量的作用域是主机级别的(仅限于当前playbook),并且是动态的。意味着变量可以在脚本执行过程中修改,并且在后续任务中还可以被引用。
# 最大的区别就是一个可以动态修改,一个不能修改。
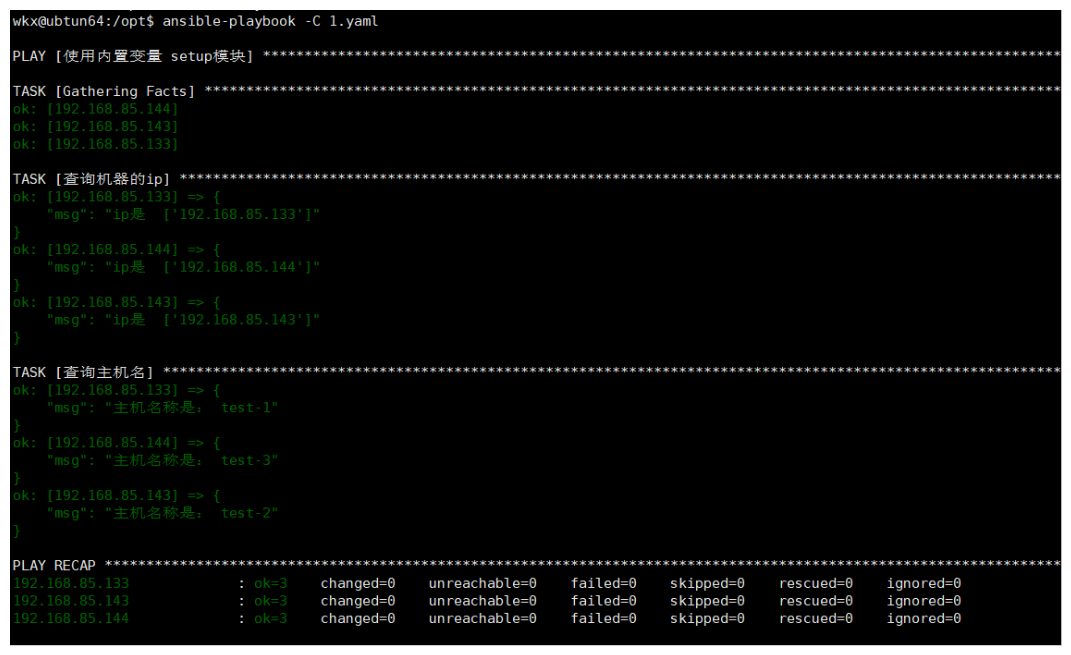
# 案例:
- name: 使用内置变量 setup模块
hosts: all
tasks:
- name: 查询机器的ip
debug: msg="ip是 {{ ansible_all_ipv4_addresses }}"
- name: 查询主机名
debug: msg="主机名称是: {{ ansible_hostname }}"
3-6-4.register关键字
作用:
可以注册一个变量提供使用,它是在执行模块时使用的方法,可以将某个查询的结果写入到这个变量中,在通过debug打印。
文档:
https://docs.ansible.com/ansible/latest/reference_appendices/common_return_values.html
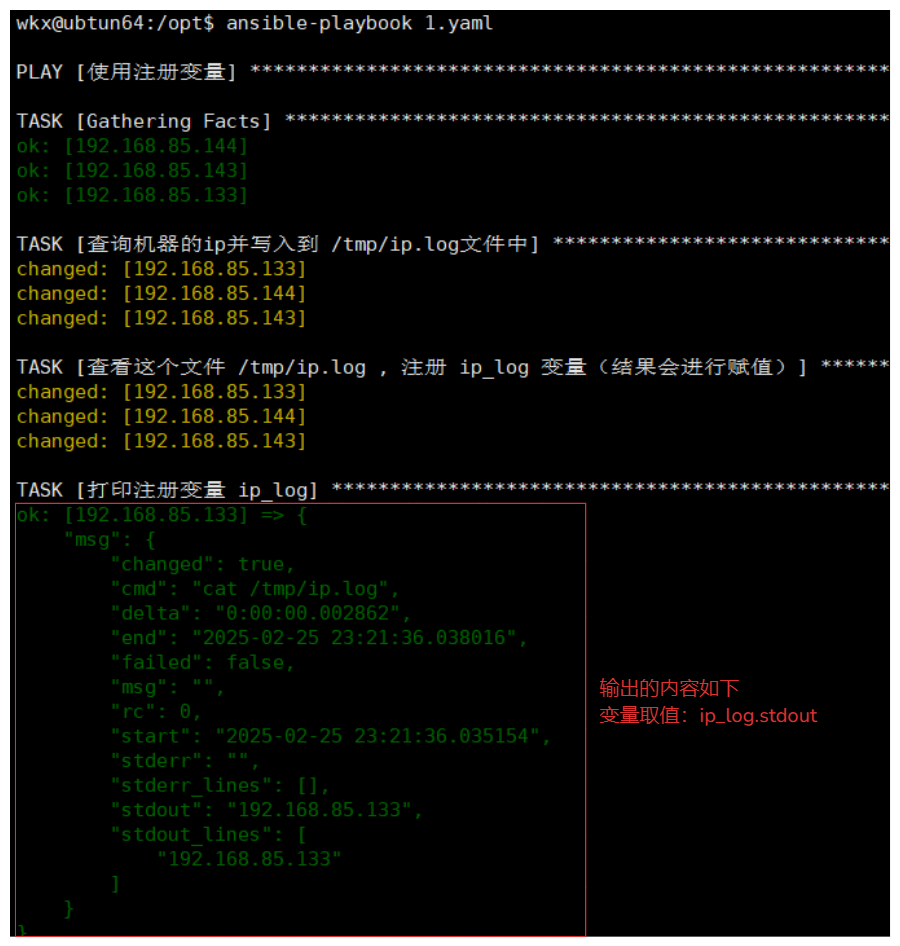
# 例如:注册一个变量
- name: 使用注册变量
hosts: all
tasks:
- name: 查询机器的ip并写入到 /tmp/ip.log文件中
shell: "echo {{ ansible_default_ipv4.address }} >> /tmp/ip.log"
- name: 查看这个文件 /tmp/ip.log , 注册 ip_log 变量(结果会进行赋值)
shell: cat /tmp/ip.log
register: ip_log # 注意:注册一个变量,这个变量的值就是 cat /tmp/ip.log 的结果合集信息
- name: 打印注册变量 ip_log
debug:
msg: "{{ ip_log }}"
输出内容如下:
# 取值的方式例如:注册变量.changed
ok: [192.168.85.133] => {
"msg": {
"changed": true,
"cmd": "cat /tmp/ip.log",
"delta": "0:00:00.002862",
"end": "2025-02-25 23:21:36.038016",
"failed": false, # ip_log.failed
"msg": "",
"rc": 0,
"start": "2025-02-25 23:21:36.035154",
"stderr": "",
"stderr_lines": [],
"stdout": "192.168.85.133",
"stdout_lines": [
"192.168.85.133"
]
}
}
获取注册变量的:
ip_log.changed # 表示任务是否对系统状态产生了更改
ip_log.rc # 0 表示命令执行成功,非 0 表示失败。
ip_log.stdout # 当前命令执行的结果
ip_log.stdout_lines # 当前命令执行的结果
ip_log.stderr # 当前命令错误的结果
# 2.例如:注册多个变量
- name: 注册多变量,并且打印显示效果
hosts: nfs
tasks:
- name: 写入ip
shell: "echo {{ ansible_default_ipv4.address }} > /tmp/ip.log"
- name: 写入主机名
shell: "echo {{ ansible_hostname }} > /tmp/hostname.log"
- name: 查看主机名并且注册变量
shell: "cat /tmp/hostname.log"
register: hostname_log # 注册 shell 的执行返回值
- name: 查看ip并且注册变量
shell: "cat /tmp/ip.log"
register: ip_log # 注册 shell 的执行返回值
- name: 查看 cpu资源情况
shell: " uptime "
register: uptime_log # 注册 shell 的执行返回值
- name: 显示注册的返回值
debug:
msg: "{{item}}"
loop:
- "{{ uptime_log.stdout}}"
- "{{ ip_log.stdout}}"
- "{{ hostname_log.stdout}}"
3-6-5.when关键字
| 类别 | 运算符/测试 | 描述 | 示例 |
|---|---|---|---|
| 逻辑运算符 | and |
逻辑与,所有条件必须同时为真。 | when: condition1 and condition2 |
or |
逻辑或,任一条件为真即可。 | when: condition1 or condition2 |
|
not |
逻辑非,反转条件的真假值。 | when: not condition |
|
() |
用于组合条件,明确优先级。 | when: (condition1 and condition2) or condition3 |
|
| 比较运算符 | == |
等于。 | when: var == 'value' |
!= |
不等于。 | when: var != 'value' |
|
< |
小于。 | when: var < 10 |
|
> |
大于。 | when: var > 10 |
|
<= |
小于等于。 | when: var <= 10 |
|
>= |
大于等于。 | when: var >= 10 |
|
| 测试运算符 | defined |
判断变量是否已定义。 | when: var is defined |
undefined |
判断变量是否未定义。 | when: var is undefined |
|
none |
判断变量是否为空。 | when: var is none |
|
lower |
判断字符串是否全部为小写。 | when: var is lower |
|
upper |
判断字符串是否全部为大写。 | when: var is upper |
|
in |
判断一个字符串是否存在于另一个字符串中。 | when: 'substring' in var |
|
search |
使用正则表达式匹配。 | when: var is search('pattern') |
|
even |
判断数值是否为偶数。 | when: var is even |
|
odd |
判断数值是否为奇数。 | when: var is odd |
|
divisibleby(num) |
判断数值是否可以被指定数值整除。 | when: var is divisibleby(3) |
|
version('ver', 'op') |
比较版本号。 | when: var is version('1.0', '>=') |
|
| 文件测试 | exists |
判断文件是否存在。 | when: var is exists |
directory |
判断路径是否为目录。 | when: var is directory |
|
file |
判断路径是否为文件。 | when: var is file |
|
| 列表测试 | contains |
判断列表是否包含某个值。 | when: var is contains('value') |
length |
判断列表或字符串的长度。 | when: var is length > 5 |
|
| 其他 | changed |
判断任务是否改变了系统状态。 | when: result.changed |
failed |
判断任务是否失败。 | when: result.failed |
|
skipped |
判断任务是否被跳过。 | when: result.skipped |
作用:
用来做条件判断,与其他的编程语言的 if 类似。
文档:
https://docs.ansible.com/ansible/latest/playbook_guide/playbooks_conditionals.html
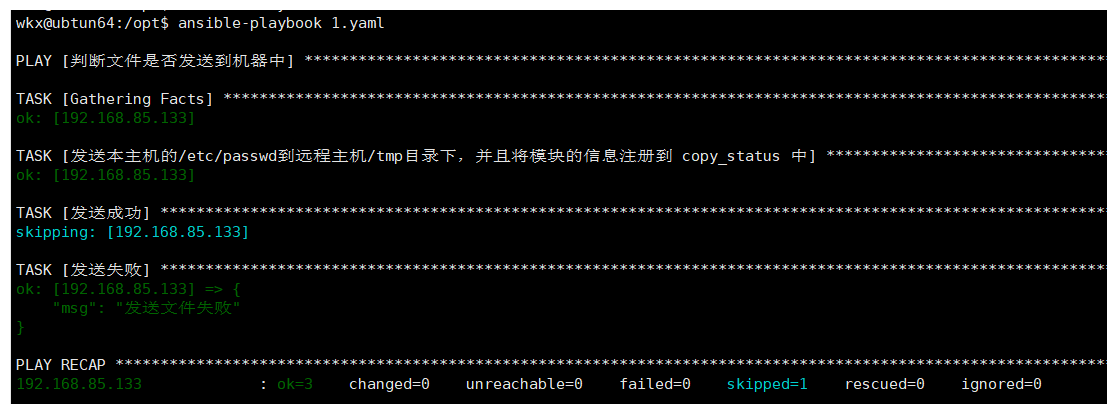
# 案例:判断文件是否发送成功
- name: 判断文件是否发送到机器中
hosts: 192.168.85.133
tasks:
- name: 发送本主机的/etc/passwd到远程主机/tmp目录下,并且将模块的信息注册到 copy_status 中
copy:
src: /etc/passwd
dest: /tmp/
register: copy_status
- name: 发送成功
debug:
msg: "发送文件成功"
when: copy_status.changed is true
- name: 发送失败
debug:
msg: "发送文件失败"
when: copy_status.changed is false
# 注意:
register 注册变量中不一定是相同个内容(根据模块来决定的),可能注册变量中有些有rc值,有些没有,需要先进行查看后在进行判断。
3-6-6.handler关键字
作用:
确保只有在任务实际改变了系统状态后,才会触发相应的操作,从而避免不必要的执行和资源浪费
说明:
是一种特殊的任务,用于在某些条件满足时执行特定操作,例如重启服务或重新加载配置文件。
文档:
https://docs.ansible.com/ansible/latest/playbook_guide/playbooks_handlers.html
# 解决的问题:
例如:当你执行脚本时,需要重启服务(nginx),如果没有修改配置文件的情况下,它还是会进行重启。
可以利用handler进行操作,只有配置文件修改的状态下,才会运行这一块的内容。需要配合 notify + handler 进行处理。
# 其实可以运行when判断也可以实现当前的功能。
# 利用handler添加在剧本中,实现效果
1.配置文件没变化,就不执行restart重启
2.配置文件发生了变化,就执行restart重启
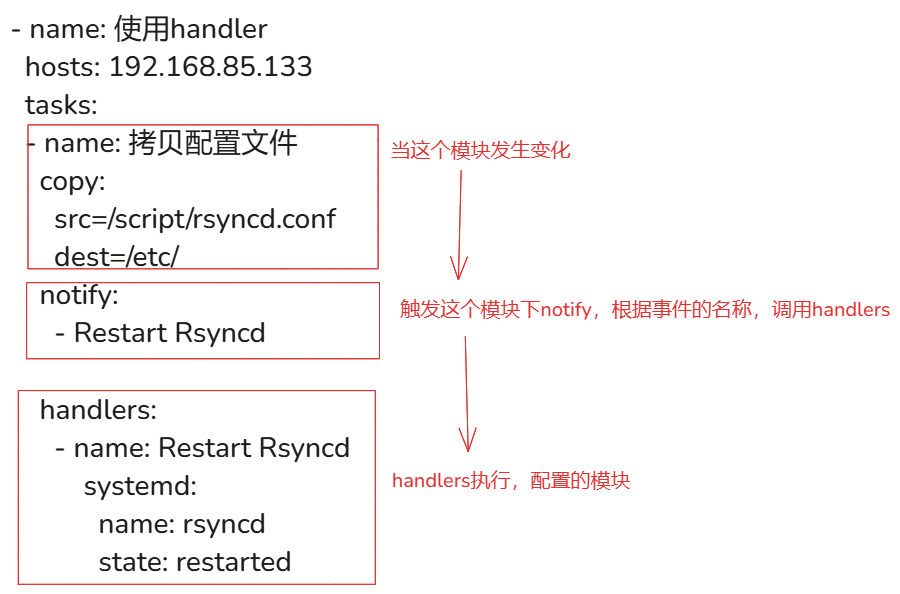
例如:
- name: 使用handler
hosts: 192.168.85.133
tasks:
- name: 拷贝配置文件
copy:
src=/script/rsyncd.conf
dest=/etc/
notify: # 修改配置文件的任务通过 notify 关键触发 Handler
- Restart Rsyncd # 2. 调用事件的名称(可以定义多个进行调用)
handlers: # 1.handlers写入到剧本最后面(可以定义多个)
- name: Restart Rsyncd # 定义事件的名字
systemd: # 内部是具体执行的模块
name: rsyncd
state: restarted
# 解释 handler notify 组合
1.handler关键字必须写在剧本结尾
2.handler可以定义事件列表,也可以定义多个事件,需要给每一个事件起一个名字,通过notify调用。
3.notify属于tasks任务列表中(某一个任务,如果这个任务发生了changed变化,那么就会触发notify执行,执行就是执行handler的定义的事件名字)
3-6-7.tag关键字
作用:
可以根据定义的tag指定某个指定的模块,调试,选择性的执行某个task。
场景:
你写了一个很长的playbook,其中有很多的任务,这并没有什么问题,不过在实际使用这个剧本时,你可能只是想要执行其中的一部分任务而已。# 就是打上tag标签,只执行剧本的某一部分,而不是执行剧本的全部
例如:
- name: 使用tags
hosts: all
tasks:
- name: 01 创建组
group: name=www gid=666
tags: 01_add_group # 打上标签
- name: 02 创建用户
user: name=www uid=666 group=www create_home=no shell=/sbin/nologin
tags: 02_add_user # 打上标签
# 可以具体的指定某个标签的模块执行,其他不执行。
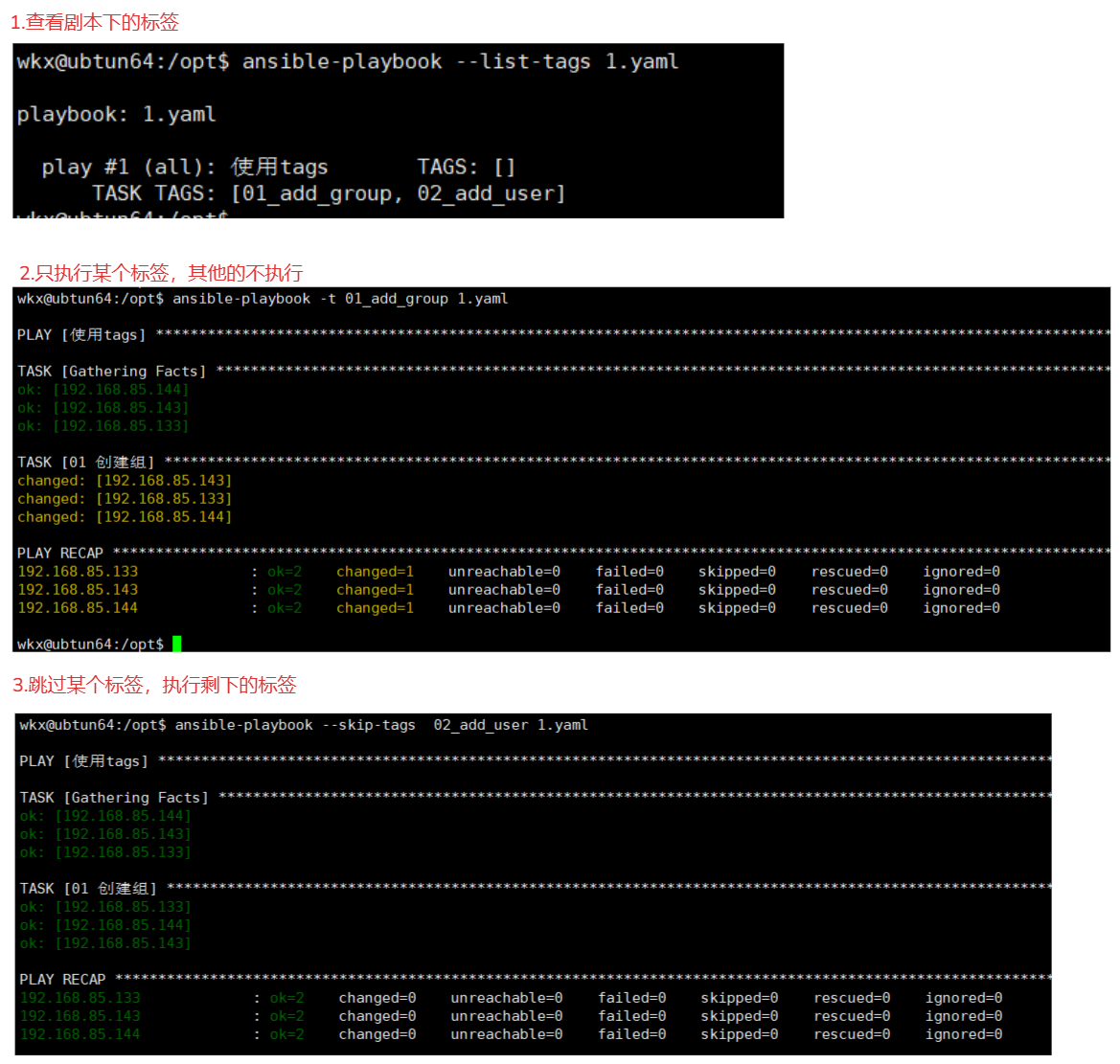
# 相关命令:
1. 打印出当前脚本的全部标签
ansible-playbook --list-tags 1.yaml
2. 只执行某个具体的标签,剩下的标签不执行
ansible-playbook -t 01_add_group 1.yaml
3.跳过某个标签,只执行剩下的标签的模块 # 可以跳过多个标签
ansible-playbook --skip-tags 02_add_user 1.yaml
3-6-8.tasks其他命令
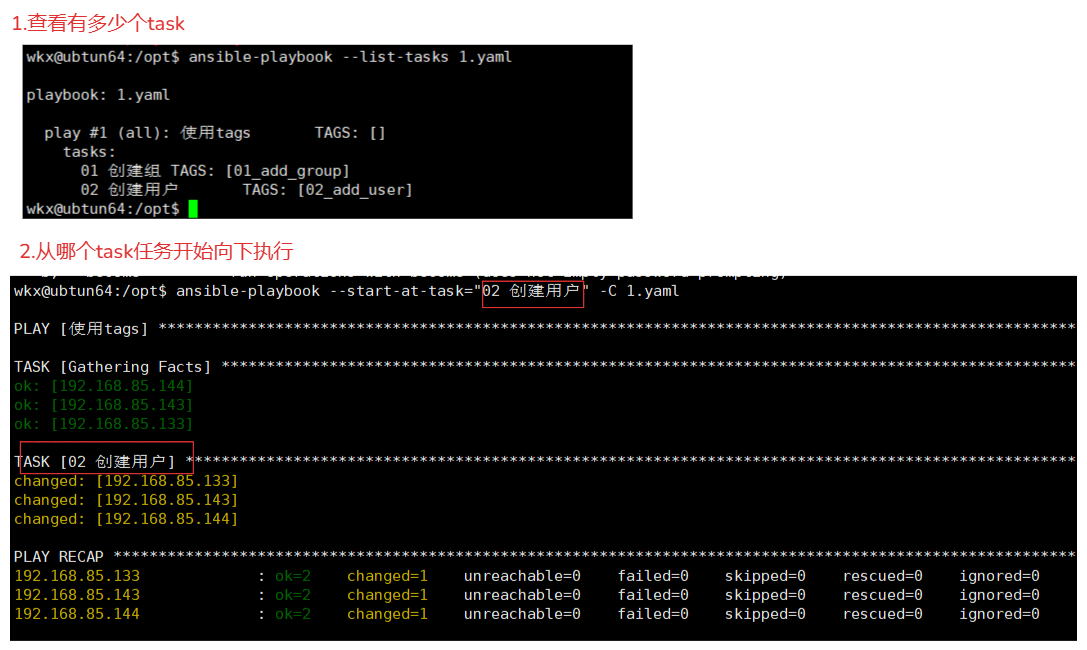
1.查看剧本有多少个task(任务)
ansible-playbook --list-tasks 1.yaml
2.可以从那个task开始执行 # 与tag的使用方式相同
ansible-playbook --start-at-task="02 创建用户" -C 1.yaml
4.ansible的Roles
解决的问题:
- 把单个的大剧本,拆分为小剧本,便于维护,修改、使用。
- 完成解耦、结构更清晰、调试更方便,在实际的工作当中,一个完整的项目实际上是很多功能体的组合,如果将所有的功能写在一个playbook中会存在如代码耦合程度高、playbook长而维护成本大、灵活性低等一系列的问题。
- 使用roles能巧妙的解决这一系列的问题。roles是ansible1.2版本后加入的新功能,适合于大项目playbook的编排架构。
介绍:
- role、角色用于层次化、结构化的组织多个playbook。
- role主要的作用是可以单独的通过一个有组织的结构、通过单独的目录管理如变量、文件、任务、模块、以及处理任务等,并且可以通过include导入使用这些目录。
- roles主要依赖于目录的命名和摆放,默认tasks/main.yml是所有任务的人口,使用roles的过程也可以认为是目录规范化命名的过程。
- roles每个目录下均由main.yml定义该功能的任务集,tasks/main.yml默认执行所有定义的任务,roles目录建议放在ansible.cfg中”roles_path”定义的目录下。
/etc/ansible/ansible.cfg #roles_path = /etc/ansible/roles简单理解:
- 将playbook脚本进行拆分多个小型脚本的总和,类似于一个项目一样,完成解藕,方便调试。如果是简单的脚本直接使用命令或者playbook即可,需要根据需求而定。
**官方文档:**https://docs.ansible.com/ansible/latest/playbook_guide/playbooks_reuse_roles.html
4-1.加载过程
例如入口文件"my_role.yaml"加载角色内容:
1.找到 my_role 目录后,Ansible 会加载该目录下的内容,包括:
2.tasks/main.yml:角色的任务入口文件,定义了角色的主要任务。
3.vars/main.yml:角色的变量文件,定义了角色使用的变量。
4.defaults/main.yml:角色的默认变量文件,定义了可覆盖的默认变量。
5.handlers/main.yml:角色的 handlers 文件,定义了角色中使用的 handlers。
6.meta/main.yml:角色的元数据文件,定义了角色的依赖关系和其他信息。
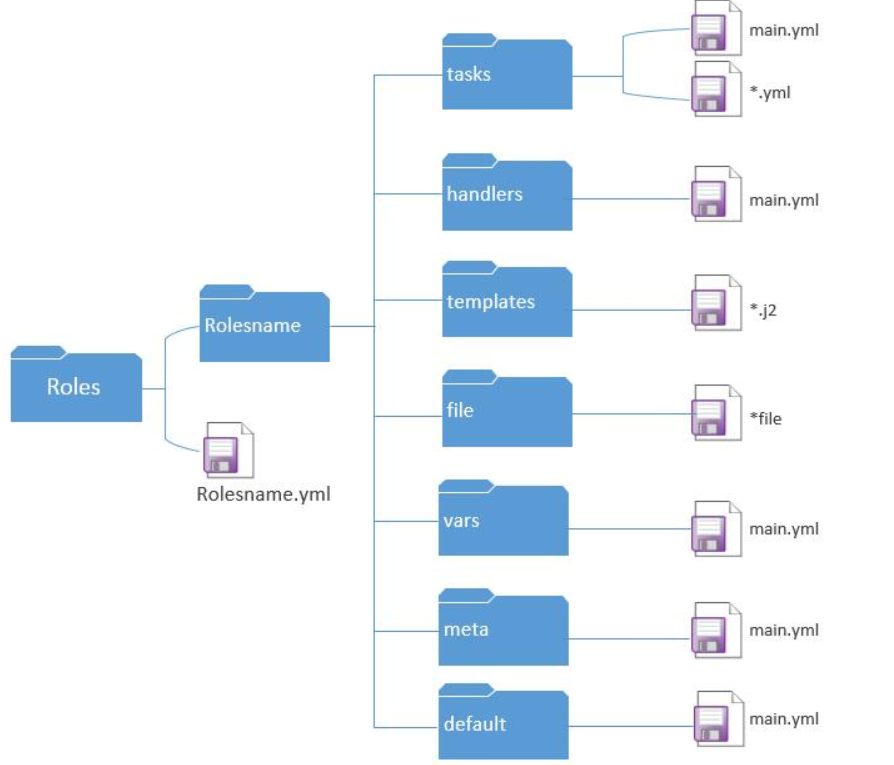
4-2.目录结构
| 目录 | 说明 |
|---|---|
| role_name/ | 角色的名称,简单的声明表名当前功能。 |
| role_name/tasks/ | 存放任务列表文件(.yml 文件),main.yml:这是任务列表的入口文件,定义了角色需要执行的任务。其他任务文件可以通过 include 或 import_tasks 指令引入。可以将任务拆分到不同的文件中,例如 install.yml、config.yml 等,然后在 main.yml 中引用。 |
| role_name/vars/ | 存放角色的变量定义。定义了角色所需的默认变量。这些变量可以在 playbook 中被覆盖或扩展。可以按功能或环境拆分变量文件,例如 vars/dev.yml、vars/prod.yml 等。 |
| role_name/defaults/ | 存放角色的默认变量。定义了角色的默认变量,这些变量可以在 vars/ 中被覆盖。默认变量通常用于提供一些可选的配置选项。 |
| role_name/meta/ | 定义了角色的依赖关系、平台支持、角色作者等信息。例如,可以在这里声明角色依赖的其他角色。 |
| role_name/files/ | 存放需要传输到目标主机的文件。这些文件可以通过 copy 或 template 模块传输到目标主机上。 |
| role_name/templates/ | 存放 Jinja2 模板文件。这些模板文件可以通过 template 模块渲染并生成配置文件,其中可以包含变量和条件逻辑。 |
| role_name/handlers/ | 存放 handler 定义。定义了角色中需要使用的 handlers,例如服务的重启、服务的重新加载等。Handlers 通常由任务中的 notify 指令触发。 |
| role_name/tests/ | 存放测试用例和测试脚本。inventory:测试用的主机清单文件。test.yml:测试 playbook,用于验证角色的功能是否正常。 |
| playbooks/* | 存放主要的启动文件。整个role的入口文件。 |
/etc/ansible/roles/
role_name/ # 代表当前的一个role
├── tasks/
│ ├── main.yml
│ ├── install.yml
│ └── config.yml
├── vars/
│ └── main.yml
├── defaults/
│ └── main.yml
├── meta/
│ └── main.yml
├── files/
│ └── somefile.txt
├── templates/
│ └── someconfig.j2
├── handlers/
│ └── main.yml
└── tests/
├── inventory
└── test.yml
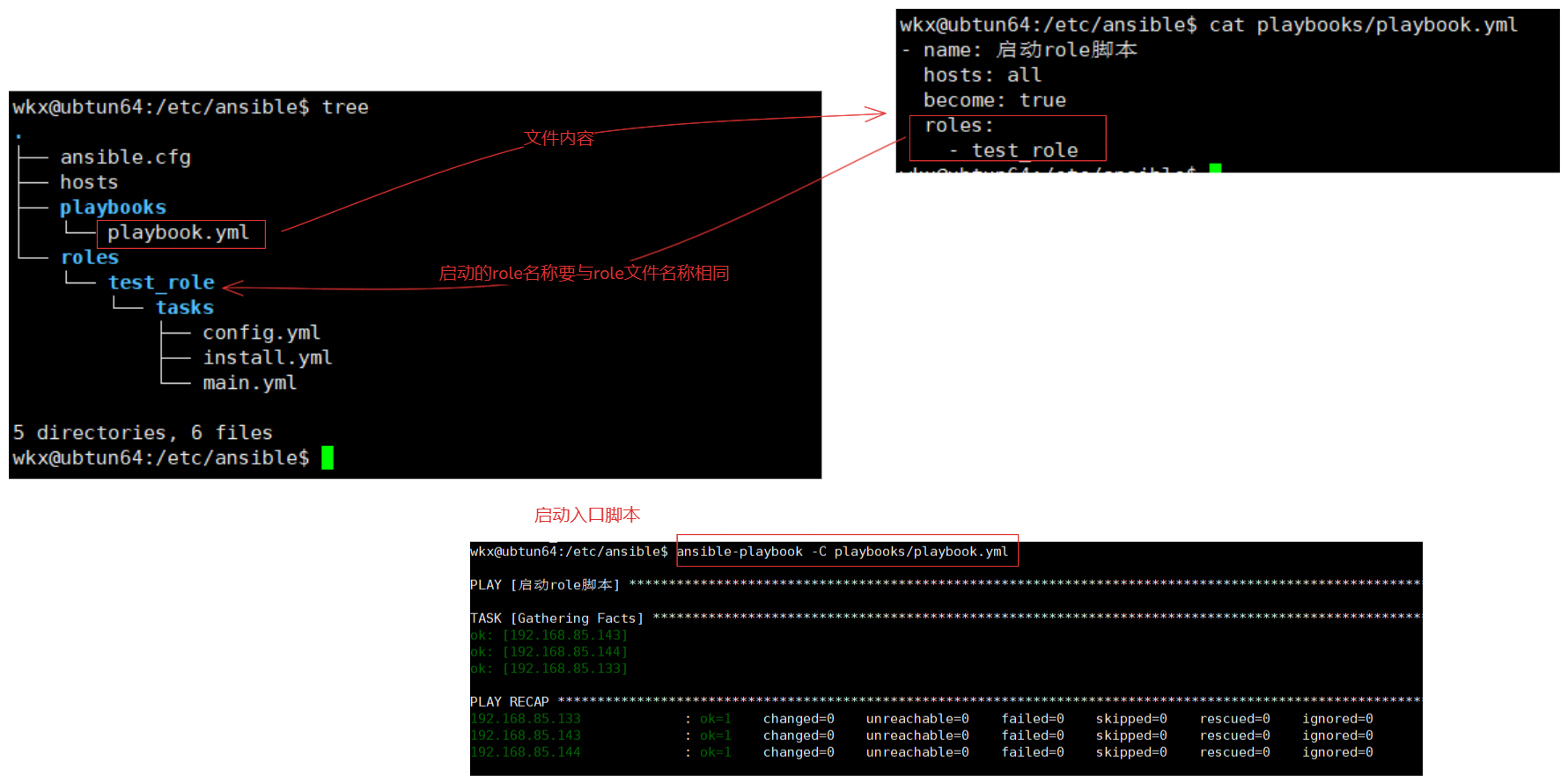
/etc/ansible/roles/
playbooks/
│ ├── playbook.yml # 作用:启动任务的核心文件,一般放到与role项目同级的位置。
4-3.入口文件
# 说明:
1.也就是当前role角色的主要的启动执行文件。
2.一般存储到与roles文件夹同级,或者存放到一个playbooks文件中。
3.这个文件名称允许自定义,但是需要见名知意。
3.入口文件的关键字内容
vim playbook.yml
- name: 说明
hosts: 主机清单
become: true # 特权执行。
roles: # 角色列表,可以调用多个
- 角色目录名称 # 要与创建的角色目录一致。
2.启动:
ansible-playbook playbook.yml
4-4.tasks文件夹
tasks文件夹:
是role角色中负责执行模块任务的一个重要文件夹,一般情况下,可以将全部执行的任务存放在tasks文件夹下。
# 例如:当前结构
/etc/ansible/roles/
└── test_role
└── tasks
├── config.yml
├── install.yml
└── main.yml # 主要执行文件
# 如果将main.yaml文件中的任务拆分到不同的文件中怎么实现引用:
import_tasks 或 include_tasks 指令来引入其他任务文件。 # 如同编程语言的导包一个性质
import_tasks:
在解析阶段加载任务文件的内容,任务文件中的任务会成为 main.yml 的一部分。适合静态任务的引入。
include_tasks:
在运行时动态加载任务文件的内容。适合根据条件动态加载任务。
# 如果不需要动态加载任务,推荐使用 import_tasks。
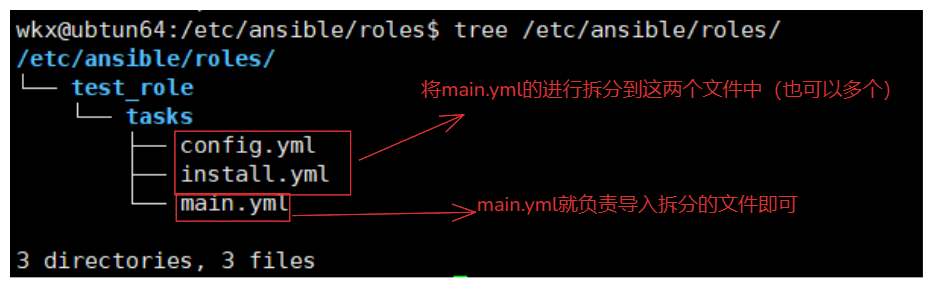
4-4-1.config.yml
# role_name/tasks/config.yml
- name: 配置nginx
copy:
src: /opt/test.conf
dest: /etc/nginx/conf.d/test.conf
backup: yes
- name: 启动nginx
systemd:
name: nginx
state: started
4-4-2.install.yml
# role_name/tasks/install.yml
- name: 安装nginx
yum:
name: nginx
state: present
4-4-3.main.yml
# role_name/tasks/main.yml
- name: 导入 install.yml
import_tasks: install.yml
- name: 导入config.yml
import_tasks: config.yml
4-5.vars文件夹
vars文件夹:
文件夹用于存储与角色相关的变量定义。这些变量可以在角色的任务、模板或其他部分中使用。
默认情况下,Ansible 会加载 vars/main.yml 文件中的变量。这些变量的优先级较高,可以在角色的任务中直接使用
# 例如:当前结构
/etc/ansible/roles/
└── test_role
└── vars
├── config.yml
├── main.yml
# 变量定义:
# roles/test_role/vars/main.yml
定义方式:
变量名称: 变量值
例如:
nginx_config_file: "/etc/nginx/nginx.conf"
注意事项:
vars/main.yml 中的变量优先级较高,会覆盖 defaults/main.yml 中的默认变量。
如果在 Playbook 中通过 vars 或 vars_files 定义了同名变量(关键字),则会覆盖 vars/main.yml 中的变量
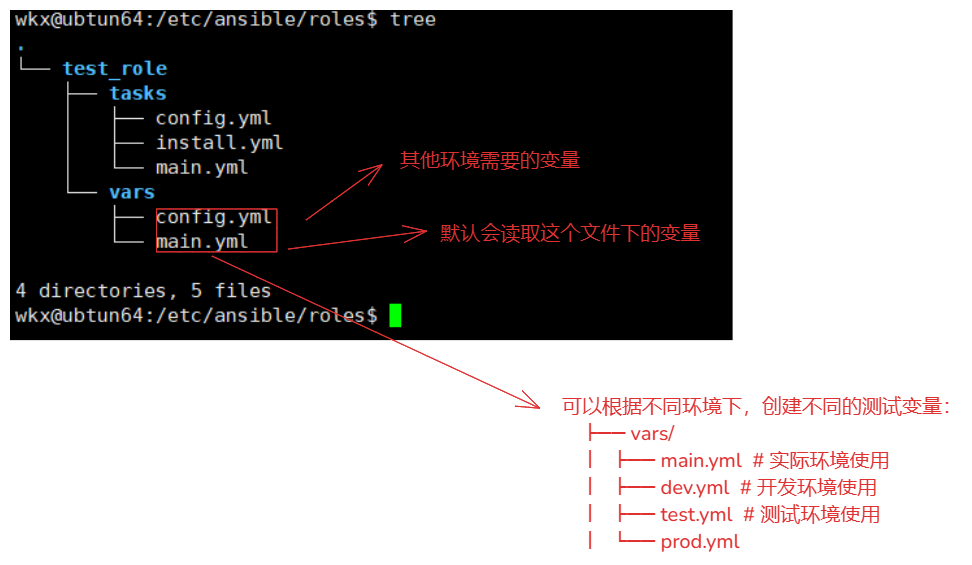
4-5-1.config.yml
# roles/test_role/vars/config.yml
nginx_port: 80
nginx_config_file: "/etc/nginx/conf.d/"
4-5-2.main.yaml
# roles/test_role/vars/main.yml 默认的情况下会读取vars/main.yml的变量
nginx_port: 9090
nginx_config_file: "/etc/nginx/nginx.conf"
4-5-3.怎么使用这个变量
# roles/test_role/tasks/main.yml
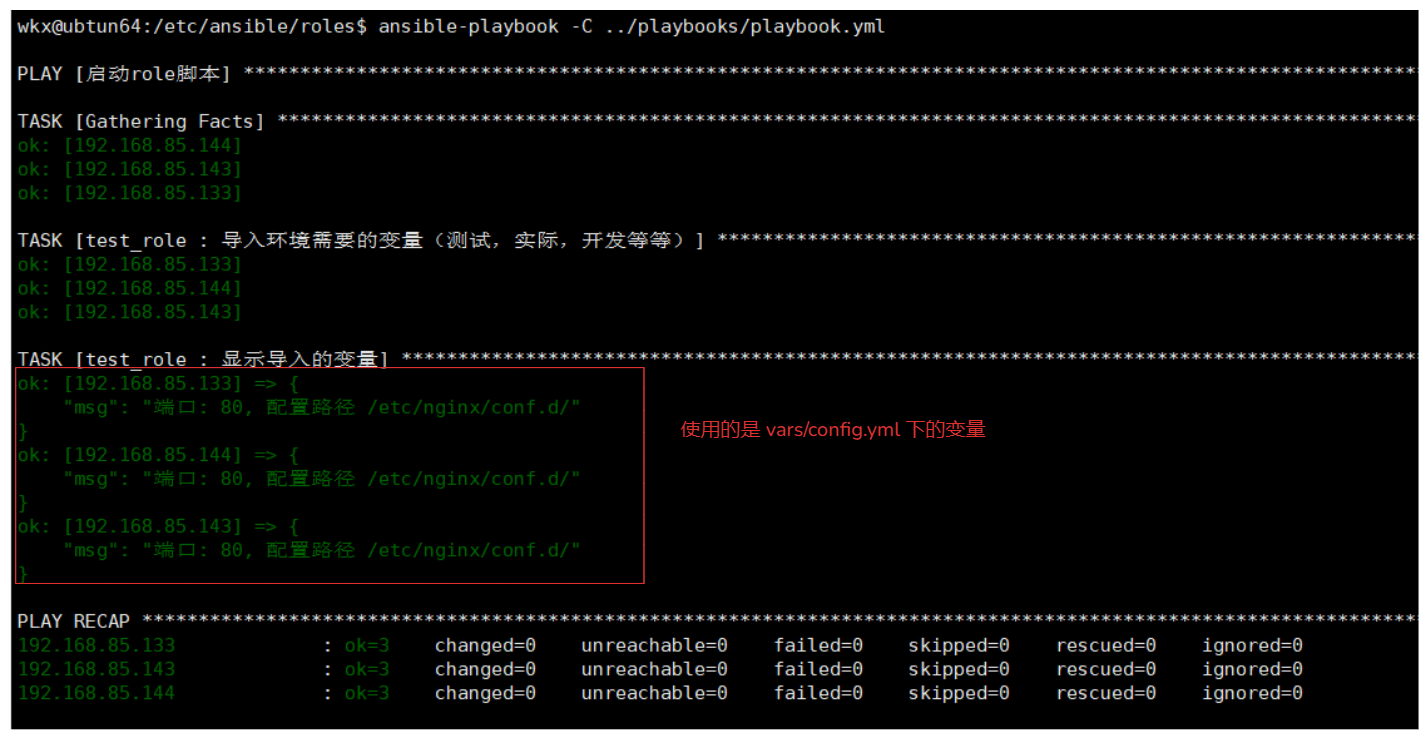
- name: 导入环境需要的变量(测试,实际,开发等等,根据需求进行导入需要的变量文件)
include_vars: vars/config.yml
- name: 显示导入的变量
debug:
msg: "端口: {{ nginx_port }}, 配置路径 {{ nginx_config_file }}"
4-5-4.动态使用不同环境的变量
1.目录结构
roles/
└── my_role/
├── vars/
│ ├── main.yml
│ ├── dev.yml
│ ├── test.yml
│ └── prod.yml
├── tasks/
│ └── main.yml
2.在入口文件中设置一个全局变量
- hosts: webservers
vars:
env: dev # 或者 prod、test 等
roles:
- my_role
3.使用动态导入变量
# roles/my_role/tasks/main.yml
- name: 根据不同环境导入变量
include_vars: "vars/{{ env }}.yml" # env 就是引用了入口文件的这个变量,只需要修改入口的env的值就可以实现动态更改环境
- name: 显示导入的变量
debug:
msg: "端口: {{ nginx_port }}, 配置路径 {{ nginx_config_file }}"
4-6.defaults文件夹
defaults文件夹,主要作用就是用来定义默认变量,但是这个变量会被 vars tasks templates 文件定义的变量覆盖,也就是defaults文件夹定义的变量权重低。
例如文件结构
/etc/ansible/roles/
└── test_role
└── defaults
├── main.yml
4-6-1.main.yaml
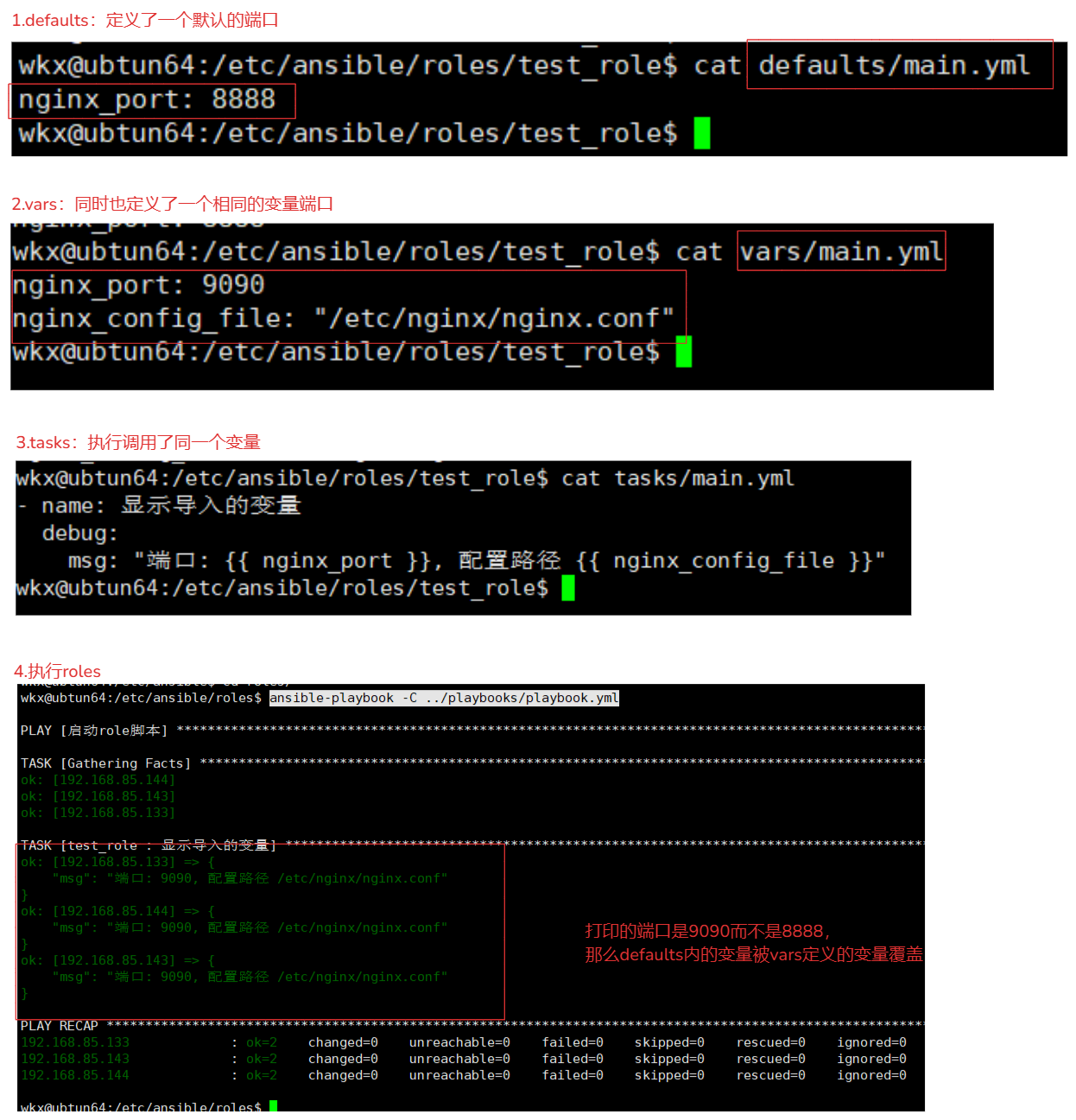
# roles/test_role/defaults/main.yml 默认的情况下会读取defaults/main.yml的变量
nginx_port: 8888
而vars/main.yml同时声明了这个变量
tasks/main.yaml调用了这个变量
执行:ansible-playbook -C ../playbooks/playbook.yml
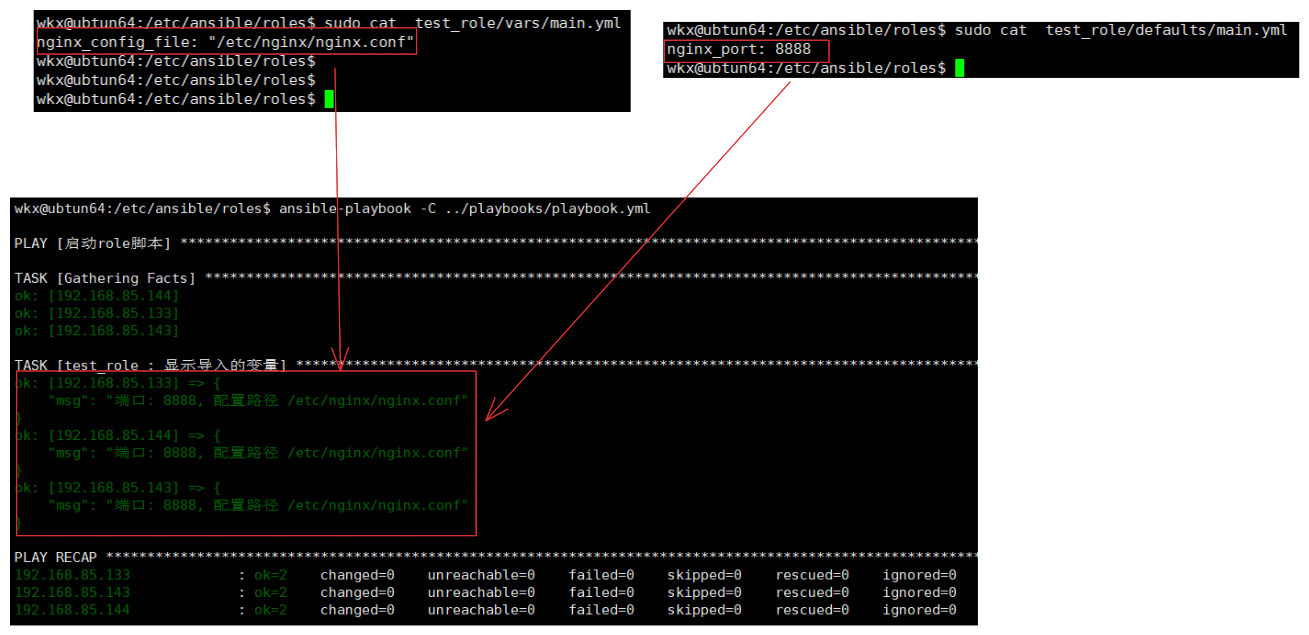
4-6-2.特点
特点:
1.默认变量的优先级较低,这意味着它们可以被用户在更高优先级的地方(如 vars 文件夹、命令行参数、inventory 文件等)覆盖。
2.它们是角色的“备用”配置,为用户提供了一个易于修改的起点。
# 如同上面的案例:
当删除掉 vars/main.yaml 的 nginx_port: 9090 变量后才会读取defauts/main.yml的变量。
4-7.meta文件夹
作用:
文件夹的作用主要体现在角色(Role)的元数据管理和依赖关系定义上。
meta 文件夹用于存放角色的元数据信息,其中最常见的是 main.yml 文件。它主要用于定义角色的依赖关系和其他元数据
例如文件结构
/etc/ansible/roles/
└── test_role
└── meta
├── main.yml
4-7-1.常用字段
| 关键字 | 作用 |
|---|---|
| galaxy_info | 是一个字典,用于定义角色的元数据,这些信息在 Ansible Galaxy 上显示角色详情时会用到。 |
| author | 角色的作者 |
| description | 角色的简短描述。 |
| company | 作者公司 |
| license | 许可证书类型 |
| min_ansible_version | 角色需要使用ansible的最低版本 |
| platforms | 支持的操作平台 |
| categories | 角色所属的分类 |
| tags | 角色的标签,用于搜索和分类。 |
| dependencies | 角色的依赖关系(当执行当前角色时,会优先按照这个依赖关系先执行关系中的角色脚本)。 |
| role_name | 角色的名称 |
| version | 定义的版本 |
| namespace | 命名空间它主要用于在 Ansible Galaxy 上发布和管理角色时,帮助区分不同作者或组织发布的角色,避免命名冲突。 |
4-7-2.main.yml
# test_role/meta/main.yml
# 不仅仅可以优先执行当前文件定义的角色同时还可以存储一些源数据
galaxy_info:
author: John Doe
description: A role to deploy a basic web server
company: Example Inc.
license: MIT
min_ansible_version: 2.9
platforms:
- name: EL
versions:
- all
- name: Ubuntu
versions:
- all
categories:
- web
- server
tags:
- web
- nginx
- httpd
dependencies:
- { role: nginx }
- { role: python }
role_name: my_web_server
version: 1.0.0
namespace: my_namespace
4-7-2.Galaxy是什么
类似于和github一样的远程管理仓库。
1.github管理代码的
2.galaxy是管理ansible的角色脚本的。
官方网站:
https://galaxy.ansible.com/
命令行工具
ansible-galaxy
对应的指令:
ansible-galaxy install <role_name> # 安装角色
ansible-galaxy collection install <collection_name> # 安装集合
ansible-galaxy search <role_name> # 搜索角色
ansible-galaxy info <role_name> # 查看角色信息
可以通过 requirements.yml 文件列出和管理角色或集合的依赖
requirements.yml
roles:
- geerlingguy.nginx
- geerlingguy.mysql
collections:
- community.general
ansible-galaxy install -r requirements.yml # 运行指令
4-8.files文件夹
作用:
用于存放需要传输到目标主机的静态文件。
例如文件结构
/etc/ansible/roles/
└── test_role
└── files
├── 文件1.txt
├── 文件2.txt
4-8-1.怎么使用files中的静态文件
例如:
tasks/main.yml
- name: 对远程节点发送静态文件
copy:
src: 文件1.txt # 源文件路径,相对于 files 文件夹
dest: /opt/文件1.txt # 目标路径
backup: yes

4-9.templates文件夹
作用:
用于存放jinja2的模版文件,可以在运行ansible角色时被渲染
例如文件结构
/etc/ansible/roles/
└── test_role
└── templates
├── example.conf.j2
4-9-1.例如:example.conf.j2
# /defaults/main.yml
port: 80
server_name: "default.example.com"
site_name: "default_site"
# /tasks/main.yml
- name: Render and deploy example.conf
ansible.builtin.template:
src: example.conf.j2 # 源模板文件路径,相对于 templates 文件夹
dest: /etc/nginx/example.conf # 目标路径
vars:
port: 80
server_name: example.com
site_name: mysite
# templates/example.conf.j2
server {
listen {{ port }};
server_name {{ server_name }};
location / {
root /var/www/{{ site_name }};
index index.html;
}
}
# 注意:
{{ port }} 或者 {{ server_name }} 或者 {{ site_name }} 是可以在 vars/main.yml 或者 defaults/main.yml 或者是在脚本本身定义vars中获取这个变量。
4-10.handlers文件夹
作用:
handlers 是一种特殊的任务列表,通常用于在特定事件发生时执行某些操作,例如重启服务或重新加载配置。
1.handlers 通常用于在任务执行后根据条件触发操作,例如当配置文件更新后重启服务。它们只在被通知时运行,避免了不必要的重复执行。
2.在角色中定义的 handlers 不仅可以在角色内部使用,还可以被其他角色或任务通知。
3.如果多个角色定义了同名的 handlers,可以通过 角色名:handler名 的方式显式指定通知
例如文件结构
/etc/ansible/roles/
└── test_role
└── handlers
├── main.yml
4-10-1.main.yml
# handlers/main.yml 声明
- name: restart my_service
ansible.builtin.service:
name: my_service
state: restarted
# tasks/main.yml
- name: Update configuration file
ansible.builtin.copy:
src: my_config.j2
dest: /etc/my_service/config.conf
notify: restart my_service # 调用
5.ansible的优化方案
1.减少ssh链接开销
pipelining = True
2.减少频繁建立的时间
ssh_args = -o ControlMaster=auto -o ControlPersist=60s
3.设置并发任务数量
forks = 20
4.禁止收集主机的facts信息
gathering = smart # Ansible 会根据目标主机是否已经收集过 Facts 来决定是否重新收集。
gathering = explicit # 不会主动收集,除非在play中显式声明(gather_facts: yes)
gathering = implicit # 默认值。Ansible 会在每个 Play 的开始自动收集 Facts,除非在 Play 中显式禁用(gather_facts: no)