Shell编程
1.Shell编程是什么
它是一中在linux系统或者unix系统中的脚本语言(编程语言),shell脚本它是一种小型的程序。主要可以执行组成的命令,通常在系统中进行自动化操作任务:文件操作,程序操作,文本处理等。
特点:
- 自动化:自动执行后,无需人工干预(比如shell脚本+crontab定时器)
- 可重用:写好后保存,可以进行重用
- 可移植:可以在不同的unix和linux中进行使用,因为需要的命令是相似的,在一定程度具有可移植
- 易于编写:比较传统的编程语言来说,比较简单,容易看懂
Shell编程就是利用Bash(或其他Shell)提供的命令和功能来编写自动化脚本: Bash会在用户登录时候自动启动,如果是虚拟控制台终端登录,命令行界面(英語:Command-Line Interface,缩写:CLI)提示符会自动出现,此时可以输入shell命令。或者是通过图形化桌面登录Linux系统,你就需要启动GNOME这样的图形化终端仿真器来访问shell CLI。 比如: 当用户进行登录时bash解释器就会自动启动,当用户输入一条命令时(pwd,那么一定会输入当前用户所在的目录),解释器就会进行输出结果。
脚本是什么: 特定的格式 + 特定的语法 + 系统命令 + 文件数据 = 脚本
2.什么是编程语言
计算机的发明,是为了用机器取代与解放人力,而编程的目的则是将人类的思想流程按照某种能够被计算机识别的表达方式传递给计算机,从而达到让计算机能够像人脑/电脑一样自动执行的效果。
比如:需要知道在
172.16.1.0/24网段中有多少台机器存活。
172.16.1.0/24就是254个ip就是响应的机器,可以通过pind命令 + w参数进行操作确定是否存活:ping -w 172.16.1.1- 如果通过命令一个一个来测试的情况下非常慢,可以通过编程脚本,通过一个循环进行完成。
编程的目的:
- 将复杂的东西简单化,通过编程的语言,无论是解释性还是编译性,将代码交给计算机,让它帮我们完成实现。
编程分类:
- 解释性:python shell,需要通过解释器运行。
- 编译性:go,java,c等,不需要号解释器,直接就能使用,但是前提是需要提前编译好。
虽然脚本语言,解释器型,意思无需进行变,直接用解释器就可以运行,虽然代码内部依然是一堆人类可以写的英文,计算机想要执行这个代码,底层会将这个代码做编译,转为2进制的数据,计算机的cpu才会识别,执行。
2.1.解释性与编译性的区别
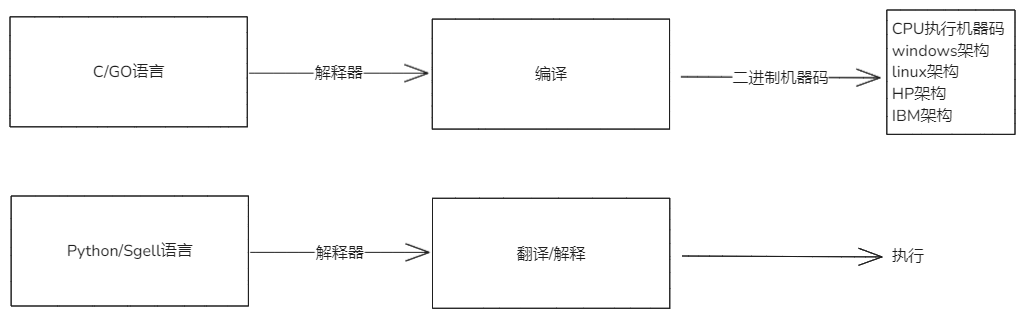
编译性: 1) 二进制执行速度快,直接编译成为机器码,cpu直接就可以执行,将源代码变为机器码,这个过程非常的慢,但是一次编译终身受益。 2) 依赖平台架构,各个平台架构不同,是不能通用的。 3) 保护源代码,编译成为机器码,只有机器读懂。 4) 底层工具,操作系统,超大的应用,高并发应用,都是使用编译性语言开发的。
解释性:
- 跨平台好,比如python,可以在不同的linux下进行运行,但是需要安装解释器。
- 执行较慢(相对与计算机而言),整个过程:源码 -> 解释器 (翻译为机器码)-> cpu执行,整个流程较慢,每一次执行都会将代码
自上而下的解释为机器码,让cpu执行。- 源码暴漏在外面,只要会这门语言的人都能看懂,那么就会根据你的源码分析进行攻击。
- 适合开发各种脚本,对于性能速度求不太高,比如网站开发。
3.Shell与运维的关系
shell是一种非常适合处理文本数据,且linux的概念是一切皆文件(比如日志,进程文件,配置文件,网页文件)都是文件,那么就可以和好的进行处理。
shell可以将一些命令放在一个文件中进行执行。 shel可以进行声明变量,函数,循环,判断等
能为运维人员解决哪些问题:
- 初始化防火墙,ssh配置,配置文件,网卡,基础软件等等
- 定时备份数据库操作等
- nginx的日志文件切割
- 服务启停脚本 nginx 或者 mysql
- 代码上线,通过脚本将代码打包防止到某个文件夹下
- 开发一些便携性脚本,比如跳板机。
优势:
- 更为贴切linux底层,直接使用linux的命令即可,效率高,适用于处理偏向操作系统底层的脚本。
- 对于常见的脚本使用shell更为轻巧,比如:一键部署nginx集群,系统内核优化,服务器启动脚本,日志分析脚本等等。
- 虽然其他的语言也可以,但是需要学习成本,开发效率,比如通过python管理系统模块去写脚本成本高效率也不是很快,不如直接使用linux命令操作方便。
- 对于基本的系统维护需求,用shell脚本会更符合易用、快速、高效的原则,shell用来对linux操作最为简单。
4.Shell语法规则
规则:
- shell脚本要做到见名知意,正式的脚本,别瞎写 ”a.sh“ ”b.sh“ 一定要见名知意,名字不要瞎起,看到名字就知道脚本的作用。
- 虽然脚本是文本类型,但是建议以.sh结尾。vim也能提供颜色支持。
- 给脚本加上注释,包括了脚本的创建时间,作者,作用等信息。
- 创建好可以管理你脚本的目录,别乱放,回头找不到。
#!/bin/bash解释:
#!:(被称为 shebang 或者 hashbang)是一种特殊构造,对与脚本语言非常重要,位于脚本的第一行,告诉系统使用哪个解释器执行当前脚本。/bin/bash:使用哪个解释器。
# 这是一个简单的Shell脚本
#!/bin/bash
# #!/bin/bash:是一个称为shebang的特殊构造,作用是告知系统需要使用哪个解释器
echo "Hello, World!"
echo "当前日期是 $(date)"
# 检查是否有命令行参数传入
if [ $# -eq 0 ]; then
echo "没有参数传入"
else
echo "传入的参数是 $1"
fi
这个脚本作用就是打印hello,world 打印当前日期,判断是否传入位置参数。
5.vim插件修改
1. 添加文件
touch ~/.vimrc # 当前配置文件默认是不存在的,需要创建
2.将内容写入 ~/.vimrc文件中即可
syntax on
set nocompatible
"set number
"filetype on
"set history=1000
"set background=dark
""set autoindent
"set smartindent
"set tabstop=4
"set shiftwidth=4
"set showmatch
"set guioptions-=T
"set ruler
"set nohls
"set incsearch
""set fileencodings=utf-8
if &term=="xterm"
set t_Co=8
set t_Sb=^[[4%dm
set t_Sf=^[[3%dm
endif
function AddFileInformation()
let infor = "#!/bin/bash\n"
\."\n"
\."# ***************************************************************************\n"
\."# * \n"
\."# * @file:".expand("%")." \n"
\."# * @author:作者是谁 \n"
\."# * @date:".strftime("%Y-%m-%d %H:%M")." \n"
\."# * @version 1.0 \n"
\."# * @description:写入描述信息 \n"
\."# * @Copyright (c) all right reserved \n"
\."#* \n"
\."#**************************************************************************/ \n"
\."\n"
\."\n"
\."\n"
\."\n"
\."exit 0"
silent put! =infor
endfunction
autocmd BufNewFile *.sh,*.py,*.go,*.php call AddFileInformation()
3.当创建文件时,就会出现一下图片上显示的提示信息。

4-1.vim样式部分
作用: 定义vim编辑器的外观
syntax on
set nocompatible
"set number
"filetype on
"set history=1000
"set background=dark
""set autoindent
"set smartindent
"set tabstop=4
"set shiftwidth=4
"set showmatch
"set guioptions-=T
"set ruler
"set nohls
"set incsearch
""set fileencodings=utf-8
if &term=="xterm"
set t_Co=8
set t_Sb=^[[4%dm
set t_Sf=^[[3%dm
endif
4.2.vim函数部分
AddFileInformation是一个函数,函数内部有一个变量infor。
silent put! =infor是一个命令,是将infor变量插入到当前编辑文件中。
endfunction标志代表AddFileInformation函数已经结束
autocmd BufNewFile *.sh,*.py,*.go,*.php call AddFileInformation()说明:
autocmd:这是定义自动命令的关键字。BufNewFile:这是一个自动命令事件,它在新建文件时触发。*.sh,*.py,*.go,*.php :匹配的文件后缀。call AddFileInformation() :调用函数。总结:当创建文件时匹配到
*.sh,*.py,*.go,*.php后缀的文件就会调用这个AddFileInformation函数,将变量infor的文本内容插入到新建文件中。
function AddFileInformation()
let infor = "#!/bin/bash\n"
\."\n"
\."# ***************************************************************************\n"
\."# * \n"
\."# * @file:".expand("%")." \n"
\."# * @author:作者是谁 \n"
\."# * @date:".strftime("%Y-%m-%d %H:%M")." \n"
\."# * @version 1.0 \n"
\."# * @description:写入描述信息 \n"
\."# * @Copyright (c) all right reserved \n"
\."#* \n"
\."#**************************************************************************/ \n"
\."\n"
\."\n"
\."\n"
\."\n"
\."exit 0"
silent put! =infor
endfunction
autocmd BufNewFile *.sh,*.py,*.go,*.php call AddFileInformation()
通过在 Vim 中输入 :help autocmd来了解更多关于自动命令的信息
6.Shell调试
命令:bash
参数:
-x 会将脚本的代码一行一行输入,可以进行调试。
-n 检查语法是否正常,不会执行脚本。
比如:一个123.sh的脚本
bash -x 123.sh # 就会将代码进行输出,可以查看执行的过程
bash -n 123.sh # 进行检查语法是否正常,如果正常就不会输入任何内容
456.sh脚本如下,当前脚本缺少一个引号:
#! /bin/bash
echo "asdasdas
echo "zzzzxxda$#"
执行 -n 检查语法时报错:
456.sh: line 2: unexpected EOF while looking for matching `"'
456.sh: line 6: syntax error: unexpected end of file
7.Shell变量
7-1.变量的说明
变量说明
- 变量有3大部分组成,变量名,赋值符号,变量值。
- 比如:
name='李强',那么变量名就:name,赋值符号:=,变量值:李强。- 注意:当进行声明变量时,不能在=左右存在空格。错误:
name = '李强',正确:name='李强',因为如果=左右有空格就会导致shell认为它是两个不同的参数,就会导致报错。变量命名规范
- 以字母开头,使用下划线做单词的连接,同类型的用数字区分。
- 对于文件名的命名最好在末尾加上拓展名(虽然linux中并没有对文件名称后缀进行强调,但是加上会更好区分。)。
- 注意,变量名=变量值,等号两边没有空格。
- 不要带有空格、?、*等特殊字符 ,不能使用bash中的关键字,例如if,for,while,do等,不要和系统环境变量冲突,如覆盖PATH,错误。
- 系统默认使用的变量,基本是完全大写的变量名。
变量参考写法
- 纯字母:name
- 全小写:my_name
- 驼峰法:My_Name
- 全大写:MY_NAME
变量
- 变:就是事务状态会发生变量。
- 量:记录事务的状态。
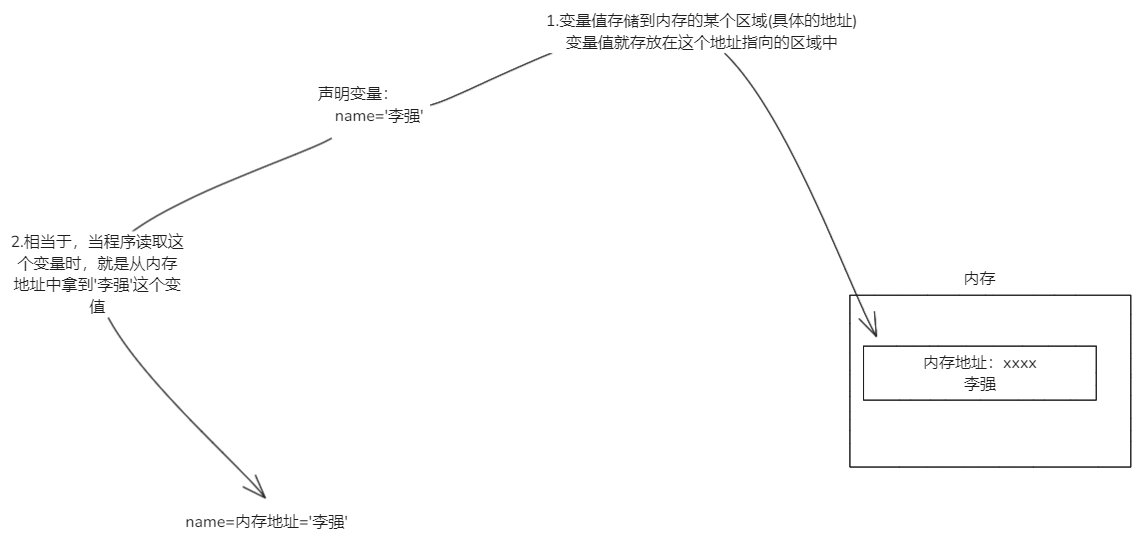
变量的本质
- 就是计算机中存取的一种机制。
- 变量的值存放在内存中。
为什么使用变量
- 程序的本质就是数据的不断变化,存取。
shell的变量是什么
- 不同的语言的都会使用变量,但是语法不同。
- 变量用于存、取数据,便于后续的反复使用。
程序
- 程序执行的本质就是一系列状态的变化,变是程序执行的直接体现。
- 需要有一种机制能够反映或者说是保存下来程序执行时状态以及状态的变化(例如一个变量,原本值是空字符串,接收用户输入的数据后,就存储了用户的数据)。
- 程序=数据+算法(逻辑功能)
当声明变量时,变量的值存放在内存中,而变量名则指向这个值所在的内存地址。变量名是一个引用符号。如下图:
7-2.环境变量加载文件顺序
- 登录ssh会话,加载全局配置文件
/etc/profile- 加载
~/.bash_profile个人用户配置文件- 加载
~/.bashrc个人用户bash配置文件- 加载
/etc/bashrc全局bash配置文件
/etc/profile作用:
全局变量以及别名和配置信息。
/etc/bashrc作用:
全局bash shell 配置
~/.bash_profile作用:
个人用户专属的变量和别名配置
~/.bashrc作用:
个人用户的bash配置
# 加载的顺序格努配置和使用shell不同而变化。
# .bash_profile文件
# Get the aliases and functions
if [ -f ~/.bashrc ]; then
. ~/.bashrc # 加载了bash个人配置文件
fi
# User specific environment and startup programs
PATH=$PATH:$HOME/bin
export PATH
# .bashrc文件
# User specific aliases and functions
alias rm='rm -i'
alias cp='cp -i'
alias mv='mv -i'
# Source global definitions
if [ -f /etc/bashrc ]; then
. /etc/bashrc # 加载了全局的bash配置
fi
. /etc/bashrc 为什么前面需要加入一个 . 如果不加会被尝试当做一个可执行文件执行,如果不是那么就会报错,而使用 . 命令,即使 /etc/bashrc 不是一个可执行文件,它的内容也会在当前 shell 会话中被执行。
7-3.变量的分类是什么
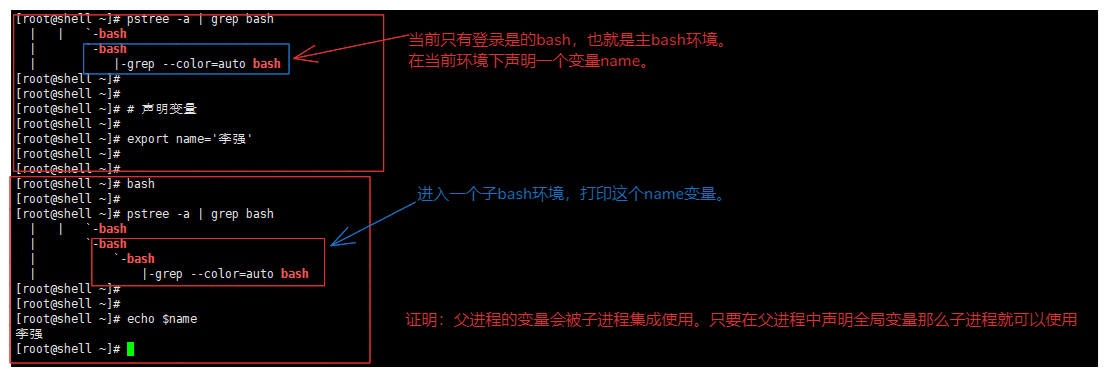
全局变量
- 就是在bash中定义的变量,那么脚本中是可以使用这个变量的(包含子bash),可以理解为在父进程中声明了一个变量,那么在当前父进程下的子进程可以使用这个变量。
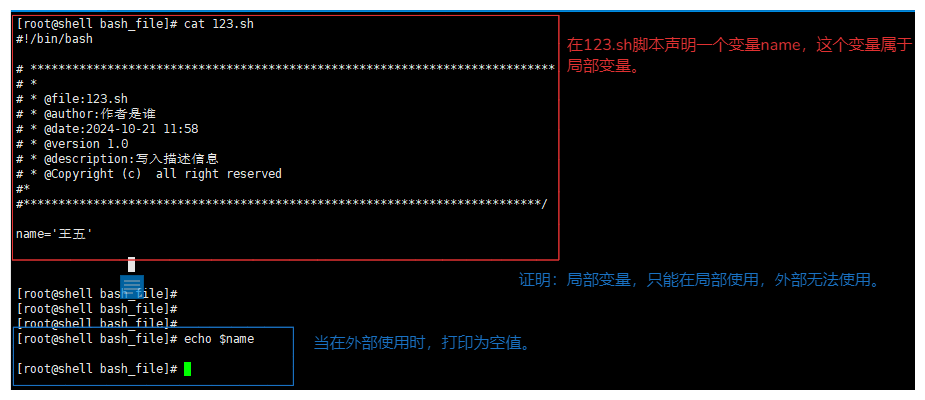
局部变量
- 比如说,在login.sh脚本中声明了一个name变量,那么这个变量只能在login.sh脚本或者,导入login.sh的其他sh脚本中使用这个变量,只能局部使用,全局无法使用。
变量周期
- 永久写入,写入到/etc/profile中或者写入~/.bash_profile文件中,这个变量不会消失。
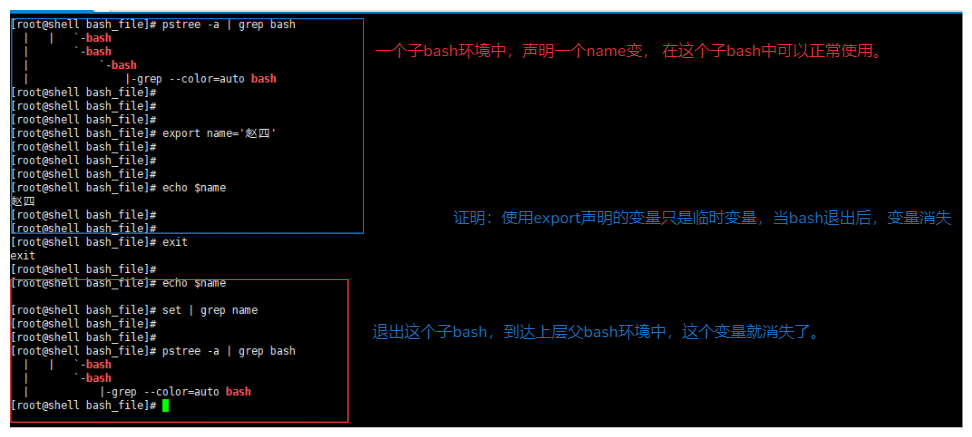
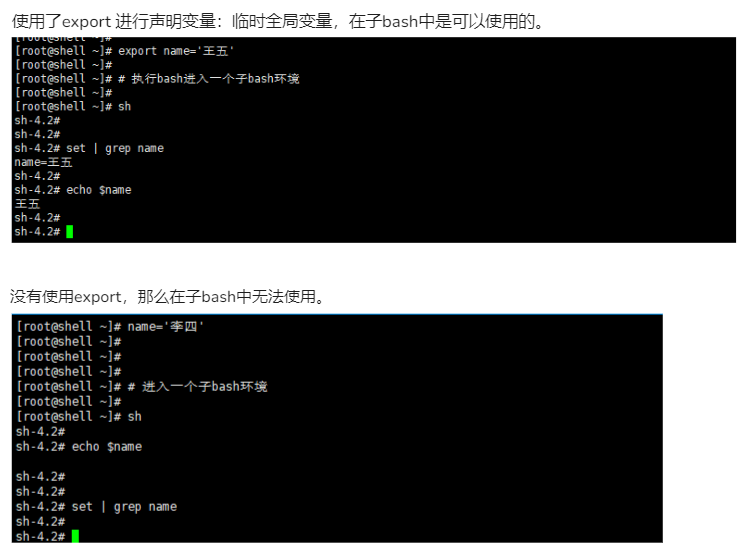
- 临时变量,使用export定义的临时变量,当关闭这个bash就会消失,如下图:。
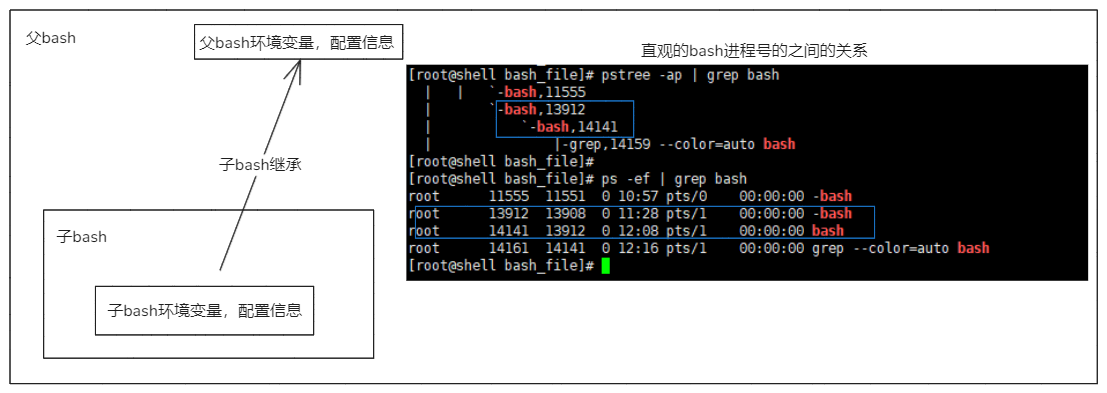
7-4.父子bash是什么
1.安装命令
yum install pstree -y
2.查看进程树
pstree -a | grep bash
# 就是这个样的。
[root@shell bash_file]# pstree -a | grep bash
| | `-bash
| `-bash
| |-grep --color=auto bash # bash内执行的查询命令
3.执行命令bash
[root@shell bash_file]# bash
[root@shell bash_file]# pstree -a | grep bash
| | `-bash
| `-bash # 父bash
| `-bash # 子bash
| |-grep --color=auto bash # 子bash执行的这条查询命令
# 解释
父子bash就是父子进程的关系,在ssh登录后加载的bash解释器的基础上,在执行命令bash,就会开启一个bash进程,这个进程是在原bash基础上的一个子进程,这就是父子bash的关系。这个子bash集成了父bash的全部的环境变量和配置,是一个独立的shell会话。
# 当子bash使用exit命令退出后,就会回到父bash中。
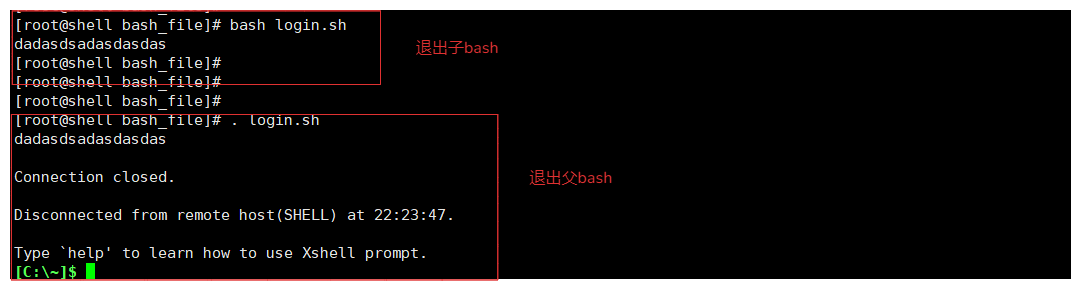
7-5.exit命令
作用:
退出当前的 shell 脚本或子 shell,当脚本调用它时,就会终止脚本的执行。
#!/bin/bash
echo "打印哈哈哈哈 $$"
exit 0
# 两种的不命令的执行方式
1.使用bash强制使用解释指定,使用bash执行脚本就会生成一个子bash进程,当做执行到exit就会退出子bash解释
bash log.sh
2.使用source或者.执行脚本,调用的时在用户ssh登录时自动加载的bash解释器(父bash)进程,执行脚本,执行到exit就会退出会话
source log.sh
为什么bash执行这个脚本与source执行的脚本会出现差别
1.bash执行脚本会在父bash中生成一个子bash,那么脚本中exit就是退出子bash。
2.source或 . 执行脚本,是在当前bash执行,exit就直接退出。
3.这个就是父子bash之间的关系问题,bash进程中产生子bash运行脚本,那么exit指令就会退出子bash,如果直接在bash进程中执行,那么就退出当前bash进程。
7-6.export命令
export作用:
声明一个临时的全局变量,当bash关闭后就会消失。
export命令与父子bash的关系极大。
1.export 声明的变量可以理解为 全局变量,无论在任何的子bash中都能使用。
2.不使用export 声明的变量属于局部变量,只能在父bash中使用,子bash无法使用。
7-7.引号的使用
引号分类
- 单引号
'',无法识别内部的特殊符号,无论定义什么内容都会找原样输出。- 双引号
"",识别特殊符号,会根据特殊符号输出内容化。- 反引号``,用于执行linux的命令,支持将命令结果赋值给变量。
$(),用于执行linux的命令,执行命令建议使用当前符,便于区分,支持将命令结果赋值给变量。${},用于提取变量的值,也就是变量值提取。引号区分
""双引号弱引用,可以加载内部特殊符号。''强引用,内部的符号意义全部取消。变量边界丢失问题
${变量名}可以简写为$变量- 因为可以简写的缘故会出现边界丢失问题,例如:
$name 111和$name111,程序会将$name111当做一个变量,而$name 111由于存在空格的原因,会将看做连个不同的值,一个变量name,一个111。建议不要进行简写变量提取符号,如果简写请将空格分开。
vim login.sh
#! /bin/bash
name='王五'
path=`pwd`
content="当前主机名称`hostname`,当前主机IP:$(hostname -I)"
echo '输入当前所在路径:$(pwd),当前使用的是单引号!'
echo "提取name变量:${name}"
echo "反引号:输入当前所在路径:${paht},当前使用的是双引号!"
echo "美元符号+小括号:输入当前所在路径:$(pwd),当前使用双引号!"
echo "${content}"
`` 与 $() 支持对命令结果进行复制给变量

7-8.变量修改与删除
1.变量修改
name='王五'
name='李四' # 将原来的变量进行覆盖重新赋值。
2.变量删除
name='王五'
set # 查询当前环境下全部的变量
unset name # 删除变量
7-9.变量传递与参数传递
1.接受脚本传递的位置参数
${0}:获取脚本的名称
${1},${2}...${n}:获取脚本的位置参数,第1个值...第N个值
${*}与${@}:获取全部的位置参数
${#}:获取位置参数的个数
$$:获取当前脚本执行的pid
$?:获取脚本内上一条执行结果,可以多次使用,非0就都是错误。
$!:一个后台运行的命令的进程pid
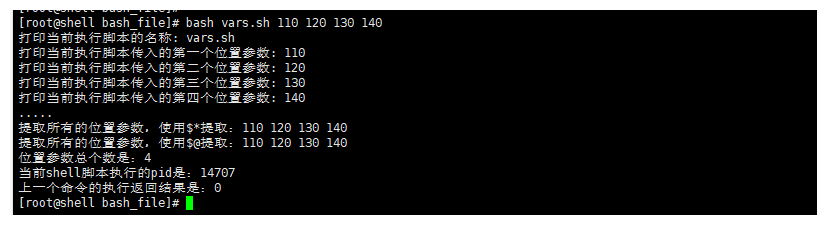
2.创建vars.sh脚本
#!/bin/bash
echo "打印当前执行脚本的名称: ${0}"
echo "打印当前执行脚本传入的第一个位置参数: ${1}"
echo "打印当前执行脚本传入的第二个位置参数: ${2}"
echo "打印当前执行脚本传入的第三个位置参数: ${3}"
echo "打印当前执行脚本传入的第四个位置参数: ${4}"
echo "....."
echo "提取所有的位置参数,使用\$*提取:$*"
echo "提取所有的位置参数,使用\$@提取:$@"
echo "位置参数总个数是:$#"
echo "当前shell脚本执行的pid是:$$"
echo "上一个命令的执行返回结果是:$?"
3.执行脚本
bash vars.sh 110 120 130 140
7-10.脚本传参的注意
- 位置参数是按照空格进行区分的。
- 如果传入的参数具有空格,那么请使用
"" or ''包裹参数。- 如果对应的位置参数没有传递,那么脚本对应的这个位置变量就是空。

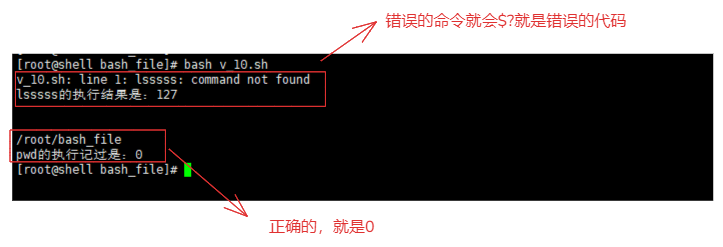
7-11.$?的用法
1.创建一个脚本,脚本中的内容。
#! /bin/bash
lsssss
echo "lsssss的执行结果是:$?"
echo
echo
pwd
echo "pwd的执行记过是:$?"
2.执行脚本,如下图,可以看出$?的作用就是获取上一条执行结果的代码是多少,非0错误。
7-12.${@}与${*}的用法
虽然
${@}与${*}都是提取全部的参数,但是它们提取的构造的数据结构不同。
${@}与${*}是存在区别的,虽然都是获取全部的位置参数,无引号的情况下结果是相同的,但是如果和引号结合就不同了。注意
${@}${*}都是接受不定长的位置参数 (不知道传入多少个位置参数,没办法进行固定接受)。- 在脚本中这俩特殊变量,必须加上双引号,才能发挥作用。
- 一般结合与for循环进行使用,找出者两个特殊存储的元素。
加引号区别
${*}将全部的传入的位置参数当做一个整体,让全部的参数融合成为一个大字符串。${@}将全部传入的位置参数,按照传入,当成每一个个体,可以区分每个元素。区别
${@}与${*}在无引号的状态下会将接受的参数通过for循环,将参数进行区分。"${@}"与"${*}"有引号状态下,"$*"会将位置参数全部的值当做一个整体,"${@}"区分每一个元素。
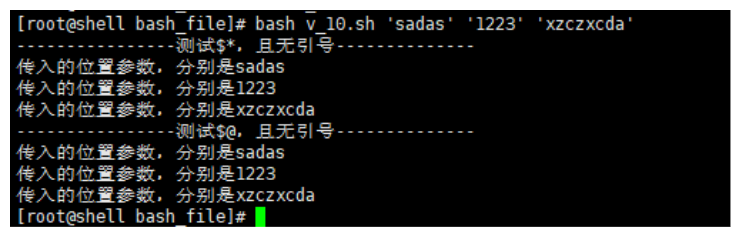
# 有引号的状态下 $@与$*的区别
#! /bin/bash
echo "----------------测试\$*,有引号--------------"
for v in "$*"
do
echo "传入的位置参数,分别是${v}"
done
echo "----------------测试\$@,有引号--------------"
for v in "$@"
do
echo "传入的位置参数,分别是${v}"
done
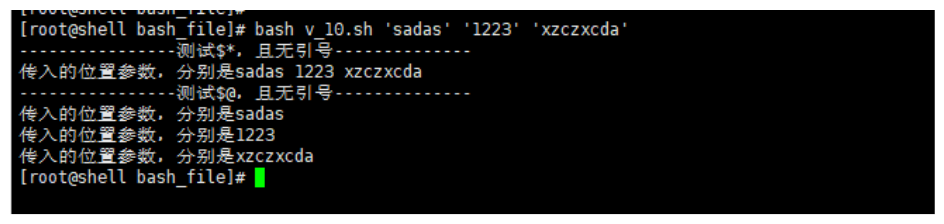
# 无引号的状态下
#! /bin/bash
echo "----------------测试\$*,且无引号--------------"
for v in $*
do
echo "传入的位置参数,分别是${v}"
done
echo "----------------测试\$@,且无引号--------------"
for v in $@
do
echo "传入的位置参数,分别是${v}"
done
7-13.read交互式命令
read命令作用:
是一个交互式的命令,可以让脚本与用户的数据进行交互。
用法:
read -p '提示信息' 变量 # 变量的作用接受用户执行脚本时输入的值,并且将值赋值给这个变量
参数:
-p 提示信息
-s 隐藏输入内容,比如输如密码时。
脚本:
#! /bin/bash
read -p '请输入的你的名字:' name
echo "当前脚本执行输入的名称为:${name}"

7-14.常量
固定不变的就是常量,而发生变化的就是变量
由于常量在shell中没有严格的语法支持,但是会有约定俗成的,就是使用大写的变量名称作为常量。
像身份证号码就可以作为常量,月份,年份,时间等都可以作为常量。
常量怎么声明:
使用linux中的readonly命令进行声明常量,声明过后,这个变量不可修改。
readonly name='王五' # 在进行修改就会报错
查看系统中自带的常量:
grep -RI '^readon.' /bin/ 进行查看
[root@shell bash_file]# grep -RI '^readon.' /bin/
/bin/dracut:readonly TMPDIR="$tmpdir"
/bin/dracut:readonly DRACUT_TMPDIR="$(mktemp -p "$TMPDIR/" -d -t dracut.XXXXXX)"
/bin/dracut:readonly initdir="${DRACUT_TMPDIR}/initramfs"

7-15.$!与$?与$$什么区别
1.$$
获取当前shell脚本的 pid(进程号),当脚本运行时,会调用一个bash环境(一个进程)执行当前的脚本,$$就是获取这执行进程的id值。
bash 123.sh,如果123.sh内打印了 $$ 情况下就会输出 执行 bash 123.sh 进程的pid值。如果脚本是作为一个独立的进程运行的(例如直接执行 ./123.sh),那么 $$ 将返回该脚本进程的PID。
2.$?
获取上一条命令的返回值
echo "xxxx" > /dev/null
echo $? # 就会获取上一条 echo "xxxx" > /dev/null 命令的最终执行结果。非0的情况下就是错误。
3.$!
获取上一条后台执行进程的pid。
sleep 10 &
echo $! # 这将输出最近一个后台运行的sleep命令的PID
比如:sleep 10 &
[root@template /]# sleep 10 &
[1] 3253
[root@template /]# echo $!
3253
7-16.变量总结
像:$$ $? $* $# $@ $! 这种属于特殊变量,不需要使用 {} 来引用,{}是为了防止正常声明的变量发生混淆。
比如:
echo ${var}123 表示变量 var 后面紧跟着数字 123,进行拼接。如果不是用 {} 的情况下就会变成 $var123,系统找的就是 var123 的这个变量。
cd ${dir}/subdir 路径拼接的方式,使用花括号可以防止路径被错误地分割。
如果非要使用{}来输出特殊变量:# 千万不要写错写成${$$} 。
${$} ${?} ${*} ${#} ${@} ${!}
8.Shell的数据类型
数据指变量的变量值
name='王五',那么王五就是数据,而这个值就是字符串类型。变量是用来反应、保持数据的状态,以及变化的,并且生活里,除了文字,还有整数,小数,等丰富的数据类型,需要我们通过计算机程序去表示。
数据类型的分类
- 数字
age=18- 字符串
name='王五'- 数组
students=("张三" "李四")- 关联数组类似于Python的字典,Java的Map结构。
- 小数类型
money=105.5静态于动态的区别
- 静态语言会进行对数据的严格区分,比如go语言
name string='xxxx'。- 动态语言不会对数据进行严格区分,可以随时切换,
name变量可以是字符串也可以被覆盖为整数。注意
- shell比较特殊,没有明确的数据类型
- 所有的数据都是以字符串的形式存储和处理的。这意味着,无论是数字、变量还是命令的输出,它们在Shell中都被当作字符串来处理。
9.Shell的运算方式
只有数字或者小数类型的才能进行运算操作。
1 or 1.1 or "1.1" or "1"支持的运算符号
- 加:
+ 、+= 、++- 减:
- 、-= 、--- 乘:
* 、*=(# 注意 * 在shell中有特殊作用,需要进行转义 * *=)- 除:
/- 取余 :
% 、%=支持运算的命令
expr整数运算*需要转义\*$(( ))整数运算$[]整数运算let整数运算,赋值运算bc支持整数,小数点运算*需要转义\*awk支持整数,小数点运算注意
- 支持整数,小数的类型,其他的类型不支持。
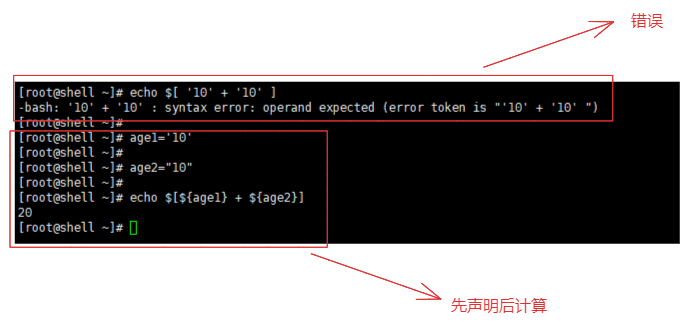
- 可以声明变量,但是不能再运算符号内直接使用
"10" 或者 '10',错误:"xxx"+"xxx"如下图所示。
9-1.expr计算
语法要求
- expr计算时,在运算符号两边必须有空格:
expr 1 + 1- 只能是整数,不能是小数。
常用的方式如下:
expr ARG1 + ARG2 # 相加
expr ARG1 - ARG2 # 相减
expr ARG1 * ARG2 # 相乘,需要使用\转义*号
expr ARG1 / ARG2 # 相除
expr ARG1 % ARG2 # 取ARG1的余数
语法:
expr 数字1 符号 数字2
expr 变量1 符号 变量2
# 脚本
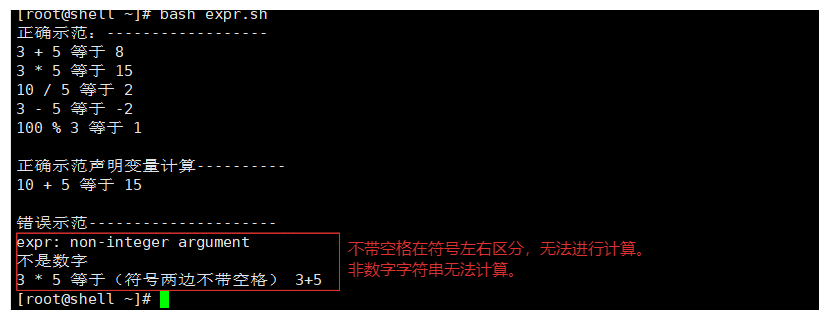
#! /bin/bash
echo "正确示范:------------------"
echo "3 + 5 等于 $(expr 3 + 5 )"
echo "3 * 5 等于 $(expr 3 \* 5 )"
echo "10 / 5 等于 $(expr 10 / 5 )"
echo "3 - 5 等于 $(expr 3 - 5 )"
echo "100 % 3 等于 $(expr 100 % 3 )"
echo
echo "正确示范声明变量计算----------"
num1=10
num2=5
echo "${num1} + ${num2} 等于 $(expr ${num1} + ${num2} )"
echo
echo "错误示范---------------------"
echo "不是数字 $(expr "sss" + 5 )"
echo "3 + 5 等于(符号两边不带空格) $(expr '3'+5 )"
9-2.$(( ))运算
语法要求
- 只支持整数
- 不能是带引号的整数,可以使用带引号的整数字符串变量比如:
age='10'可以计算
语法:
$(( 数字1 符号 数字2 ))
$(( 变量1 符号 变量2 ))
脚本
#! /bin/bash
echo "正确示范:------------------"
echo "3 + 5 等于 $(( 3 + 5 ))"
echo "3 * 5 等于 $(( 3 * 5 ))"
echo "10 / 5 等于 $(( 10 / 5 ))"
echo "3 - 5 等于 $(( 3 - 5 ))"
echo "100 % 3 等于 $(( 100 % 3 ))"
echo
echo "正确示范声明变量计算----------"
num1='10'
num2=5
echo "${num1} + ${num2} 等于 $(( ${num1} + ${num2} ))"
echo
echo "错误示范---------------------"
echo "不是数字 $(( "sss" + 5 ))"
echo "3 + 5 等于(字符串数字)$(( '3' + 5 ))"
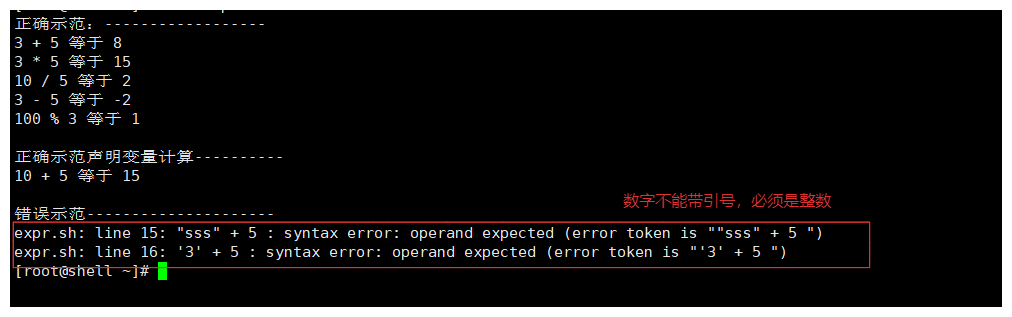
9-3.$[]运算(推荐使用)
语法:
$[ 数字1 符号 数字2 ]
$[ 变量1 符号 变量2 ]
# 脚本
#! /bin/bash
echo "示范:------------------"
echo "3 + 5 等于 $[ 3 + 5 ]"
echo "3 * 5 等于 $[ 3 * 5 ]"
echo "10 / 5 等于 $[ 10 / 5 ]"
echo "3 - 5 等于 $[ 3 - 5 ]"
echo "100 % 3 等于 $[ 100 % 3 ]"

9-4.let运算
注意:
- let 是对变量计算并且赋值给变量,需要变量进行接收。
- 不能有空格,
*需要进行转移\*。
语法:
let 接受变量=数值变量1+数值变量2
echo ${接受变量} # 打印变量
# 脚本
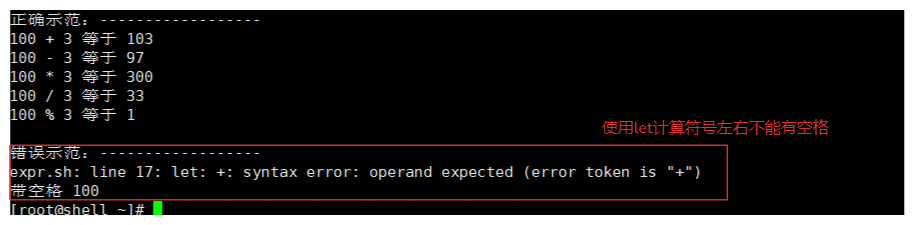
#! /bin/bash
echo "正确示范:------------------"
num1=100
num2=3
let a=${num1}+${num2}
let b=${num1}-${num2}
let c=${num1}\*${num2}
let d=${num1}/${num2}
let e=${num1}%${num2}
echo "${num1} + ${num2} 等于 ${a}"
echo "${num1} - ${num2} 等于 ${b}"
echo "${num1} * ${num2} 等于 ${c}"
echo "${num1} / ${num2} 等于 ${d}"
echo "${num1} % ${num2} 等于 ${e}"
echo
echo "错误示范:------------------"
let f=${num1} + ${num2}
echo "带空格 ${f}"
9-5.bc运算(推荐使用)
注意:
- bc需要使用 管道符 传给bc进行计算
echo xx + xx | bc- 支持整数,小数点运算
语法:
echo 数字 符号 数字 | bc
echo 变量 符号 变量 | bc
# 脚本
#! /bin/bash
echo "正确示范:------------------"
num1=100
num2=3
a=$(echo ${num1} + ${num2} | bc)
b=$(echo ${num1} - ${num2} | bc)
c=$(echo ${num1} \* ${num2} | bc)
d=$(echo ${num1} / ${num2} | bc)
e=$(echo ${num1} % ${num2} | bc)
echo "${num1} + ${num2} 等于 ${a}"
echo "${num1} - ${num2} 等于 ${b}"
echo "${num1} * ${num2} 等于 ${c}"
echo "${num1} / ${num2} 等于 ${d}"
echo "${num1} % ${num2} 等于 ${e}"
echo
echo "小数计算:------------------"
num3=100.1
num4=3.25
f=$(echo ${num3} + ${num4} | bc)
echo "${num3} + ${num4} 等于 ${a}"

9-6.awk运算
注意
- awk的引号嵌套问题,如果引用变量那么就是
"'变量'",双引号在外,单引号在内。- 支持整数与小数。
语法:
awk 'BEGIN{print "'${变量1}'" + "'${变量2}'" }' # 使用变量
awk 'BEGIN{print 数字1 + 数字2 }' # 不使用变量
脚本
#! /bin/bash
echo "示范:------------------"
num1=100
num2=3
awk 'BEGIN{print "'${num1}'" + "'${num2}'" }'
awk 'BEGIN{print "'${num1}'" - "'${num2}'" }'
awk 'BEGIN{print "'${num1}'" * "'${num2}'" }'
awk 'BEGIN{print "'${num1}'" / "'${num2}'" }'
awk 'BEGIN{print "'${num1}'" % "'${num2}'" }'
echo
echo "小数计算:------------------"
num3=100.1
num4=3.25
awk 'BEGIN{print "'${num3}'" + "'${num4}'" }'
echo
echo "不使用变量:------------------"
awk 'BEGIN{print 10 + 15.1 }'

10.Shell特殊语法
# 根据变量返回结果
${parameter:=word}:# 将word作为赋值
如果 parameter 未设置或为空,则将 word 赋值给 parameter。这是一种“赋值默认值”的行为,它会改变原始变量的值。
${parameter:?word}:# 将word当做错误信息
如果 parameter 未设置或为空,则打印错误信息 word(通常是一个错误消息),并且脚本会以非零状态退出。这是一种“检查变量是否已设置”的行为。
${parameter:-word}:# 将word当做默认值
如果 parameter 未设置或为空,则返回 word。这是一种“返回默认值”的行为,它不会改变原始变量的值。
${parameter:+word}:# 将word当做非空的条件
如果 parameter 已设置且非空,则返回 word。这是一种“条件返回”的行为,它不会改变原始变量的值。
# 变量的特殊语法
${变量名} 返回变量值
${#变量名} 返回变量长度,字符长度
比如:
name='王五6666'
${#name} # 获取name的长度就是6
${变量名:start} 返回变量Offset数值之后的字符 # 切片
比如:
name='王五6666'
${name:1} # 打印的结果就是:五6666
${变量名:start:length} 提取offset之后的length限制的字符 # 切片
比如:
name='王五6666'
${name:1:1} # 打印的结果就是:五
${变量名#word} 从变量开头删除最短匹配的word子串
比如:
name='王五6666'
${name#王} # 打印的结果就是:五6666
${变量名%word} 从变量结尾删除最短的word
比如1:
name=123.txt
${name%.*} # 打印的结果123
比如2:
name='王五6666王'
${name%王} # 打印的结果就是:王五6666
${变量名/pattern/string} 用string代替第一个匹配的pattern
比如:
name='王五6666王'
${name/王/李} # 打印的结果就是:李五6666王
${变量名//pattern/string} 用string代替所有的pattern
比如:
name='王五6666王'
${name/王/李} # 打印的结果就是:李五6666李
11.Shell条件判断
其他参数:
1. 关于某个文件名的『类型』侦测(存在与否),如 test -e filename
-e 该『文件名』是否存在?(常用)
-f 该『文件名』是否为文件(file)?(常用)
-d 该『文件名』是否为目录(directory)?(常用)
-b 该『文件名』是否为一个 block device 装置?
-c 该『文件名』是否为一个 character device 装置?
-S 该『文件名』是否为一个 Socket 文件?
-p 该『文件名』是否为一个 FIFO (pipe) 文件?
-L 该『文件名』是否为一个连结档?
2. 关于文件的权限侦测,如 test -r filename
-r 侦测该文件名是否具有『可读』的属性?
-w 侦测该文件名是否具有『可写』的属性?
-x 侦测该文件名是否具有『可执行』的属性?
-u 侦测该文件名是否具有『SUID』的属性?
-g 侦测该文件名是否具有『SGID』的属性?
-k 侦测该文件名是否具有『Sticky bit』的属性?
-s 侦测该文件名是否为『非空白文件』?
3. 两个文件之间的比较,如: test file1 -nt file2
-nt (newer than)判断 file1 是否比 file2 新
-ot (older than)判断 file1 是否比 file2 旧
-ef 判断 file2 与 file2 是否为同一文件,可用在判断 hard link 的判定上。 主要意义在判定,两个文件是否均指向同一个 inode 哩!
4. 关于两个整数之间的判定,例如 test n1 -eq n2
-eq 两数值相等 (equal)
-ne 两数值不等 (not equal)
-gt n1 大于 n2 (greater than)
-lt n1 小于 n2 (less than)
-ge n1 大于等于 n2 (greater than or equal)
-le n1 小于等于 n2 (less than or equal)
5. 判定字符串的数据
test -z string 判定字符串是否为 0 ?若 string 为空字符串,则为 true
test -n string 判定字符串是否非为 0 ?若 string 为空字符串,则为 false。
注: -n 亦可省略
test str1 = str2 判定 str1 是否等于 str2 ,若相等,则回传 true
test str1 != str2 判定 str1 是否不等于 str2 ,若相等,则回传 false
6. 多重条件判定,例如: test -r filename -a -x filename
-a (and)两状况同时成立!例如 test -r file -a -x file,则 file 同时具有 r 与 x 权限时,才回传 true。
-o (or)两状况任何一个成立!例如 test -r file -o -x file,则 file 具有 r 或 x 权限时,就可回传 true。
! 反相状态,如 test ! -x file ,当 file 不具有 x 时,回传 true
6.特殊符号
|| 与 && 区别
&& : 条件 && 前面条件'成立',这里执行
|| : 条件 && 前面条件'不成立',这里执行
11-1.文件判断参数
| 参数 | 解释 | 举例 |
|---|---|---|
| -e | 文件或目录存在就是true (通用 文件/文件夹存在) | [ -e filepath ] |
| -s | 文件存在且只要有一个字母就是true (1.文件存在,2.文件内有最少一个字符的内容) | [ -s filepath ] |
| -f | 文件存在且是普通文件类型就是true (只是普通文件) | [ -f filepath ] |
| -d | 文件存在且是目录类型就是true (只是文件夹) | [ -d filepath ] |
| -r | 文件存在且有read权限就是true (只有r权限) | [ -r filepath ] |
| -w | 文件存在且有write权限就是true (只有w权限) | [ -w filepath ] |
| -x | 文件存在且有x权限就是true (只有执行权限) | [ -x filepath ] |
11-2.整数判断参数
| 参数 | 解释 | 举例 |
|---|---|---|
| -eq | 两数值相等 | [ 1 -eq 1 ] |
| -ne | 两数值不等 | [ 1 -ne 2 ] |
| -gt | n1 大于 n2 | [ 2 -gt 1 ] |
| -lt | n1 小于 n2 | [ 1 -lt 2 ] |
| -ge | n1 大于等于 n2 | [ 3 -ge 2] |
| -le | n1 小于等于 n2 | [ 2 -le 3 ] |
11-3.字符串判断参数
| 参数 | 解释 | 案例 |
|---|---|---|
| == | 两边值相等为true | [ "$a" == "$b" ] |
| != | 两边值不等为true | [ "$a" != "$b" ] |
| -z | 字符串为空时为true/否则false | [ -z "$a" ] |
| -n | 字符串内容不为空为true/否则false,长度不能是0 | [ -n "$a" ] |
| = | 同 == 作用一样 | [ "$a" = "$b" ] |
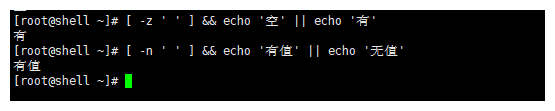
注意关于 -n 参数与 -z 参数
[ -z ' ' ] && echo '空' || echo '有' # 打印的结果是 无值
[ -n ' ' ] && echo '有值' || echo '无值' # 打印的记过是 有值
根据上面的条件
-n 字符串有值为true,那么有空也算有值。
-z 字符串为空时true,如果带有空格也算有值。
-n 条件,字符串的长度不能为0,哪怕字符串内是空格。
-z 条件,字符串长度必须为0,有空格条件不成立,也算作字符串
# -z 字符串长度为0,-n 字符串不能为0,空格也算作一个字符串(也就是一个长度)。
11-4.逻辑判断参数
| 参数 | 解释 | 案例 |
|---|---|---|
| -a | 左右两边条件同时为真时,为true | [ 6 -eq 6 -a 8 -gt 3 ] |
| -o | 左右两边条件有一个为真,就为true | [ 1 -gt 1 -o 2 -eq 2 ] |
! |
结果取反,true反flase,flase为true | [ ! 1 -eq 1 ] |
还有一种写法利用 || 或者 && 实现多条件:
[ 1 -eq 1 ] && [ 1 -ne 2 ] 就等于 [ 1 -eq 1 -a 1 -ne 2 ]
[ 1 -eq 1 ] || [ 1 -ne 2 ] 就等于 [ 1 -eq 1 -o 1 -ne 2 ]
11-5.条件判断
语法:
[ 条件 ] && '条件成立' || '条件不成立' # 单条件
[ 条件1 -a 条件2 ] && '条件成立' || '条件不成立' # 多条件
# 脚本
#! /bin/bash
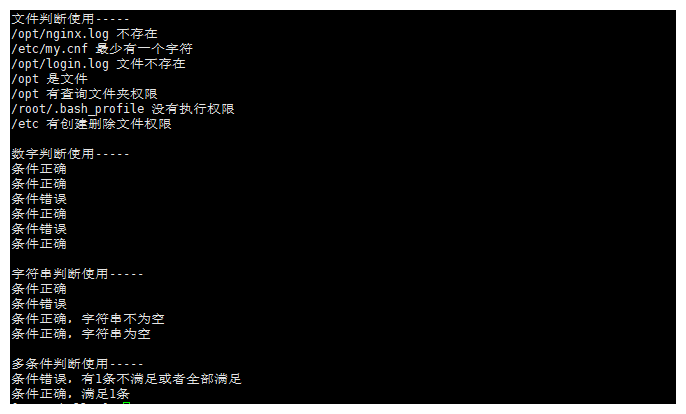
echo "文件判断使用-----"
[ -e /opt/nginx.log ] && echo '/opt/nginx.log 目录存在' || echo '/opt/nginx.log 不存在'
[ -s /etc/my.cnf ] && echo "/etc/my.cnf 最少有一个字符" || echo "/etc/my.cnf 空文件"
[ -f /opt/login.log ] && echo '/opt/login.log 文件存在' || echo '/opt/login.log 文件不存在'
[ -d /opt ] && echo '/opt 是文件' || echo '/opt 不是文件'
[ -r /opt ] && echo '/opt 有查询文件夹权限' || echo '/opt 没查询文件夹权限'
[ -x /root/.bash_profile ] && echo '/root/.bash_profile 有执行权限' || echo '/root/.bash_profile 没有执行权限'
[ -w /etc ] && echo '/etc 有创建删除文件权限' || echo '/etc 没有创建删除文件权限'
echo
echo "数字判断使用-----"
[ 1 -eq 1 ] && echo '条件正确' || echo '条件错误'
[ 1 -ne 2 ] && echo '条件正确' || echo '条件错误'
[ 1 -gt 2 ] && echo '条件正确' || echo '条件错误'
[ 1 -lt 2 ] && echo '条件正确' || echo '条件错误'
[ 1 -ge 2 ] && echo '条件正确' || echo '条件错误'
[ 1 -le 2 ] && echo '条件正确' || echo '条件错误'
echo
echo "字符串判断使用-----"
[ '王五' == '王五' ] && echo '条件正确' || echo '条件错误'
[ '王五' != '王五' ] && echo '条件正确' || echo '条件错误'
[ -n '王五' ] && echo '条件正确,字符串不为空' || echo '条件错误,字符串为空'
[ -z '' ] && echo '条件正确,字符串为空' || echo '条件错误,字符串不为空'
echo
echo "多条件判断使用-----"
[ '王五' == '王五' -a 1 -eq 2 ] && echo '条件正确,2条都满足' || echo '条件错误,有1条不满足或者全部满足'
[ '王五' == '王五' -o 1 -eq 2 ] && echo '条件正确,满足1条' || echo '条件错误,1条都不满足'
11-6.test条件判断
语法:
test 参数条件 && '条件成立' || '条件不成立' # 单条件
test 参数条件1 && test 参数条件2 && '条件成立' || '条件不成立' # 多条件
# 脚本
#! /bin/bash
test 1 -eq 1 && echo '条件成立' || echo '条件不成立'
test 1 -ne 2 && test '王五' != '李四' && echo '条件成立' || echo '条件不成立'
# 执行的结果
[root@shell ~]# bash z.sh
条件成立
条件成立
11-7.怎么导入其他文件,并使用文件函数变量
# 怎么使用操作系统或者其他文件的变量或者函数
在自己脚本中进行.或者source导入文件路径即可使用这个文件内的变量和函数
# /etc/init.d/functions 系统自带的一个功能函数库
source /etc/init.d/functions
. /etc/init.d/functions
# 脚本
#! /bin/bash
. /etc/init.d/functions
[ '王五' == '王五' ] && action '条件正确' /bin/true || action '条件错误' /bin/false
[ 100 -ge 80 ] && action '条件正确' /bin/true || action '条件错误' /bin/false

11-7.if判断
# 语法
if [ 条件 ];then
成立执行
elif [ 条件2 ];then
成立执行
elif ....;then
可以多条
else
最后上述条件不成立执行
fi
# 注意后面结果必须有 fi 作为if判断的结尾。判断条件需要加入 ;then
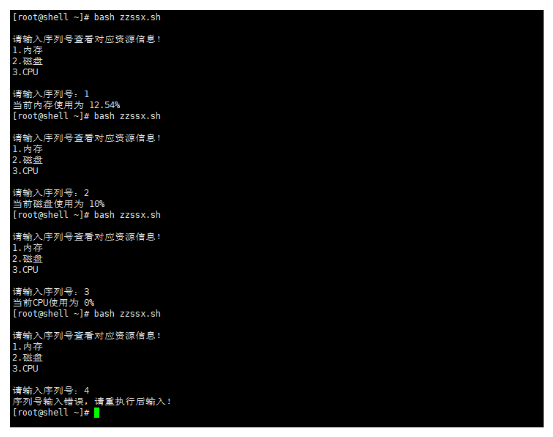
# 脚本,查看当前服务器资源脚本,运用if多分支判断。
#! /bin/bash
echo -e "
请输入序列号查看对应资源信息!
1.内存
2.磁盘
3.CPU
"
read -p '请输入序列号:' num
if [ ${num} -eq 1 ];then
free_="$(free | awk 'NR==2{print $3/$2 * 100}' | grep -Eo '[0-9]+\.[0-9]{1,2}')%"
echo "当前内存使用为 $free_"
exit 0
elif [ ${num} -eq 2 ];then
df_="$(df | awk '/\/$/{print $5}')"
echo "当前磁盘使用为 $df_"
exit 0
elif [ ${num} -eq 3 ];then
# sudo yum install sysstat
cpu_="$(sar -u 1 1 | awk '/Av.*/{print 100 - $NF }')%"
echo "当前CPU使用为 $cpu_"
exit 0
else
echo "序列号输入错误,请重执行后输入!"
exit 1
fi
11-8.case判断
用于条件判断,作用,将重复的条件判断,简便化
case和if一样,都是用于处理多分支的条件判断
但是在条件较多的情况,if嵌套太多就不够简洁了
case语句就更简洁和规范了
判断的条件较多,变量较多
# 语法
case 条件 in
对比条件1)
成立
;;
对比条件2)
成立
;;
对比条件3)
成立
;;
*) # 通配符,等同于if判断中的 else
以上3个条件都不成立
;;
esac
# 将 case 转变为 if 判断
if [ 条件 == 条件1 ];then
条件1成立
elif [条件 == 条件2 ];then
条件2成立
else
条件1与条件2都不成立
fi
# case 的缺点也很明显,只能判断对等的条件,不支持表达式操作,复杂的条件还需要使用if来操作。
注意:
case语句不需要判断是不是为空,或者错误输入,只要不是匹配到条件1/条件2/条件N,都会被*(通配符)进行捕获到
case语句比if语句(需要判断变量是否为空,是否与匹配的值冲突)好用多了
case与正则表达式 # 由于正则太过强大,匹配的内容太多,会导致判断条件不精准
case支持正则,只支持基本的几个语句
只支持用法:
* 表示任意字符
? 表示单个字符
[abc] 表示匹配a,b,c三个任意的字符,[as123]那么只支持a,s,1,2,3这5个字符的某一个(只支持一个)
[m-n] 表示匹配从m-n的任意字符,比如[0-9]表示任意一个数字,[0-9a-zA-Z]匹配字母或者数字(只支持一个)
| 表示多种选择,类似于逻辑运算中得运算,比如abc|qwe表示要么是abc 要么是qwe
# 脚本
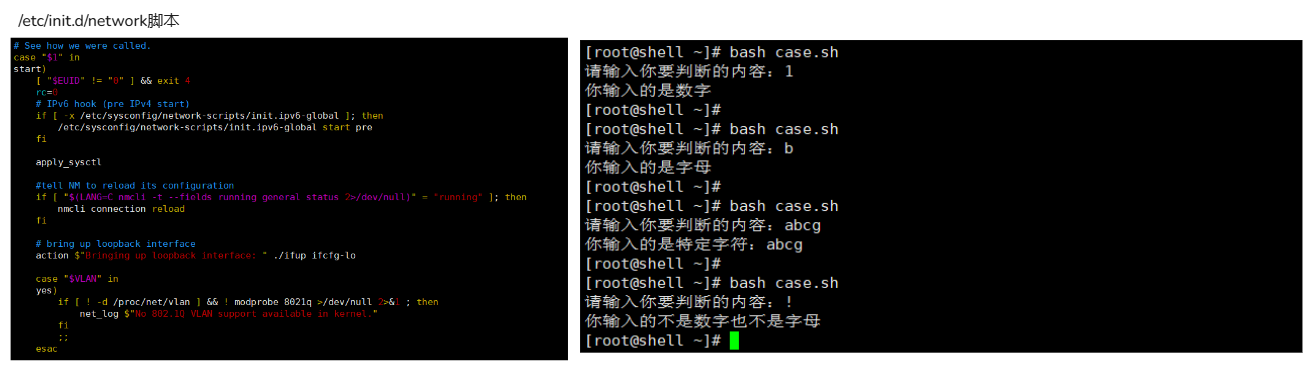
#! /bin/bash
read -p '请输入你要判断的内容:' val
case $val in
[0-9])
echo "你输入的是数字"
;;
[a-zA-Z])
echo "你输入的是字母"
;;
abc?)
echo "你输入的是特定字符:${val}"
;;
*)
echo "你输入的不是数字也不是字母"
;;
esac
# case实现的nginx日志分析脚本
#!/bin/bash
echo -e "------------
------日志分析系统,功能菜单------
1. 显示当前机器信息
2. 查询pv,uv
3. 显示访问量最高的10个ip,以及访问次数
4. 显示访问最频繁的10个业务url,最频繁的页面
5. 显示各种搜索引擎爬虫访问本站的次数
6. 显示都有哪些客户端访问了本网站
-------------"
read -p "请输入您的选择:" num
case $num in
1)
echo -e "===========当前机器信息=======
服务器名:$(hostname)
服务器IP: $(hostname -I)
当前系统时间:$(date +%T-%F)
当前登录用户:$USER
=========="
;;
2)
# y-awk-nginx.log 改为一个位置参数或者变量,增加适配性
echo -e "=========当前机器pv、uv统计数据======
# 统计日志中的请求方式,有多少个就是有多少个pv数
pv页面访问总量:$(awk '{print $6}' y-awk-nginx.log | wc -l)
========================================================================
# 统计日志中的ip地址,进行去重获取uv数量
uv独立访客数量:$(awk '{print $1}' y-awk-nginx.log |sort |uniq -c |wc -l)
"
;;
3)
echo -e "=========访问量最高的10个IP,访问次数==============
# 不适用-r 提取最后10就可以
$(awk '{print $1}' y-awk-nginx.log |sort |uniq -c |sort -n |tail -10)"
# sort -r 倒叙获取 head获取前10个就可以
$(awk '{print $1}' y-awk-nginx.log |sort |uniq -c |sort -n -r |head -10)"
;;
4)
echo -e "=======访问量最高的10个业务url,最频繁的页面=====
$(awk '{print $7}' y-awk-nginx.log | sort | uniq -c |sort -rn |head -10)"
;;
5)
echo -e "======显示各种搜索引擎爬虫访问本站的次数========
# 针对日志的信息,可以帮助公司封禁恶意的流量
# 检查入 python java 等客户端来的信息
# 比如爬虫框架 requests scrapy 可以在日志中提取关键子,然后进行拒绝访问
# 当然客户端也会伪造 user-agent,可以进行根据访问频率进行封禁
百度爬虫访问次数:$(grep -Ei 'baiduspider' y-awk-nginx.log |wc -l)
必应爬虫访问次数:$(grep -Ei 'bingbot' y-awk-nginx.log |wc -l)
谷歌爬虫访问次数:$(grep -Ei 'googlebot' y-awk-nginx.log |wc -l)
搜狗爬虫访问次数:$(grep -Ei 'sogou web spider*' y-awk-nginx.log |wc -l)
易搜爬虫访问次数:$( grep -Ei 'yisou' y-awk-nginx.log |wc -l)
"
;;
6)
echo -e "========访问本网站的客户端种前10种是:==============
# 提取客户端的信息,根据user—agent进行提取去重获取
$( awk '{print $12}' y-awk-nginx.log|sort |uniq -c |sort -rn |head -10)"
;;
*)
echo "请按要求输入选项!!!谢谢!"
;;
esac
12.Shell循环
12-1.for循环
# 语法,如果是循环10次那么会执行10次操作。
第一种:
for 变量名 in 取值列表
do
每一次循环需要的操作
done
第二种:
for 变量名 in 取值列表;do 每一次循环需要的操作 ;done
# 生成数字列表的方式
{1..20} # 生成一个1-20的数字列表
[root@shell ~]# echo {1..20}
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
seq 1 5 # 生成一个1-5的数字列表
[root@shell ~]# seq 1 5
1
2
3
4
5
使用那种方式都可以,一种是命令,一种是语法。
for循环注意事项
- for循环是按照空格区分每一个元素的
- 如果某个元素带有空格,那么需要使用引号括起来
'王 五',不然就会导致王与五分开。- 如果循环的元素是一个大的字符串(变量的前提下),并且使用引号,那么如果中间包含空格,也会根据空格进行区分。
# 脚本1
#! /bin/bash
echo "1.带空格并没有使用后引号----根据空格区分"
for i in 小 王 小李 小张
do
echo "${i}"
done
echo
echo "2.变量存在空格----循环根据空格区分"
a="红烧肉 五花肉 爆炒腰花"
for i in $a
do
echo "${i}"
done
echo
echo "3.循环一个整体的带有空格字符串----循环时就是一个整体"
for i in "红烧肉 五花肉 爆炒腰花"
do
echo "${i}"
done
echo
echo "4.字符串内部没有空格----循环时就是一个整体"
for i in "张三李四王二麻子"
do
echo "${i}"
done
# 注意:声明变量与不声明变量使用同样的文件有区分
a="红烧肉 五花肉 爆炒腰花"
for i in $a
for i in "红烧肉 五花肉 爆炒腰花"
因为:shell中变量(字符串内空格大字符串)类似于python 中得列表 元祖 集合
a="红烧肉 五花肉 爆炒腰花" 等同于 python语言的列表 a=["红烧肉","五花肉","爆炒腰花" ]

# 脚本,循环环境变量
#! /bin/bash
path_=$(echo ${PATH} | sed 's#:# #g') # 因为for循环按照空格,将path的:替换为空格
for i in $path_
do
echo $i
done
# 结果
[root@shell ~]# bash path.sh
/usr/local/sbin
/usr/local/bin
/usr/sbin
/usr/bin
/root/bin
总结
for循环提取数据列表的语法,for是看到一个空格就会被是被为一个元素。- 当你需要重复执行n次任务就可以使用数字序列的方式
{1..50} or $(seq 1 50)。for循环可以循环变量或者命令$(seq 1 50)或for i in $students_list。a="红烧肉 五花肉 爆炒腰花"当成一个数据列表,for i in "红烧肉 五花肉 爆炒腰花"当做一个整体。
12-2.其他的for循环
# c语言语法
for (( num=0;num<15;num++))
#初始条件num=0
# 每次执行num++ = num +1
# 只要条件num<15 也就是不大于15,就会执行for循环,直到num大于15就会结束
do
echo "当前循环的数字${num}"
done
# awk for
1.NF 就是使用FS 切割后的每一个元素的总数量
2.for(n=1;n<NF;n++) 进行循环n就是被循环的值
3.print $n 就是打印被循环的值
echo ${PATH} | awk -v FS=':' '{for(n=1;n<NF;n++) print $n}'
[root@shell ~]$echo ${PATH} | awk -v FS=':' '{for(n=1;n<NF;n++) print $n}'
/usr/local/sbin
/usr/local/bin
/usr/sbin
/usr/bin
# awk 的if
1.if(NR<=4) 进行整数判断
2.NR是代表行的意思
3.就是打印小于等于4的行
awk '{ if(NR<=4) print $0}' /etc/passwd
# '{ if(NR<=4) print $0}' 这种写法等于 'NR<=4{print $0}'
[root@shell ~]$awk '{ if(NR<=4) print $0}' /etc/passwd
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
12-3.for循环文件内容
注意
for循环是按照空格进行区分的while循环按照换行符区分的
# 循环 /etc/passwd文件的内容
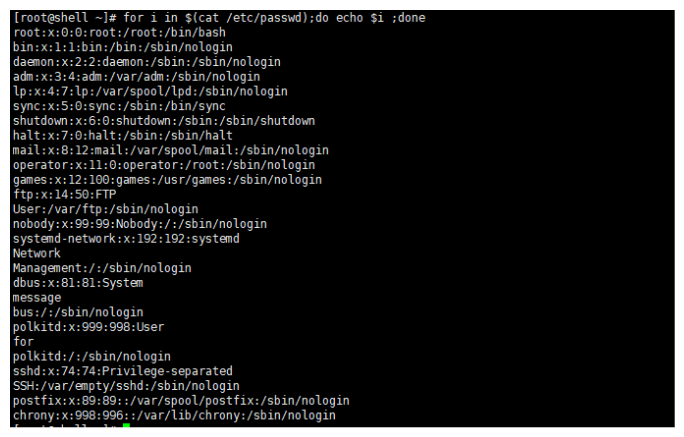
for i in $(cat /etc/passwd);do echo $i ;done
从下面的循环结果看,感觉好像也是按照换行符号区分的。
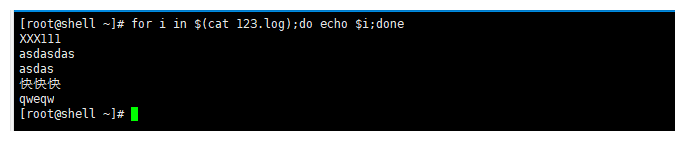
1.创建文件
touch 123.log
2.写入内容
cat >>123.log<<EOF
XXX111 asdasdas
asdas
快快快 qweqw
EOF
3.在进行循环查看123.log
for i in $(cat 123.log);do echo $i;done
从结果来看,for循环是按照空格进行区分每一个元素进行循环的,所以for循环适合对变量进行循环操作,而不适合对文件进行循环操作,容易出现问题。比如:nginx日志文件,我们需要每一行的id,但是使用for循环的情况下空格进行区分元素,那么就无法精准的获取每一个的id(第二张图片)。
12-4.while循环
- 当明确循环的限定次数,用for、不确定循环次数使用while。
- 如循环让用户输入的登录程序,如循环操作的一些菜单程序,直到用户输入结束指令菜单。
- 一般对文件数据读取使用的是while循环(根据换行符进行区分) for不好用(根据空格进行区分,如果文件中得某一行出现了空格,读取就出现不对)。
注意
while一定要知道在什么条件下终止,不然会出现死循环,非常危险,会消耗cpu的资源,要清晰自己干什么,在进行使用。
语法:
while 条件 # 条件成立为true后执行循环体,如果条件为false时就会出现停止
do
循环体
done
# 循环内部的条件控制
while [ "$u" != "sunwukong" ] # 当前u不等于sunwukong时,循环一直进行(条件为ture),当等于时就会终止循环(条件为false)
do
read -p "请输入账号 sunwukong:" u
done

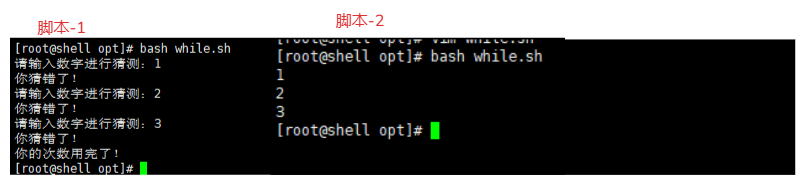
# 脚本-1
#!/bin/bash
num=1
while [ $num -le 3 ]
do
read -p '请输入数字进行猜测:' val
case val in
10)
echo "你猜对了!"
;;
*)
echo "你猜错了!"
;;
esac
let num++
done
echo "你的次数用完了!"
# 脚本-2
#!/bin/bash
num=1
while [ $num -le 3 ]
do
echo ${num}
let num++
done
# 怎么对数字进行+1操作
num=1
1.let num++ # let的对数字的自增+1操作
2.num=$[ $num + 1 ] # $[]重新赋值进行+1操作
3.num=$( echo ${num} + 1 | bc ) # 使用 bc命令进行赋值+1操作
12-5.怎么读取文件
- 注意:while读取文件是按照换行符进行操作的。
- 可以使用文件路径或者文件名称操作
1. cat 命令将文件交给while read 处理
语法:
cat 文件名 | while read 接受文件每一行的变量
# 语法全部
cat 文件名称 | while read 接受文件每一行的变量
do
循环内容
done
2.使用<符号将文件内容导入到while中
语法:
done < 文件名称 # 在done的位置导入给while
# 语法全部
while read 接受文件每一行的变量
do
循环内容
done < 文件名称
3.将文件先导入到脚本中,然后在使用while读取
语法:
exec < 文件
# 语法全部
exec < 文件 # 导入文件到脚本中(父bash),导入操作(子bash)
while read 接受文件每一行的变量
do
循环内容
done
while读取文件操作
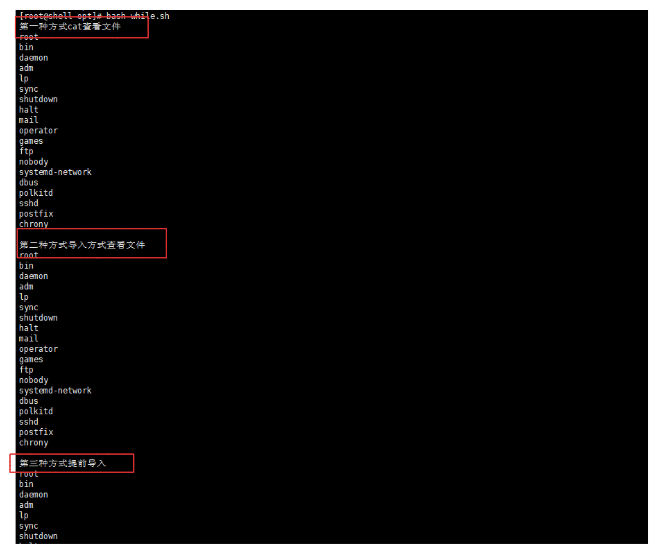
# 脚本,读取打印/etc/passwd 文件的用户名称
echo "第一种方式cat查看文件"
cat /etc/passwd | while read user_info
do
echo $( echo ${user_info} | awk -v FS=':' '{print $1}')
done
echo
echo "第二种方式导入方式查看文件"
while read user_info
do
echo $( echo ${user_info} | awk -v FS=':' '{print $1}')
done < /etc/passwd
echo
echo '第三种方式提前导入'
exec < /etc/passwd
while read user_info
do
echo $( echo ${user_info} | awk -v FS=':' '{print $1}')
done
while对按照行读取
1.先创建一个文件,并写入一些内容
vim 123.log # 文件名
# 内容
王五 李四 哈哈哈
6666 888
你好,你好,666!
sdqwesadasd
2.脚本
#! /bin/bash
while read val
do
echo ${val}
done < 123.log

12-6.循环控制
break关键字
作用:
当循环中出现breck,那么这个循环就会立即终止,无论循环是否完成,直接停止,while循环与for循环都能使用
总结:
break 语法,是对循环的整体进行终止,终止后,不会在进行循环操作。
如果,脚本中循环中某个条件,达成,不想在进行循环,那么可以使用break终止循环,剩下的循环不执行。
# 脚本
#! /bin/bash
echo "for循环"
num=$( seq 1 4 )
for i in ${num}
do
if [ ${i} -eq 4 ];then
break
fi
echo $i
done
echo
echo "while循环"
num=1
while true
do
if [ ${num} -eq 4 ];then
break
fi
echo $num
let num++
done
# 注意:
使用while循环时,不要因为条件写错,导致死循环(条件一直满足导致一直执行)。

continue关键字
作用:
在遇到continue关键字,就会跳出这个循环,执行一下次循环从,for while 两个循环使用。
总结:
作用就是在循环中可以进行跳出这次循环,不在执行这次循环体 continue下面的 do done 代码,直接开启新一次循环
在循环中,判断,如果条件符合,可以跳过coutinue这个操作,执行下次的循环操作
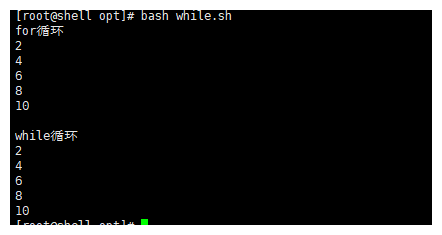
# 脚本,只打印1-10的偶数
#!/bin/bash
echo "for循环"
num=$( seq 1 10 )
for i in $num
do
if [ $[ $i % 2] -ne 0 ];then
continue
fi
echo ${i}
done
echo
echo "while循环"
num=1
while true
do
if [ $num -eq 11 ];then
break
fi
if [ $[ $num % 2 ] -ne 0 ];then
let num++
continue
fi
echo $num
let num++
done
13.Shell的函数
关于函数传递参数的注意:
- 这里的函数传参,是指单独给函数传递执行参数,和给脚本传入参数是两码事。
- 函数传参是指,函数在执行的时候,可以传入位置参数,这样函数连带参数一起执行。
- 函数的中传递的参数${0}代表的还是脚本名称,与脚本位置参数的${0}意义相同。
关于函数参数使用总结:
- 脚本传递的位置参数,可以在脚本文件中进行使用。
- 函数的传递参数,只能在函数内部使用。
- 脚本的位置参数可以作为参数传递给函数。
3.语法
function 函数名称(){
函数体 # 这部分的代码可以复用
}
函数名称(){
函数体 # 这部分的代码可以复用
}
函数的声明分为两种,1.带关键字 2.不带关键字(简写)
2.函数调用
函数名称(){
函数体 # 这部分的代码可以复用
}
函数名称 # 函数调用,就会执行函数
3.函数传递参数
函数名称(){
# 通过${1}..${n}来接收函数传递的参数,与shell脚本用法类似,但是性质不同。
echo "${1}" # 接受参数1
echo "${2}" # 接受参数2
函数体 # 这部分的代码可以复用
}
函数名称 '参数1' '参数2' # 函数调用,同时传递参数,参数之间需要用空格分开
13-1.函数调用
# 脚本
#!/bin/bash
main(){
echo "xxxx"
}
main

13-2.函数传递参数
# 脚本
#!/bin/bash
main(){
echo "接收参数0:${0}" # 打印当前直接脚本名称,使用的是shell的位置参数${0}
echo "接收参数1:${1}" # 函数参数1
echo "接收参数2:${2}" # 函数参数2
}
main '王五' '李四'

13-3.函数中是否可以直接使用脚本参数
函数也是可以接收脚本传递的参数的,"需要将脚本传递的参数,在传递给函数(请看图-1)"。
# 脚本
#!/bin/bash
main(){
echo "接收参数0:${0}" # 打印当前直接脚本名称,使用的是shell的位置参数${0}
echo "接收参数1:${1}" # 函数参数1
echo "接收参数2:${2}" # 函数参数2
}
main
从图中证明,函数无法直接使用执行脚本传递的位置参数,这个位置参数需要再次的传递给函数才能使用。
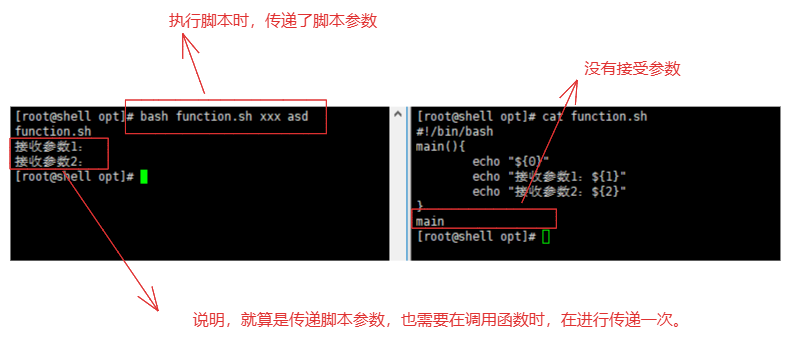
13-4.函数使用shell脚本参数
# 创建 function.sh 脚本
#!/bin/bash
main(){
echo "接收参数0:${0}" # 打印当前直接脚本名称,使用的是shell的位置参数${0}
echo "接收参数1:${1}" # 函数参数1
echo "接收参数2:${2}" # 函数参数2
}
main $1 $2 # 这里的$1与$2是shell脚本传递的参数
# 执行脚本
bash function.sh '老六' '老八'

13-5.调用其他文件的函数
1.创建A文件,同时在创建一个简单函数
touch A.sh
#! /bin/bash
main(){
echo "我是A.sh文件"
}
2.创建B文件,调用A文件函数
touch B.sh
#! /bin/bash
source ./A.sh # 导入A文件,就可以使用A文件的变量与函数
main # 调用A文件的main函数
# 这种方式就类似于python from 与 js import引入方式有异曲同工之处

14.Shell的数组结构
概念:
- 数组是一个数据类型,可以存储多个数据,与pytho列表与js中列表相似,也是使用下标索引进行获取某些元素。
- Shell的数组,普通数组 列表 下标索引,关联数组 字典 key:val。
- 数组用于存储多个值,且提供索引标号便于取值, Bash支持普通的数值索引数组,还支持关联数组。
- 数组是最常见的数据结构,可以用来存放多个数据。
数组分类
- 普通数组,索引类型数组,与其他语言的列表类似。
- 关联数组,key:val 结构,与其他语言的map和字典类似。
- 数值索引类型数组使用0、1、2、3…数值作为索引,通过索引可找到数组中对应位置的数据。
- 关联数组使用名称(通常是字符串,但某些语言中支持其它类型)作为索引,是key/value模式的结构,key是索引,value是对应元素的值。
14-1.普通数组
# 语法:
变量名=(值1 值2 值3 值4 ....)
# 在linux中的形式
1.声明一个普通数组
name=('老王' '老李' '老赵')
2.使用set查询
set | grep name
name=([0]="老王" [1]="老李" [2]="老赵") # 在linux中每一个索引对应一个值
普通数组增删改查
1.声明一个数组
name=('老王' '老李' '老赵')
2.查
语法:${普通数组变量名[下标索引]} 必须使用严谨的语法使用花括号
echo "${name[0]}" # 老王
echo "${name[0]}" # 老李
echo "${name[0]}" # 老赵
为什么使用严格语法,如下图:
1.因为如果不使用,就会导致系统认为你输出的是一个带有[下表索引]加上数组第一个元素字符串
2.如果不带有下表索引,直接打印数组变量,只会将第一个元素打印出来。
3.添加/修改一个元素到数组中
# 注意:如果下表索引没有指向变量,那么就是添加,如果有指向变量就是修改
1.添加
name[4]='乐乐'
2.查看
[root@shell opt]# set | grep name
name=([0]="老王" [1]="老李" [2]="老赵" [4]="乐乐")
3.修改
name[1]='老八'
4.查看
[root@shell opt]# set | grep name
name=([0]="老王" [1]="老八" [2]="老赵" [4]="乐乐") # 将索引1的位置老李修改为老八
4.从数组中删除元素
1.删除洗下表索引为0
unset name[0]
2.查看
[root@shell opt]# set | grep name
name=([1]="老八" [2]="老赵" [4]="乐乐") # 将索引为0的值删除

普通数组的反向索引
# 说明:
反向索引就是通过负值,倒序的方式获取数组中的元素
1.声明变量
list=([1]="王二麻子" [2]="猪八戒" [3]="qiqi" [4]="乐乐")
2.取值
echo ${list[-1]} 取值 乐乐
echo ${list[-2]} 取值 qiqi
echo ${list[-3]} 取值 猪八戒
echo ${list[-4]} 取值 王二麻子
普通数组特殊标号
1.获取数组的所有元素
echo ${数组名称[@]}
echo ${数组名称[*]}
2.获取数组的元素个数,在数组前面加个#号
echo ${#数组名称[@]}
echo ${#数组名称[*]}
3.获取数组中得元素的下标索引标号,在数组前面加个! # 取出数组所有索引标号
echo ${!数组的名称[@]}
echo ${!数组的名称[*]}
# 脚本
#! /bin/bash
list=([1]="王二麻子" [2]="猪八戒" [3]="qiqi" [4]="乐乐")
echo "获取全部的元素 ${list[@]}"
echo "获取元素的总数 ${#list[@]}"
echo "获取元素的在数组的下表索引 ${!list[@]}"

14-2.关联数组
注意:
- 关联数组使用名称(通常是字符串,但某些语言中支持其它类型)作为索引,是key/value模式的结构,key是索引,value是对应元素的值。
- 通过key索引可找到关联数组中对应的数据value,形式:变量['key']=val,如果查询的不存在的key,返回的也是为空。
- 关联数组在其它语言中也称为map、hash结构、dict等。
- 只要对变量是关联数组的方式声明的,无法再通过普通数组的方式赋值。
总结:
- 关联数组与普通数组的用法是差不多的,唯独不同的就是关联数组需要声明,不同数组不需要声明。
- 具体的使用场景需要根据业务而定,因为shell作为脚本进行操作,需要简洁明了,不然其他人就会不太明白。

# 语法:
declare -A 关联数组名称 # 主动声明当前数组是关联数组的类型
关联数组名称[key]=val # 对关联数组中写key val 结构
1.声明一个关联数组
declare -A user_info
2.写入数据
user_info[name]='老王'
3.查看在linux中结构
set | grep user_info

关联数组增删改查
1.先声明一个关联数组
declare -A user_info
2.添加元素
user_info[name]='老王'
user_info[age]=18
[root@shell opt]# set | grep user_info
user_info=([name]="老王" [age]="18" )
3.查询
echo ${user_info[name]} # 结果是 '老王'
echo ${user_info[age]} # 结果是 '18'
4.修改,将name修改为老李
user_info[name]='老李'
[root@shell opt]# set | grep user_info
user_info=([name]="老李" [age]="18" )
5.删除,age元素
unset user_info[age]
[root@shell opt]# set | grep user_info
user_info=([name]="老李" )
关联数组的特殊符号
操作与普通数组相同
1.获取关联数组的全部的元素
echo ${关联数组[*]}
echo ${关联数组[@]}
2.获取关联数组的长度,所有元素的个数
echo ${#关联数组[*]}
echo ${#关联数组[@]}
3.获取关联数组的全部的key
echo ${!关联数组[@]}
echo ${!关联数组[*]}
# 脚本
#! /bin/bash
declare -A user_info # 声明关联数组变量
user_info['name']='老八'
user_info['age']='28'
user_info['address']='不知道'
echo "获取关联数组的全部的元素:${user_info[@]}"
echo "获取关联数组的元素总数:${#user_info[@]}"
echo "获取关联数组的全部的key:${!user_info[@]}"

15.多进程操作
语法如下:
在命令后面加上 & 符号可以将该命令放入后台执行,从而允许同时运行多个进程,wait是等待。
例如:
#!/bin/bash
command1 & # 在后台运行第一个进程
pid1=$!
command2 & # 在后台运行第二个进程
pid2=$!
# 等待所有后台进程结束
wait $pid1
wait $pid2
echo "所有进程已完成"
例如:主机ip存活检测脚本
#! /bin/bash
for i in {1..254}
do
# 使用&符号直接将执行名后台进行执行
# $? 无法在提取当前命令的执行结果,不在一个bash解释器中,与父子bash相关
ping -w 1 192.168.31.${i} >> /opt/ip.log &
done
awk -v FS='[: ]' '/icmp/{print $4}' /opt/ip.log
# 注意:
机器的进程pid数量是有限的,如果使用完毕后就无法在启动服务,就需要重启或者释放哪些占用pid的服务进程。
16.特殊符号汇总
| 符号 | 说明 |
|---|---|
| ; | 分号。cmd1 ; cmd2 ,cmd1无论执行失败与否,都会执行cmd2。连续执行命令的作用。 |
| && | 与的意思。cmd1 && cmd2,cmd1执行成功才会执行cmd2,否则cmd2不执行。 |
| || | 或的意思。`cmd1 |
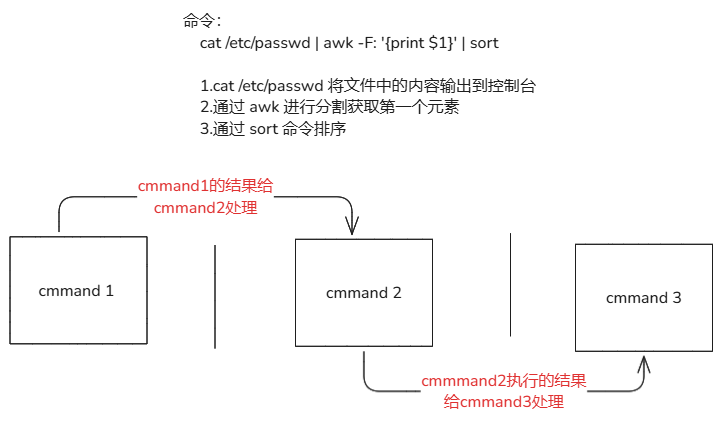
| | | 管道符号,`cmd1 |
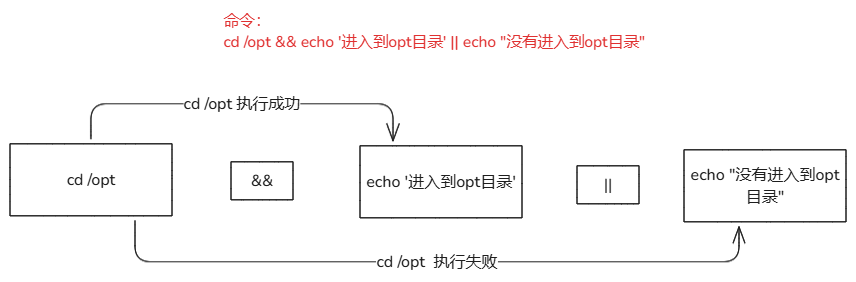
16-1.&&与||解释
16-2.管道符解释