1.<文件>名称通配符
说明:
通配符切记:只是作为查询文件时使用,有些符号与正则表达式相同,但是意义可能有区别。- 在查询文件时,是可以使用通配符进行查询的,比如你忘记了文件的名称,但是依稀记得某些开头的,就可以使用通配符进行查询。
- 同时也可以 命令 + 通配符进行使用。
注意:
- 当忘记文件名称,或者不记得如何拼写,通配符可以帮你寻找。
- 通配符是处理文件的名称的特殊字符,而不是文件内容。
- 可以方便查找类似的文件名称,通配符是shell内置的语法,大部分linux命令都认识通配符,shell编程脚本也可以是实现同辈分查询。
1-1.文件名称查询通配符有哪些
? 作用:
代表任意一个单一的字符。
* 作用:
代表1个或者N个单一的字符。
- 作用:
代表连续的字符,配合中括号使用。一般是 0-9 A-Z a-z,这种带有连续的字符使用。
! 作用:
取反的作用,配合中括号使用。
^ 作用:
取反的作用,配合中括号使用。
[] 作用:
匹配括号内的字符。
| 字符 | 说明 | 示例 |
|---|---|---|
| ? | 在特定位置中匹配"单个"字符。 | b?ll 可以找匹配到 :ball、bell、bill。 |
| [ ] | 匹配方括号中的字符。单个字符。用法:[1,2,3]或者[a,b,c]或者[abcd] | b[a,b]ll 将找到 :ball 和 bell,但找不到 bill。 |
| ! | 在方括号中排除字符。配合中括号使用。 | b[!a,e]ll将找到: 除了ball,bell以外不要,其他的全部文件。作用就是取反。 |
| ^ | 同感叹号功能相同。"取反" 配合方括号使用。 | b[^a,b]ll,将找到: 除了ball,bell以外不要,其他的全部文件。作用就是取反。 |
| * | 匹配一个或者多个任意字符数 | wh*可以能匹配到:wha、whab,whxxx。以wh开头的全部的后面无论是多少字符,都能匹配。 |
| - | 连续字符比如:[a-z],[1-9],[A-Z]配合中括号使用。 | 在中括号中代表一个连续的数字或者字母。 |
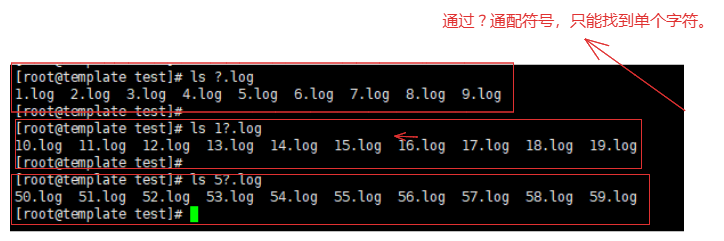
1-2.通配符?示例
# 补充说明:
如果是匹配单个字符的情况下可以使用 ? ,但是如果使用匹配多个情况下使用 * 更为合理。
例如:需要查询 a 开头的.txt文件
ls a?.txt # 只能查询到 a1.txt aa.txt ab.txt ...
ls a*.txt # 能查出 axzsdada.txt a1231546.txt ...
那么如果需要查询多个字符使用 ? ,就需要 ?? ... ?*N 一次类推的方式。
例如:
ls ?.txt # 查询单个字符并且后缀为.txt的文件
ls ?.log # 查询单个字符并且后缀为.log的文件
ls a?.log # 查询单个字符a开头并且后缀为.log的文件
ls /etc/passw? # 查询到 /etc/passwd
1-3.通配符*示例
* : 允许匹配 1-N 个任意字符。
例如:
ls /var/log/vm*.log # 查询以vm开头.log结尾的全部文件
ls /etc/pass* # 查看/etc下的 pass开头的任意结尾的全部文件
ls /var/log/* # 匹配到/var/log/ 目录下全部的内容,包含内部子文件夹的内容
# 总结:
从匹配的结果看来,只要给定范围或者不给定范围,*都会给你匹配到。

1-4.通配符[]示例
[] :匹配中括号内的内容,可以使用[1,2,3] 匹配123这三个字符,也可以使用[123]也是匹配123这三个字符。逗号的作用就是做好区分更好分别,其实区别是相同。
# 注意:
[] 内不能使用 *或者? 这种通配符代表匹配单个或者多个字符。
因为,在中括号内部 *或者? 就是普通的字符,没有任何效果。
例如:
[*123].log # 匹配到的就是 *.log
[?].log # 匹配到的就是 ?.log
例如:
ls /test/1[8,9].log # 只匹配到 19.log 和 18.log
ls /test/1[123456].log # 匹配到 11.log ... 16.log
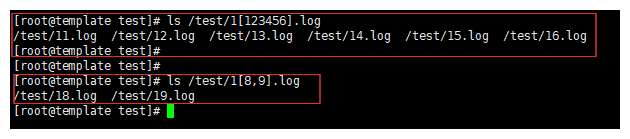
1-5.通配符-示例
- :匹配连续的字符,比如123456789,可以使用1-9来代替。英文24个字母可以使用a-z代替,但是需要配合[]使用。
例如:
ls /test/1[1-9].log # 就是匹配11.log ... 19.log 这9个文件。
ls /test/[a-c].log # 匹配到 a.log b.log c.log

1-6.通配符!示例
! :取反,除了这些文件外的全部文件,需要配合[]使用,如果单独的使用!就是一个普通的字符没有通配符的效果。
例如:
ls /test/[!a-c].log # 匹配除了 a.log b.log c.log 这三个文件外的全部单个字符文件
ls /test/1[!1-9].log # 除了 11.log 到 19.log 以外的全部文件,那么符合条件就是 10.log

1-7.通配符^示例
^:取反,与!相同的意思,需要配合 [] 使用,只不过符号不同罢了。
例如:
ls /test/[^a-c].log # 匹配除了 a.log b.log c.log 这三个文件外的全部单个字符文件
ls /test/1[^1-9].log # 除了 11.log 到 19.log 以外的全部文件,那么符合条件就是 10.log
1-8.组合使用
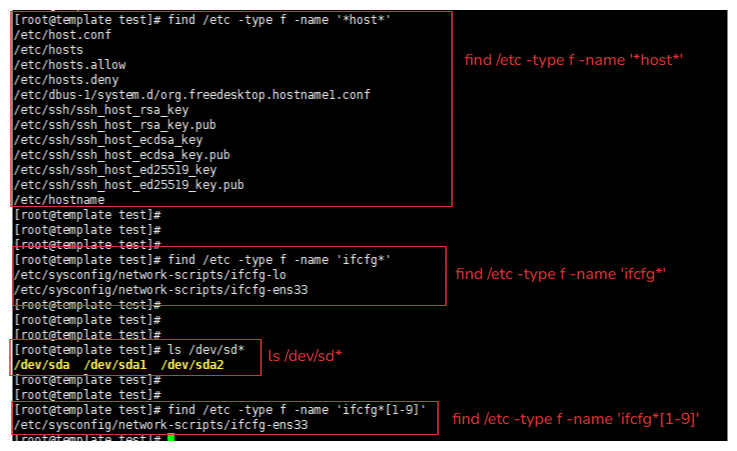
# 与命令find配合使用
1. find /etc -type f -name '*host*'
解释:查询/etc 目录的文件,文件中包含host,无论是开头还是结尾或者是中间。只要包含就能匹配到。
2. find /etc -type f -name 'ifcfg*'
解释:查询 /etc 目录下 以ifcfg开头的文件
3. ls /dev/sd* 或者使用 ls /dev/sd?? 或者使用 ls /dev/sd[a-z]*
解释:查询本机有多少个磁盘设备
注意:ls /dev/sd?? 这种写法你需要知道这个磁盘文件具体有多少个字符。
4.find /etc -type f -name 'ifcfg*[1-9]'
解释:匹配 /etc 目录下 以ifcfg开头的文件并且以数字结尾
2.特殊符号
2-1.路径相关
| 符号 | 意义 |
|---|---|
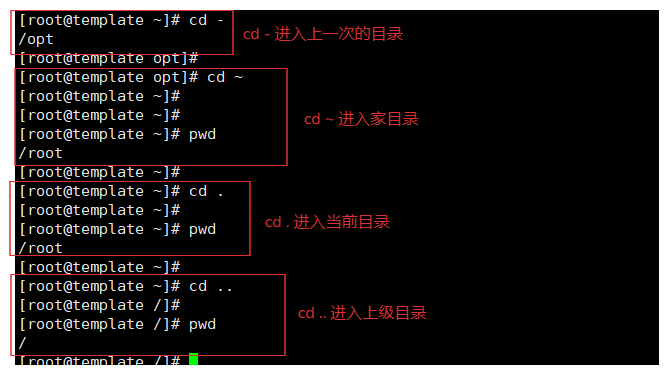
| ~ | 家目录,cd ~ 进入家目录。 |
| - | 上次工作的路径,cd - 就是进入上次目录。 |
| . | 当前路径 |
| .. | 上一级路径 |
2-2.引号相关
| 符号 | 意义 |
|---|---|
| '' | 单引号,所见即所得,内容是什么样的就是什么样的,不具备置换作用。 |
| "" | 双引号,具有置换作用,可以解析变量与特殊符号(例如反引号内的命令)。 |
| `` | 反引号,可以解析命令(可以执行的命令)。 |
| 无引号 | 一定要注意,引号的作用就是为了做变量的边界的,没有引号设置边界容易出现问题。比如:touch abc log 原本应该创建是abc.log但是因为粗心少了一个. 就会(没有引号确定边界)创建两个文件分别是abc文件与log文件,这是比较直观的无引号的区别。 |
引号的意义
1.引号用来区分,字符串边界
2.因为linux识别,命令 ,参数,文件对象,中间是空格区分参数
# 注意:
凡是在单引号中得无论是`变量`还是`命令`或者其他,直接进行输出,没有任何改变,特殊符号失去了它的作用,转变为一个字符。
# 验证:
声明变量 name=123
1.单引号输出
echo '${name}'
[root@template /]# echo '${name}'
${name}
2.双引号输出
echo "${name}"
[root@template /]# echo "${name}"
123
3.反引号输出
echo "name变量是:${name},时间是`date +%F`" # 双引号 + 反引号,双引号输出变量,反引号输出命令
[root@template /]# echo "name变量是:${name},时间是`date +%F`"
name变量是:123,时间是2025-01-09

2-3.重定向相关
| 符号 | 意义 |
|---|---|
| > ,>> | 输出导向,>:覆盖输出,>>:追加输出。stdout |
| <, << | 输入导向,< :覆盖输入,<<:追加输入。stdin |
| >& | 用于重定向到指定的文件描述符号,例如:2>&1 将文件描述符 2(标准错误)重定向到文件描述符 1(标准输出)的位置 |
1.输出
>:用于覆盖之间文件的内容。
>:用于追加文件的内容。
例如:
echo "测试写入" > 123.log # 覆盖输出到 123.log,那么只会有一行记录。
echo "测试写入" >> 123.log # 追加写入 123.log,追加几次就会显示几行记录。
2.输入
<:用于将文件内容作为标准输入传递给命令。
<<:用于将多行文本作为标准输入传递给命令,通常用于脚本中定义多行输入内容。
例如:
sort < 123.log > sorted.log # 将123.log文件内容排序后输出到 sorted.log 文件中。
cat < 123.log # 这个命令将 123.log 文件的内容输出到标准输出(终端)。效果与cat 123.log相同,实现方式不同
# 将多行文本追加到 123.log 文件中
cat << EOF >> 123.log
这是第一行
这是第二行
EOF
2-4.命令相关
| 符号 | 含义 |
|---|---|
| && | and的作用,1==1 && 2==2 条件成立,否则不成立,必须都要成立。 |
| \ | 转义符号,将特殊字符转换为字符原含义。 |
| ; | 连续命令执行符号,cmd1 ; cmd2,就算cmd1命令出错也不影响cmd2执行。 |
| # | 注释符号,用来说明作用。 |
| $() | 与反引号功能相同,可以解析命令。 |
| {} | 用于生成一系列字符串或数字。 |
| () | 用于将多个命令分组,使它们作为一个整体执行。 |
1.{} # 用于生成一系列字符串或数字。
echo {1..5} # 这个命令会输出 1 2 3 4 5。
echo {a..c} # 这个命令会输出 a b c。
touch {a..c}_file.txt # 就会生成 a_file.txt b_file.txt c_file.txt
2.() # 用于将多个命令分组,使它们作为一个整体执行。
(cd /tmp; ls) # 进入/tmp目录进行ls,但是实际不会切换到/tmp,也就不影响当前工作目录。
(command1; command2) | command3 # 比如命令分组
2-5.unix风格通配符表
| 字符 | 作用:就是将字母或者数字替换为了英文字母 |
|---|---|
| [[:upper:]] | 所有的大写字母 [:upper:] == A-Z |
| [[:lower:]] | 小写字母 [:lower:] == a-z |
| [[:alpha:]] | 全部字母 |
| [[:digit:]] | 全部数字 |
| [[:alnum:]] | 数字与字母 |
| [[:space:]] | 所有的空白符号 |
| [[:punct:]] | 所有的标点符号 |
| [[:alpha:]] | 代表任何英文字符大小写。 |
| [[:blank:]] | tab键 |
| [[:cntrl:]] | 代表键盘上的控制键,比如:CR LF tab del |
| [[:graph:]] | 除了空格与tab以外的其他按键。 |
| [[:print:]] | 代表任何可以被打印出来的符号。 |
使用方式:
echo "Hello World" | grep '[[:upper:]]' # 找到包含大写字母的字母标记
grep '[[:lower:]]' 123.log # 找到包含小写字母的行

3.<文件内容>正则表达式
是什么:
- 正则表达式就是为了处理大量的字符串,而定义的一套规则和方法。
- .通过定义的这些特殊字符的辅助,系统管理人员可以快速定位,替换获取到自己想要的内容。
- 过滤采用(gurp) 替换(sed) 输出(awk)
- linux正则表达式一般以行为单位处理。
每一行的文本注意:
- 每一个文本每一行末尾都有一个 \n换行符,默认看不到的。
运用场景:
- 配置文件的内容替换。
- 日志查询,筛选需要的部分。
- 快速定位到错误的代码部分。
3-1.测试网站
https://deerchao.cn/tools/wegester/
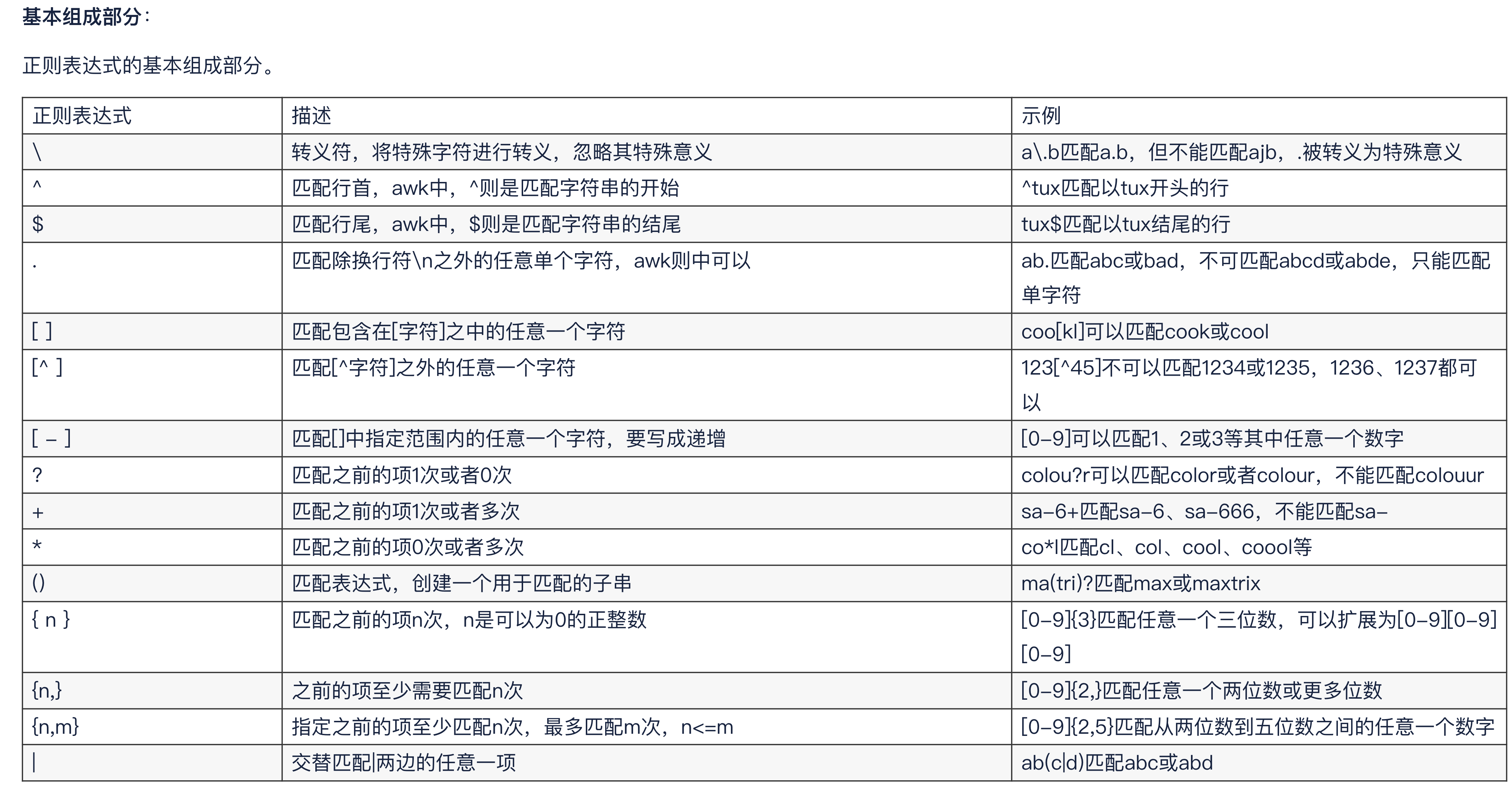
3-2.基本符
常规的最常用的匹配字符。linux系统内都支持,但是根据不同的命令比如 grep sed awk 存在不同的含义。
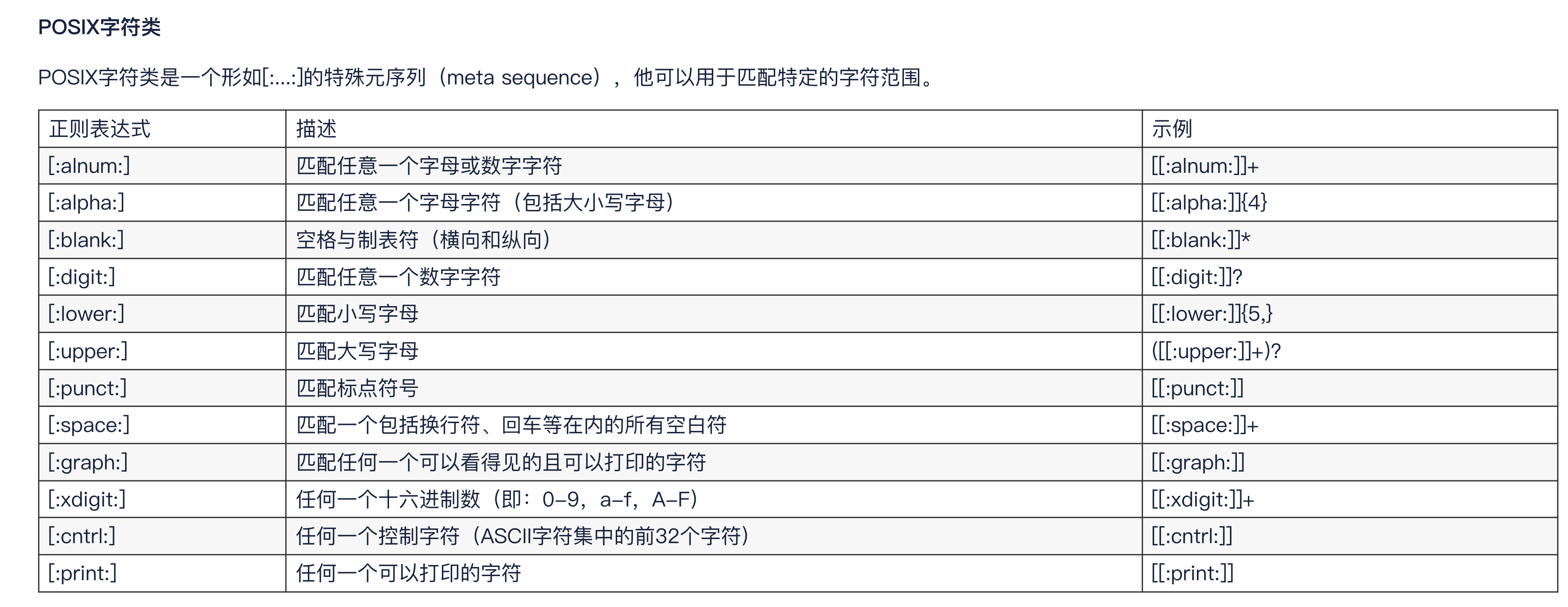
3-3.特定符
POSIX字符类是用于在正则表达式中匹配特定类别字符的预定义字符集。它们是基于POSIX(Portable Operating System Interface)标准定义的,用于在不同的操作系统和编程环境中提供一致的字符匹配功能。
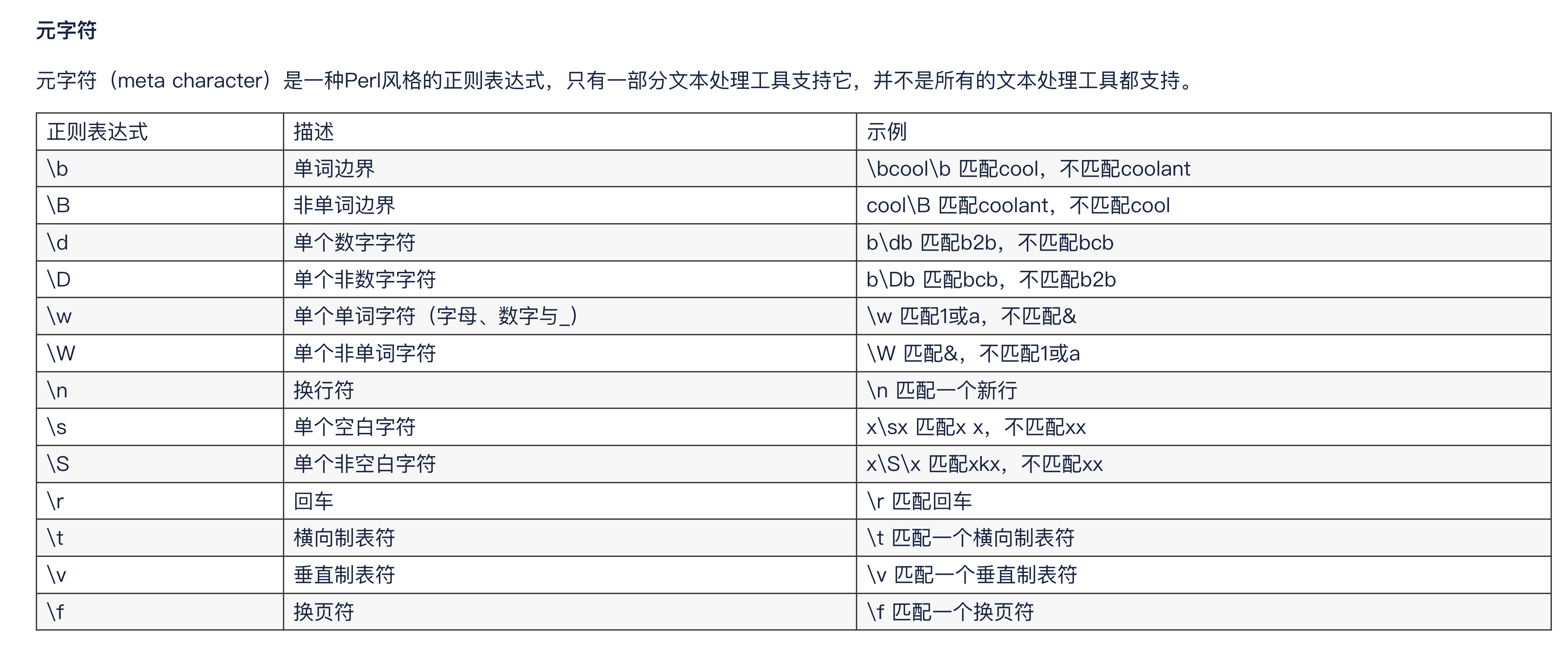
3-4.元字符
它是一种perl风格的正则表达式,部分的工具支持,并不是全部的文本处理工具都支持。
3-5.字符设置
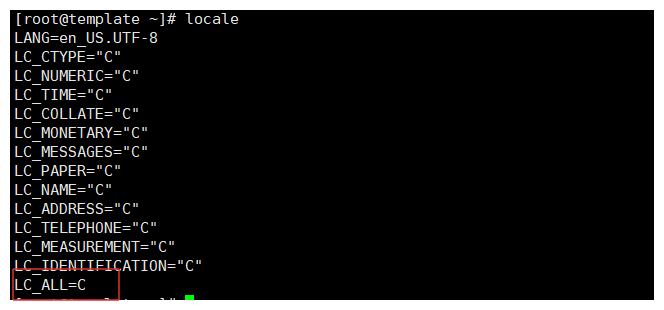
为什么LC_ALL=C设置:
- 字符集一致性:确保使用的是ascll字符集,使正则表达式的行为更加一致和可预测,在不同的字符集下,字符的归类和排序可能不同,会导致查询的结果出现偏差。
- 性能优化:LC_ALL=C可以提高正则查询的性能,因为ascll字符相对于简单,处理更为高效,尤其是大量文本数据时。
- 编码问题:在多字节的字符集中(utf-8),某个字符需要多个字节来表示,比如:
.表示为1个字节而不是一个字符,设置LC_ALL=C可能保证.匹配的单字节。- 兼容性:设置ascll字符集,可以确保工具或者命令的行为一致性。
grep、sed和awk等命令在LC_ALL=C环境下表现更加稳定和一致。例如:
LANG=C:012346...ABCD...abcdLANG=zh_CN:012346..aAbB...zZ- 在编码顺序上是不同的,可能会导致在查询时出现和别人的不同的结果。
3-5-1.LC_ALL设置
# 注意:
字符集需要设置为 us.UTF-8 设置为英文,中文会出现文件。
/etc/locale.conf 配置文件中修改。
1.临时设置
1.设置
export LC_ALL=C
2.查询
locale
2.在环境变量中进行设置
1.修改环境变量文件
vim /etc/profile 或者 ~/.bash_profile 或者 vim /etc/environment(所有用户都会生效)
/etc/profile 与 ~/.bash_profile 添加方式:export LC_ALL=C 然后在 source 文件即可
/etc/environment 添加 LC_ALL=C 然后 重启机器
2.查询
locale
3-6.正则表与通配符的区别
本质上没有区别,都是用来模糊查询的筛选的作用。
通配符:筛选文件,符号少。
正则表达式:筛选文件内容,符号多。
3-7.正则表分类
# 使用正则表达式的问题是有两大类正则表达式规范、linux不同的应用程序,会使用不同的正则表达式。
# 注意:
正则表达式是通过正则表达式引擎<regular expression engine>实现的。正则表达式引擎是 一套底层软件,负责解释正则表达式模式并使用这些模式进行文本匹配。
分类有:
1.POSIX基础正则表达式<basic regular expression,BRE>引擎 # 基本
2.POSIX扩展正则表达式<extended regular expression,ERE>引擎 # 扩展
posix解释:
POSIX<Portable Operating System Interface>是Unix系统的一个设计标准。
当年最早的Unix,源代码流传出去了,加上早期的Unix不够完善,于是之后出现了好些独立开发的与Unix基本兼容但又不完全兼容的OS,通称Unix-like OS。
# 为什么出现区分:
grep,awk,sed在处理正则时,默认只认识 基础的正则表达式。
比如:如果使用分区()正则表达式,那么就需要对grep添加特殊参数才会理解。
3-7-1.基本正则表达式
BRE对应元字符有:
^ $ . [ ] *
其他符号是普通字符:
; \
3-7-2.扩展正则表达式
ERE在在BRE基础上,增加了:
( ) { } ? + | 等元字符
4.<文件内容>查询命令
注意:
- 以行为单位进行匹配。
1.数据阶段
需要创建一个文件,然后写入测试数据,进行验证。
数据如下:
I am xxx.
I like linux,python!
I like english
My website is https://www.kaixinblog.cn/
Our school site is https://exampleedu.com/
My qq num is 789456789
hahah hello word
2.基本正则符号
| 符号 | 作用 |
|---|---|
| ^ | 匹配以什么开头行 |
| $ | 匹配以什么结尾行 |
| . | 除了换行符以外,都可以进行匹配,也就是匹配一个字符。注意:如果单独使用.就会匹配全部的内容。因为它就是匹配单一个字符,没有任何限制就会将全文匹配。例如:grep '.' 123.log |
| * | 匹配前面一个字符的0个或者N个。注意:如果*是匹配不到任何内容的,因为它是匹配前一个字符的0个或者N个。例如:grep '*' 123.log |
| [] | 匹配中括号内的全部内容。[a-zA-Z] 或者 [0-9]。注意:[1,2,q,h]与[12qh]写法都是相同的意思,只不过通过逗号区分更为明确。 |
1.^举例:
^I # 就是匹配I开头行
^m # 匹配m开头的行
^hahaha # 就是匹配 hahaha 开头的行
2.$举例:
$I # 就是匹配I结尾行
$m # 匹配m结尾行
$hahaha # 就是匹配 hahaha 结尾行
3..举例:匹配一个字符的意思
xx. # 就是匹配 xxx(携带一个任意字符)的内容
98. # 匹配 98(一个任意字符)的内容
4.*举例:匹配前一个字符的0次或者N次。
x* # 就会匹配 以x开头的全部字符,比如:xx xxx xxx..等等
5.[]举例:匹配中括号内的全部内容,与通配符一样。
[123] # 就会匹配1,2,3 这三个字符。
[1-9] # 就会匹配1-9连续的某个字符
[a-z] 或者 [A-Z] # 都是匹配符合条件的连续的某个字符
2-1.组合使用
| 组合 | 含义 |
|---|---|
| .* | 匹配任何字符序列,包括空字符串。 |
| ^.* | 匹配每一行的开头到行末的任何字符序列。 |
| .*$ | 匹配每一行的任何字符序列到行末。 |
| ^.*$ | 匹配每一行从开头到末尾的任何字符序列。 |
| [^] | 在中括号内,^ 作为第一个字符时,表示取反,匹配不在中括号内的任何单个字符。 |
.* 与 ^.* 与 .*$ 与 ^.*$ # 这四种组合形式,都是将全文匹配
[^] # ^在中括号内的作用是取反的意思 对吗
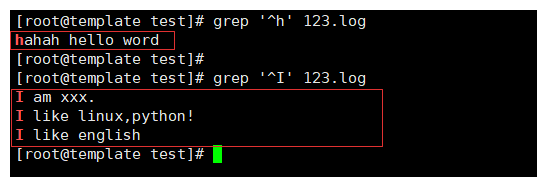
2-2.^测试
^ 匹配开头字符行,必须是这个字符开头。
例如:
grep '^h' 123.log
grep '^I' 123.log
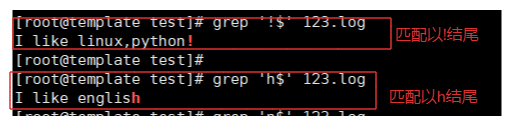
2-3.$测试
$ 匹配结尾字符的行,必须是这个字符结尾。
例如:
grep '!$' 123.log
grep 'h$' 123.log
2-4..测试
. 匹配一个任意字符。
例如:
grep '.' 123.log # 就会匹配到全文的内容,但是无法匹配到换行符号。
grep '7.' 123.log # 就会匹配到7(任意一个字符)。
grep '.h' 123.log # 就会匹配到(任意一个字符)h。

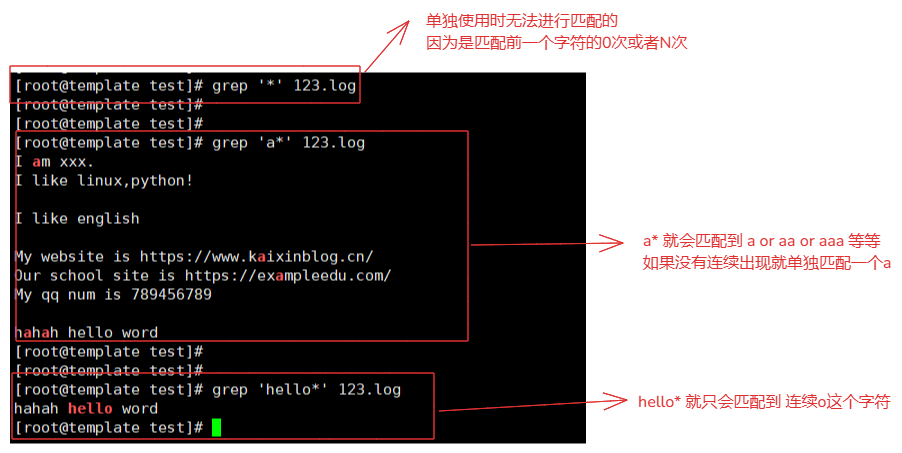
2-5.*测试
* 匹配前一个字符的0次或者N次连续字符。
例如:
grep '*' 123.log # 匹配不到任何内容,因为没有前一个字符。
grep 'a*' 123.log # 就会匹配到 a开始到非a字符结束。
grep 'hello*' 123.log # 匹配到0开始到非0结束字符。
2-6.[]测试
[] 匹配中扩内的字符。
例如:
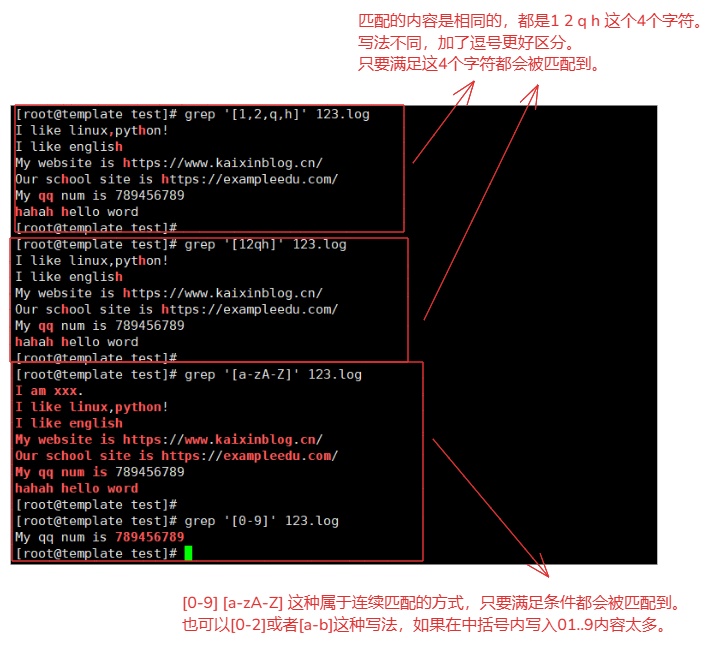
grep '[1,2,q,h]' 123.log # 匹配到 1 2 q h 这四个字符
grep '[12qh]' 123.log # 匹配到 1 2 q h 这四个字符
grep '[a-zA-Z]' 123.log # 匹配 a-z和A-Z符合条件的全部字符
grep '[0-9]' 123.log # 匹配 0-9 符合条件的全部字符
2-2.组合测试
.* 解释
. 匹配一个任意字符,而*是匹配前一个字符的0次或者N次,等同于匹配全文,包含换行符号。
^.* 解释
^ 以后面的一个字符开头匹配一行,那么.*是匹配全部,等同也是匹配全文。
例如:
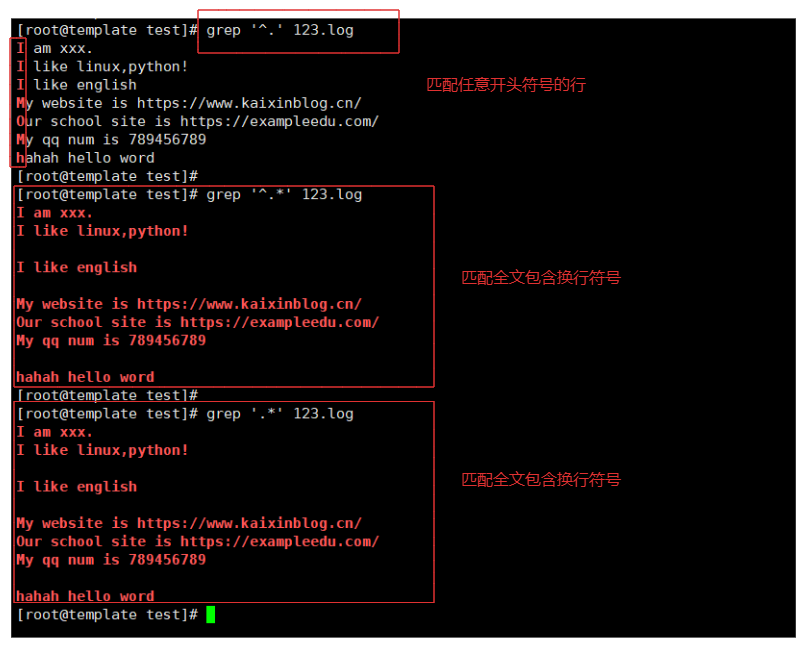
grep '^.' 123.log # 匹配任意开头的行
grep '.*' 123.log # 匹配全文
grep '^.*' 123.log # 匹配全文
2-2.[^]测试
[^] 取反,在这个括号内的内容不匹配,匹配除了括号内的其他的全部内容。
例如:
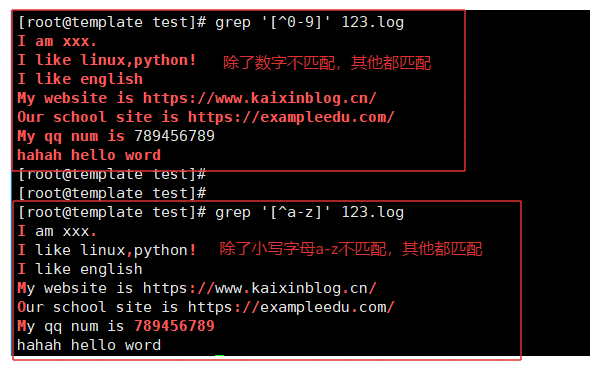
grep '[^0-9]' 123.log # 除了0-9 不匹配,其他全部匹配
grep '[^a-z]' 123.log # 除了a-z 不匹配,其他全部匹配
3.扩展正则符号
注意:
- 扩展正则需要参数支持才可以使用,否则无效。例如:
grep -E
| 符号 | 含义 |
|---|---|
| {n,m} | 匹配单个字符的连续出现的范围N-M次。比如:w{1,3} 就会匹配到最少1个w最多3个w。 |
| {n,} | 匹配单个字符连续出现N-无限大次。比如:w{1,}就会匹配到最少1个w最多n个w。 |
| {n} | 匹配单个字符正好出现的次数。比如:w{3}就会匹配到3个w。 |
| {,m} | 匹配单个字符限制次数。比如:w{,3}最多就会匹配到3个w,也可以匹配到1个或者2个或者0个。 |
| + | 匹配前一个字符1次或者N次。 |
| ? | 匹配前一个字符0次或者1次。 |
| () | 分组符号,分组过滤,被括起来的内容表示一个整体,另外()的内容可以被后面的\n引用,n为数字,表示引用第几个括号的内容。例如:(78)[0-9]+\1那么\1就会引用(98)的这个内容也就是\1=98。 |
3-1.制表符
| 符号 | 含义 |
|---|---|
| \b | 匹配单词边界,如我想从字符串中This is Regex匹配单独的单词 s 正则就要写成 \bis\b。注意:它不是空格,是一个单词的边界,类似于单词与非单词符号之间的位置。 |
| \n | 匹配换行符号。 |
| \r | 匹配回车符号。 |
| \t | 匹配横向制表符,就是tab键。 |
| \s | 匹配一个空格。 |
| \ | 转义符号,可以将通配符转义为原来的意思。例如:\. 或者 \*不在有通配符的意思还是就只代表它自己。 |
3-2.{n,m}测试
{n,m} 匹配前一个字符n-m之间的范围。'n<= 字符 <=m'
# w{1,3} 那么 最少匹配的字符是一个w,最多是三个w。在1-3之间都能匹配到。
例如:
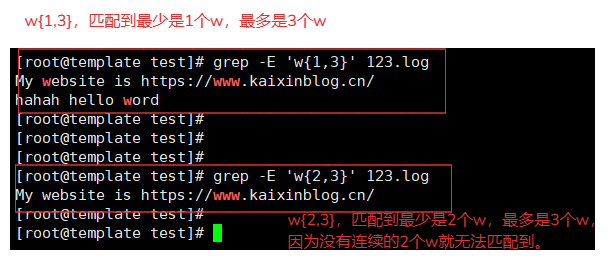
grep -E 'w{1,3}' 123.log # 匹配 w字符,w 或者 ww 或者 www
grep -E 'w{2,3}' 123.log # 匹配 w字符, ww 或者 www
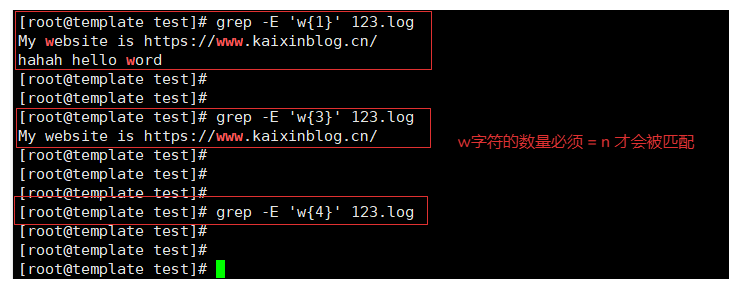
3-3.{n,}测试
{n,} 匹配前一个字符的数量需要 'n<= 字符'
# w{1,} 匹配到的w最少是1个,最多可以无限个w(条件允许的情况下)
例如:
grep -E 'w{1,}' 123.log # 匹配到最少连续的1个w字符
grep -E 'w{3,}' 123.log # 匹配到最少连续的3个w字符
grep -E 'w{4,}' 123.log # 匹配到最少连续的4个w字符
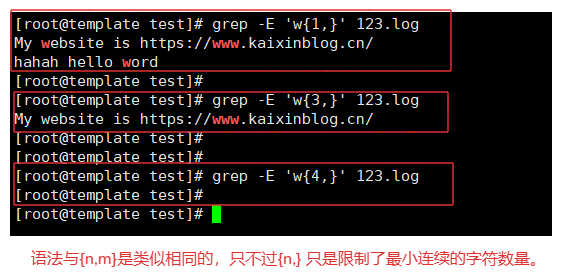
3-4.{,m}测试
{,m} 匹配前一个字符的数量需要 '字符 <=m'
# w{,1} 匹配最多连续字符数量,最大不能超出m
例如:
grep -E 'w{,1}' 123.log # 最多一个w连续字符
grep -E 'w{,3}' 123.log # 最多三个w连续字符
grep -E 'w{,4}' 123.log # 最多四个w连续字符
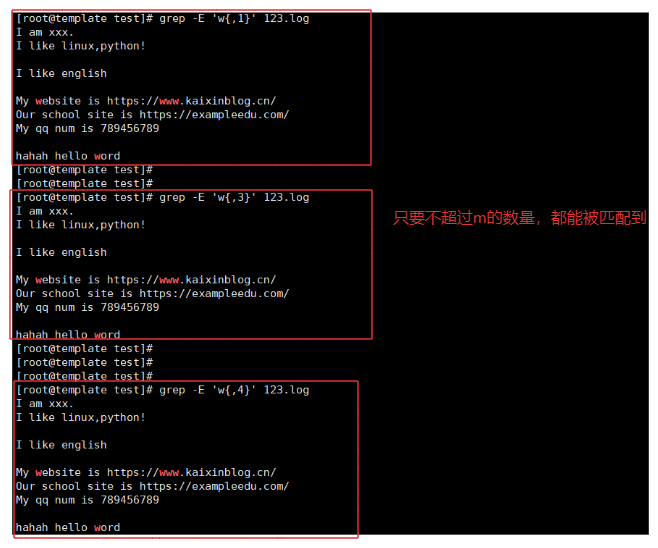
3-5.{n}测试
{n} 匹配前一个字符的数量需要 '字符数量 = n'
# w{1} w这个字符只能出现1个
例如:
grep -E 'w{1}' 123.log # w字符是1个
grep -E 'w{3}' 123.log # w字符是3个
grep -E 'w{4}' 123.log # w字符是4个
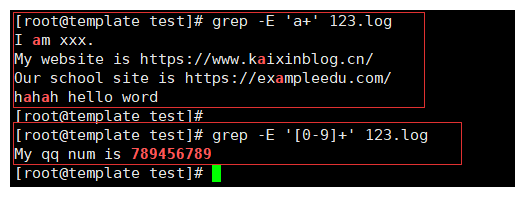
3-6.+测试
+ 匹配前一个字符的1次与N次。也就是匹配最少一个字符,最多可以无限个
# 注意:
与*和不同点在与 *匹配前一个字符的0次与N次。一个是1次一个是0次。
例如:
grep -E 'a+' 123.log # 那么匹配的内容就是 a 或者 aaa...
grep -E '[0-9]+' 123.log # 就会匹配到全部的数字
3-7.?测试
? 匹配前一个字符0次或者1次,最多只能匹配到一次,如果匹不到就是没有。
# 注意:
? 是匹配前一个字符0次或者1次。 0 = 前一个字符数量 = 1
. 匹配前一个字符1次。前一个字符数量 = 1
例如:
grep -E 'i?' 123.log # 匹配前一个字符 i
grep -E 'k?' 123.log # 匹配前一个字符 k
grep -E 'go?d' 123.txt # 就会匹配 god 或者 gd(没有o字符的情况下)
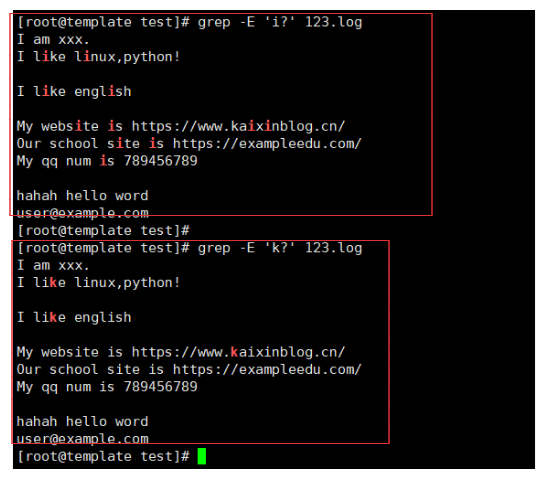
3-8.|测试
| 在正则匹配中也是或者意思,只要满足就会被匹配到。那么满足一个也会匹配到。
例如:
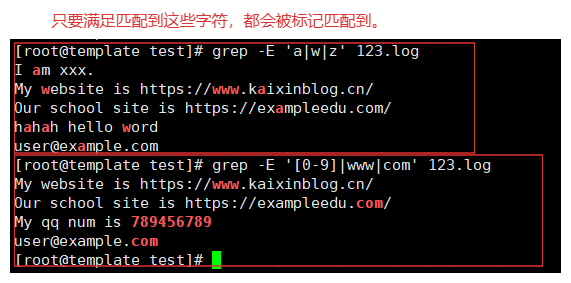
grep -E 'a|w|z' 123.log # 匹配 a 或者 w 或者 z 字符
grep -E '[0-9]|www|com' 123.log # 匹配 [0-9]数字 或者 www 或者 com
grep -E '[0-9]|www|com' 123.log 解释:
1.正则表达式中的 | 表示“或”的关系。grep 会检查这一行是否包含 [0-9]、www 或 com 中的任何一个。
2.只要这一行中包含 [0-9]、www 或 com 中的任何一个,这一行就会被匹配成功。
3.如果这一行中同时包含多个条件(例如 com、www 和 1233),grep 会认为这一行满足匹配条件,因为正则表达式中的“或”操作只要求满足其中一个条件即可。
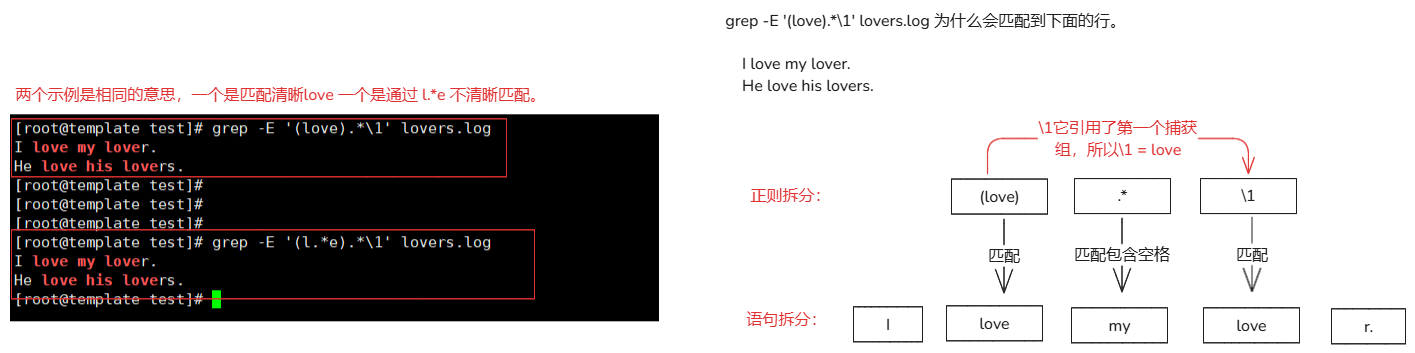
3-9.()测试
() 代表分组的意思,可以使用\number 进行引用分组的的内容(内容是已经匹配到的值)
# 作用:
1.分组最多可以写9个,将一个或者多个字符捆绑在一起,当做一个整体进行处理。
2.小括号功能之一是分组过滤扩起来的内容,括号内的内容表示一个整体。
3.括号()内的内容可以被后面的'\n'正则引用,n代表数字,表示引用第几个括号的内容。
# 引用方式:
\1:表示从左侧起,第一个括号中得模式所匹配到的字符。
\2: 从左侧起,第2个括号中得模式匹配的字符。
# 语法:
() :分组过滤,被括起来的内容表示一个整体,另外()的内容可以被后面的\n引用,n为数字,表示引用第几个括号的内容
\n :引用前面()里的内容,例如(abc)\1 表示匹配abcabc
例如:
grep -E '(love).*\1' lovers.log # 匹配 love (中间是任意字符) love(结尾必须是love)
grep -E '(l.*e).*\1' 123.txt # 匹配 l.*e (中间是任意字符) l.*e
'(love).*\1'解释:
确保,在正则时一行中有两个 love,两个love之间内容任意,只要使用的分组查询,那么它们的概念是相同的(无论引用几次)。
4.grep命令
命令:
grep
作用:
可以通过正则表达式过滤需要的内容。
参数:
-E 使用扩展正则
-i 忽略大小写
-v 反向匹配(除去匹配到的内容显示其他内容,取反的意思)
-n 行号
-o 只显示匹配的内容,不按照行进行显示。当前参数不能与-v参数同时使用,会冲突。
命令使用:
grep <参数> <正则规则> 文件名称
4-1.示例
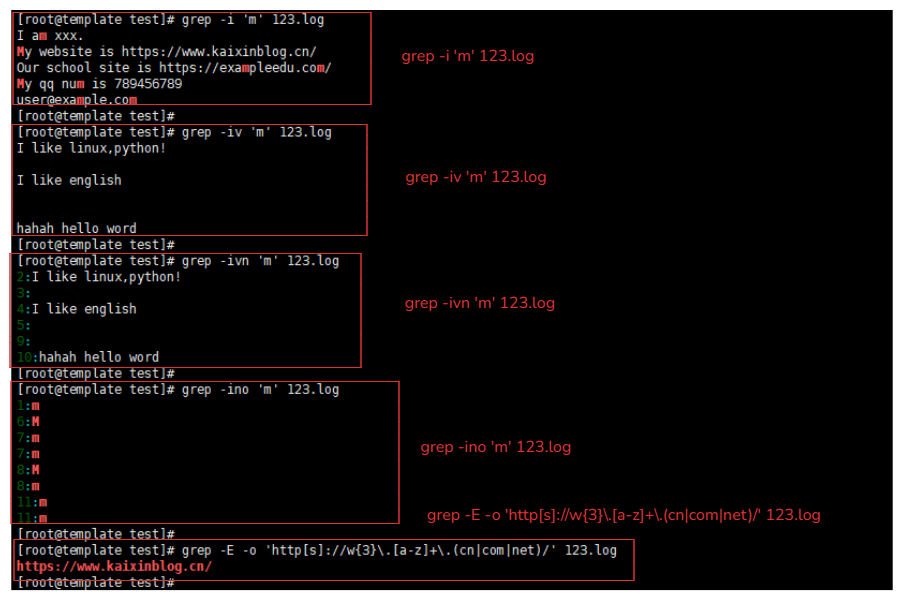
1.使用-i参数
grep -i 'm' 123.log # 就可以匹配到M与m
2.使用-v参数
grep -iv 'm' 123.log # 取反,匹配除了M与m的行的数据
3.使用-n参数
grep -ivn 'm' 123.log # 会显示匹配后数据的行号
4.使用-o参数 #
grep -ino 'm' 123.log # 只会显示匹配到的内容,其他的内容不显示,按照字符显示。
5.使用-E参数
{} + () | 这些符号都属于扩展正则,需要使用 -E 参数让grep命令支持
grep -E -o 'http[s]://w{3}\.[a-z]+\.(cn|com|net)/' 123.log # 匹配一个以 www开头的级域名的网址
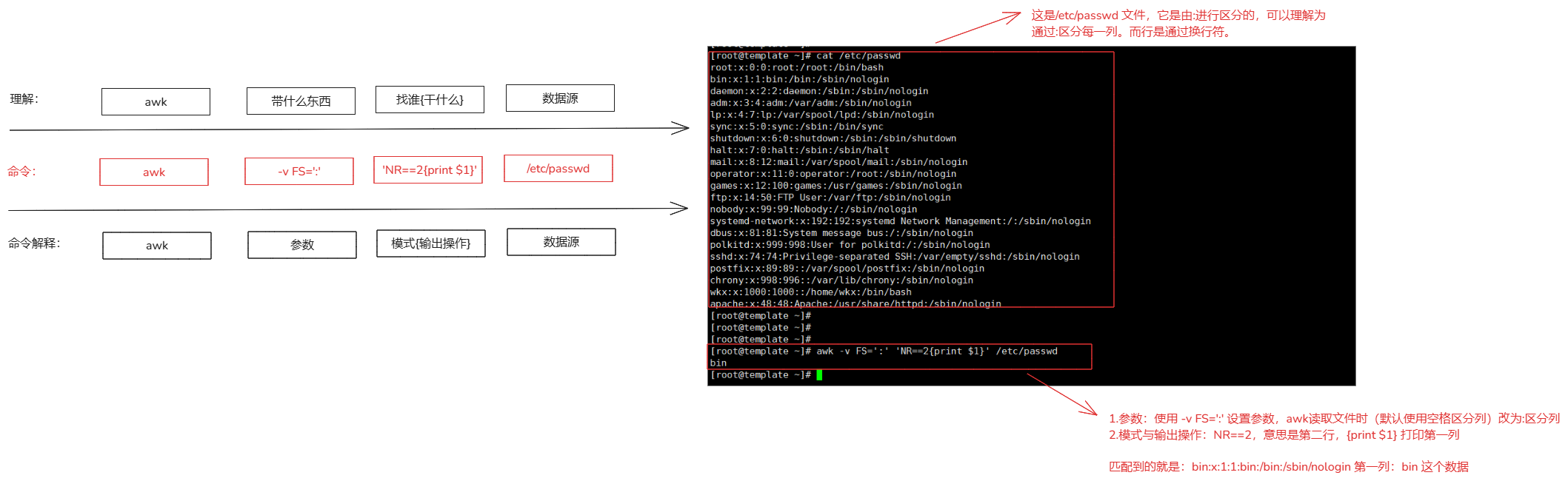
5.awk命令
参考网站:https://www.thegeekstuff.com/2010/01/8-powerful-awk-built-in-variables-fs-ofs-rs-ors-nr-nf-filename-fnr/
命令:
awk
作用:
可以对文件中的行列进行操作,分割数据,输出数据。
参数:
-F # 指定分割符号,默认是空格,例如:-F : 指定的分割符号就是冒号。
-f <指定awk脚本文件> # 通过awk的脚本文件来处理文件
-v # 重新定义awk的变量
-W # 设置字符的分隔符号
# 一般是 -v与-F常用一些。
使用:
awk <参数> '模式(关系表达式/正则表达式){输出}' 文件名称
5-1.awk的内置变量
| awk变量符号 | 作用 |
|---|---|
NR |
NR代表的是文件的行。表示当前记录的编号,即当前处理的是第几行。 |
NF |
NF代表文件的总列数。表示当前记录的字段数。NF 的值会根据当前行的字段分隔符(默认为空格或制表符)自动计算。 |
$N |
代表具体指定的那一列。$1就是第一列,以此类推。$0展示所有列的意思。 |
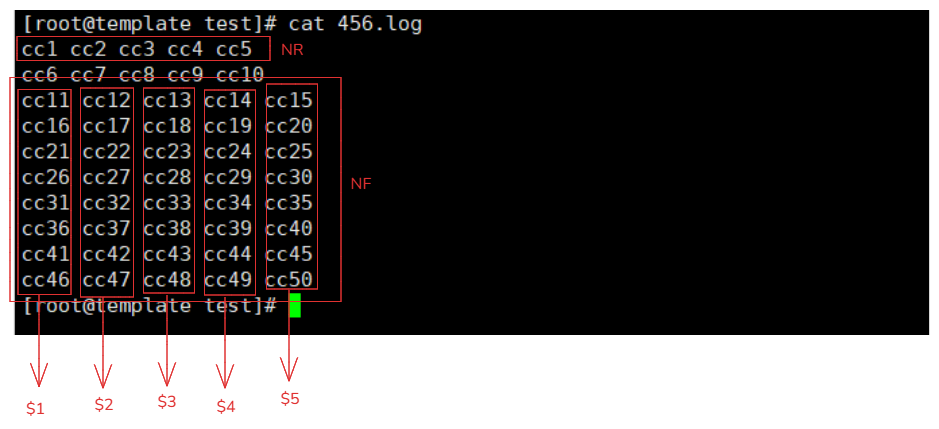
5-1-1.NR/NF/$N理解
数据如下:
[root@template test]# cat 456.log
cc1 cc2 cc3 cc4 cc5
cc6 cc7 cc8 cc9 cc10
cc11 cc12 cc13 cc14 cc15
cc16 cc17 cc18 cc19 cc20
cc21 cc22 cc23 cc24 cc25
cc26 cc27 cc28 cc29 cc30
cc31 cc32 cc33 cc34 cc35
cc36 cc37 cc38 cc39 cc40
cc41 cc42 cc43 cc44 cc45
cc46 cc47 cc48 cc49 cc50
命令:
awk 'NR==1{print $1}' 456.log # 打印的内容就是 cc1
| NR(行数) | NF(列数) | 数据 | $N(列数据表示) |
|---|---|---|---|
| 1行 | 5列 | cc1 cc2 cc3 cc4 cc5 | $1=cc1,$2=cc3 ,$3=cc3,$4=cc4,$5=cc5 |
| 2行 | 5列 | cc6 cc7 cc8 cc9 cc10 | ... |
| 3行 | 5列 | cc11 cc12 cc13 cc14 cc15 | ... |
| 4行 | 5列 | cc16 cc17 cc18 cc19 cc20 | ... |
| 5行 | 5列 | cc21 cc22 cc23 cc24 cc25 | ... |
| 6行 | 5列 | cc26 cc27 cc28 cc29 cc30 | ... |
| 7行 | 5列 | cc31 cc32 cc33 cc34 cc35 | ... |
| 8行 | 5列 | cc36 cc37 cc38 cc39 cc40 | ... |
| 9行 | 5列 | cc41 cc42 cc43 cc44 cc45 | ... |
| 10行 | 5列 | cc46 cc47 cc48 cc49 cc50 | ... |
5-2.awk分割符号输出符号
| 符号 | 意义 |
|---|---|
awk -v RS='符号' |
读取记录分隔符(行),默认是换行符\n,可以通过awk -v RS='新设置'设置新的分隔符。作用:可以改变记录的分隔方式,从而让 awk 以不同的方式读取输入数据(awk读取数据是按照行区分,可以通过这个变量修改读取方式)。 |
awk -v ORS='符号' |
输出记录分隔符(行),默认是换行符\n,可以通过awk -v ORS='新设置'设置新的输出分行符号。作用:awk 在输出每个记录后会自动添加一个换行符(在查询结果后,可以修改变量,使输出的内容以其他的进行分割)。 |
awk -v FS='符号' |
读取字段分隔符(列),默认是空格或者制表符作。通过设置 awk -v FS='符号',可以指定其他字符作为字段分隔符。作用:awk在读取文件中的每行数据时,是按照空格或者制表符作区分每一列的,修改FS区分列(例如:csv文件是用分号分割)。 |
awk -v OFS='符号' |
输出字段分隔符(列)。默认是空格或者制表符作。通过设置 awk -v OFS='符号',可以指定其他字符作为字段分隔符。作用:数据输出后,修改字符与字符之间的间隔。注意:OFS 只在使用 print 语句输出多个字段时生效。 |
5-2-1.RS符号/ORS符号(行)示例
RS:默认'读取'按照换行符(\n)区分'行' # 负责 行的 读取
ORS:默认'输出'按照换行符(\n)区分'行' # 负责 行的 输出显示
RS例如:
123.log文件内容:
123.loghwww.baidu.comhxxxx
awk '{print $0}' 123.log # 默认是按照 \n 换行符号作为分割符号区分。
awk -v RS='h' '{print $0}' 123.log
解释:
将 h 作为记录行的分割符号('h本身不会包含在记录中'),输出每个记录,并在每个记录的末尾自动添加一个换行符 \n。
为什么会自动添加 \n换行符号,因为 ORS 没有修改,默认是换行符号。
ORS例如:
awk -v ORS='@' '{print $0}' 123.log
解释:
将 @ 作为输出分割符号,输出记录时,会在每行记录后面添加一个 @ 所以 @ 正常显示。
因为@不具备换行效果,那么换行就失效了。
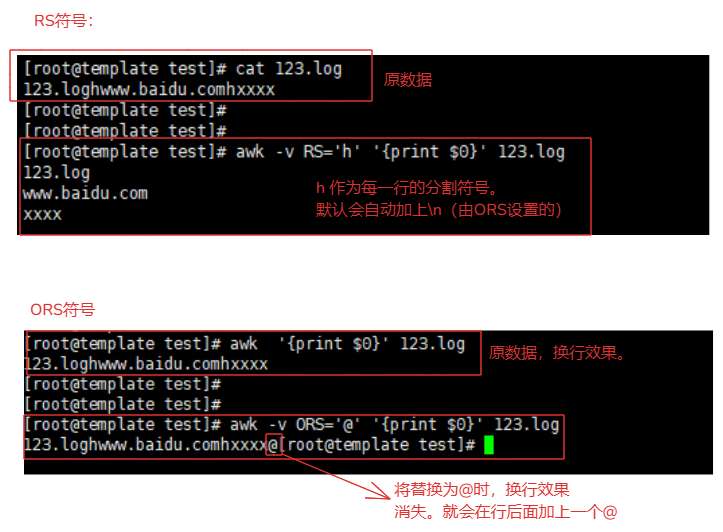
5-2-2.RS符号/ORS符号(行)理解
命令:
awk -v RS='h' -v ORS='@' '{print $0}' 123.log
解释:
RS在awk读取文件时将 \n 替换了 h 作为每一行。
ORS在awk输出时将每一行后面添加 @ 符号作为行的分隔符号。
结果:
[root@template test]# awk -v RS='h' -v ORS='@' '{print $0}' 123.log
123.log@www.baidu.com@xxxx
理解RS与ORS的作用:
命令:
awk -v RS='h' -v ORS='@' 'NR==1{print $0}' 123.log
结果:
123.log@
解释:
因为通过了 RS 替换了原来符号(\n),变为了'h',那么读取时,就会以 'h' 结尾区分为一行。
第1行: 123.log
第2行: www.baidu.com
第3行: xxxx
NR==1 读取第一行数据,那么结果就是 '123.log@'
为什么会又@符号,因为 ORS='@' 在输出时会默认在每一行后面添加一个@符号(原来是\n不会显示的)。

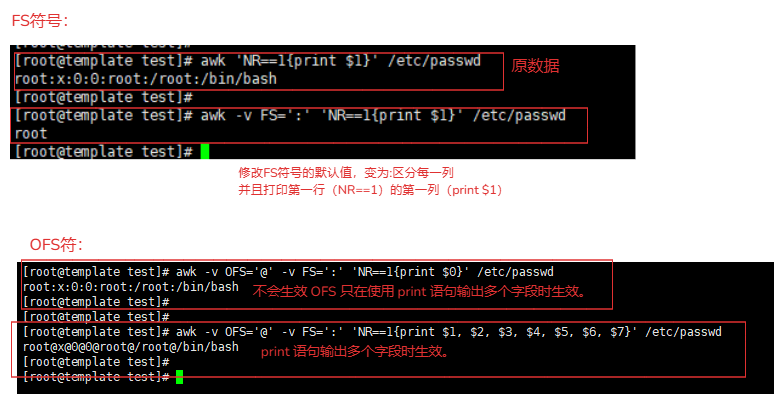
5-2-3.FS符号\OFS符号(列)示例
FS:读取时,区分每一列的符号。(默认是空格),针对不同的文件可以进行设置读取列的数据(例如:cvs是,区分)
OFS:输出显示时,区分每一列的输出符号。(默认是空格)
FS例如:
awk -v FS=':' 'NR==1{print $1}' /etc/passwd
OFS例如:
awk -v OFS='@' -v FS=':' 'NR==1{print $1}' /etc/passwd # 不会生效 OFS 只在使用 print 语句输出多个字段时生效。
awk -v OFS='@' -v FS=':' 'NR==1{print $1, $2, $3, $4, $5, $6, $7}' /etc/passwd
5-3.awk的动作解释
动作:
就是最终输出的内容是什么,其中包含正则表达式,关系表达式,特殊模式等。
动作的组成:
1.模式:正则表达式与关系表达式
正则表达式:用于字符串的模式匹配,检查某一行或某个字段是否包含特定的文本模式。
awk '/正则/{print $0}' 文件
关系表达式:用于数值或字符串的比较,判断它们之间的大小或相等关系。
awk '关系表达式{print $0}' 文件
==:等于
!=:不等于
>:大于
<:小于
>=:大于等于
<=:小于等于
2.输出操作
# 例如:
操作命令:
awk 'NR==2{print $1}' 123.log
动作:
'NR==2{print $1}' 这个部分就是awk的动作。
组成:
NR==2:关系表达式(使用它自带的变量)。
{print $1}:输出操作
5-3-1.关系表达式
| 符号 | 作用 |
|---|---|
| == | 等于 |
| != | 不等于 |
| > | 大于 |
| < | 小于 |
| >= | 大于等于 |
| <= | 小于等于 |
5-3.2.理解
1.关系表达式:
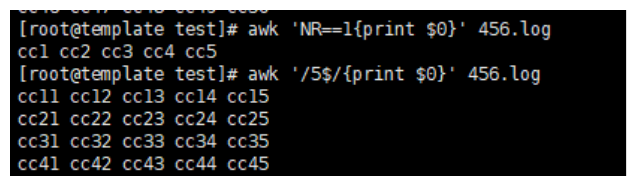
awk 'NR==1{print $0}' 456.log # 关系表达式 NR==1 就是查看当前456.log文件的第一行
[root@template test]# awk 'NR==1{print $0}' 456.log
cc1 cc2 cc3 cc4 cc5
2.正则表达式:
awk '/5$/{print $0}' 456.log # /5$/ 正则表达式,以5结尾的行
[root@template test]# awk '/5$/{print $0}' 456.log
cc11 cc12 cc13 cc14 cc15
cc21 cc22 cc23 cc24 cc25
cc31 cc32 cc33 cc34 cc35
cc41 cc42 cc43 cc44 cc45
5-4.awk的动作特殊模式
| 模式 | 含义 |
|---|---|
| BEGIN | 在awk读取文件之前一般执行的操作。例如:awk 'BEGIN{print "你好"}{print $0}' 123.txt 就会在输出内容的上面打印你好。(可以设置标题) |
| END | 在awk读取文件后一般执行的从操作。例如:awk 'END{print "你好"}{print $0}' 123.txt就会在输出内容的下方打印你好。(可以设置结束语内容) |
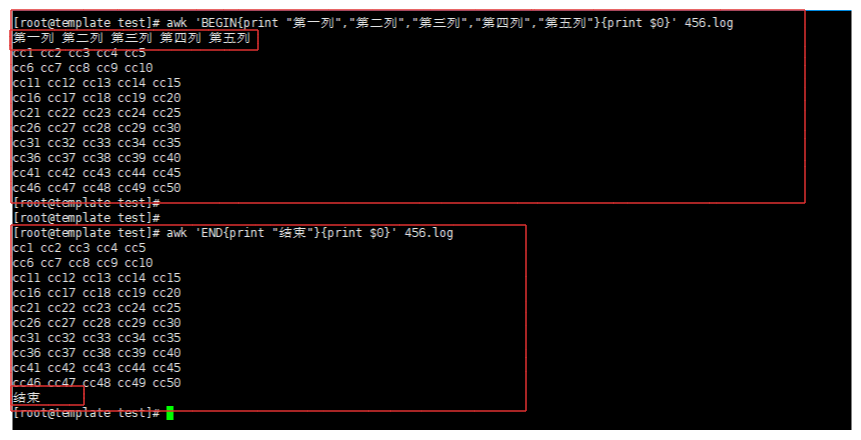
1. BEGIN
awk 'BEGIN{print "第一列","第二列","第三列","第四列","第五列"}{print $0}' 456.log # 在查询数据的最上面先输出的打印内容
2.END
awk 'END{print "结束"}{print $0}' 456.log # 在数据的结尾打印内容
5-5.awk无模式
无模式:
不对查询的数据进行正则模式与关系模式,不使用模式情况下就是全部,无非就是具体到全部数据的某一列。
例如:
awk '{print $0}' 456.log
5-6.awk内置变量总结
参考awk网址:
https://www.thegeekstuff.com/2010/01/8-powerful-awk-built-in-variables-fs-ofs-rs-ors-nr-nf-filename-fnr/
1.FS
读取数据,列分割符号变量。 # 默认空格
2.OFS
输出数据,列分割符号变量。 # 默认空格
3.RS
读取数据,行分割变量。 # 默认换行符号
4.ORS
输出数据,行分割变量。 # 默认换行符号
5.NR
代表当前文件内容行
6.NF
代表当前文件内容列最大值
7.OFMT
数字输出的格式,默认为%.6g。
6.sed命令
命令:
sed
作用:
通过正则替换,修改,查询作用
参数:
-r # 使用扩展正则
-i # 修改文件内容(真是修改)。不使用-i参数的修改是针对内存中的数据,磁盘数据未变化。
-f <sed脚本> # 使用sed脚本修改文件
-e # 支持多条sed命令
-n # 取消默认打印,需要与指令中的p配合使用(在使用sed查询时,会将原文件的内容在输出一遍,-n可以取消输出)
命令使用:
sed <参数> <正则 和 sed内置指令字符> <文件>
6-1.sed内置指令字符
| 字符 | 意义 |
|---|---|
| a | 追加,在指定行后添加一行或多行文本。例如:sed '3a\This is a new line.' file.txt 在文件 file.txt 的第三行后追加一行新文本 "This is a new line." |
| i | 插入,在指定的行前添加一行或多行文本。例如:sed '3i\This is a new line.' file.txt 在文件 file.txt 的第三行前插入一行新文本 "This is a new line." |
| d | 删除指定的行。例如:sed '3d' file.txt 删除文件 file.txt 中的第三行。 |
| I | 忽略大小写。 |
| c | 取代指定的整行。例如:sed 'address c\new line' file.txt 将文件 file.txt 中所有的 "address " 替换为 "new line"。 |
| s | 取代匹配的内容。例如:sed 's/old/new/g' file.txt 将文件 file.txt 中所有的 "old" 替换为 "new"。 |
| p | 打印模式空间的内容,通常 p 会与选项-n 一起使用。 |
| P | 打印模式空间的内容,直到遇到换行符\n结束操作。 |
| n | 读取下一行,但不处理。例如:sed '1,3n' file.txt 读取文件 file.txt 的前三行,但不进行任何处理。 |
| t | 跳转到标签位置。例如:sed '/start/,/end/t' file.txt 从包含 "start" 的行跳转到包含 "end" 的行。 |
| q | 退出 sed。例如:sed '3q' file.txt 只处理文件 file.txt 的前三行,然后退出。 |
| h | 复制模式空间的内容到保持空间。例如:sed '1h;2g' file.txt 将第一行复制到保持空间,然后将保持空间的内容复制回模式空间,覆盖第二行。 |
| g | 复制保持空间的内容到模式空间。例如:sed '1g;2h' file.txt 将保持空间的内容复制到模式空间,覆盖第一行,然后将第二行复制到保持空间。 |
| x | 交换模式空间和保持空间的内容。例如:sed '1x;2x' file.txt 交换模式空间和保持空间的内容。 |
| r <文件> | 从文件中读取内容到模式空间。例如:sed '1r file2.txt' file.txt 在文件 file.txt 的第一行后追加文件 file2.txt 的内容。 |
| w <文件> | 将操作结果写入到文件中。例如:sed '1w file2.txt' file.txt 将文件 file.txt 的第一行写入文件 file2.txt。 |
| y | 转换模式空间中的字符。例如:sed 'y/abc/ABC/' file.txt 将文件 file.txt 中的小写字母 "abc" 转换为大写字母 "ABC"。 |
6-2.sed匹配范围
注意:
- 默认情况下,一行一行处理,也可以进行指定处理数据范围。
| 范围 | 解释 |
|---|---|
| 空地址 | 全文处理 |
| 单地址 | 指定文件某一行 |
/pattern/ |
被模式匹配到的每一行 |
| 范围区间 | 10,20 十到二十行,10,+5第10行向下5行,/pattern1/,/pattern2/ |
| 步长 | 1~2,表示1、3、5、7、9行,2~2两个步长,表示2、4、6、8、10、偶数行 |
6-3.sed处理文本范围语法
注意:
- 增删改查都可以使用。
| sed命令语法 | 作用 |
|---|---|
3 {sed-commands} |
3:代表匹配第三行。具体的操作需要根据指令。 |
3,6 {sed-commands} |
3,6:代表匹配3-6行。具体的操作需要根据指令。 |
| `3,+5 {sed-commands} | 3,+5: 代表从第3行起向后5行,也就是3-8(3+5)行。 具体的操作需要根据指令。 |
1~2 {sed-commands} |
1~2:代表步长为2,操作1,3,5,7..行。 |
3,$ {sed-commands} |
3,,$:3-末尾行操作,包括第3行。 |
/xx1/ {sed-commands} |
对匹配字符xx1的操作。属于正则操作 |
/xx1/,/xx2/ {sed-commands} |
对匹配字符xx1到xx2的行操作。属于正则操作 |
/xx1/,$ {sed-commands} |
对匹配字符xx1到结尾的行操作。属于正则操作 |
/xx1/,+2 {sed-commands} |
/xx1/,+2,操作从 xx1到后两行。属于正则操作 |
6-4.sed增删改查操作
6-4-1.测试数据
I teach linux.
I like play computer game.
My qq is 12345678910.
My website is http://www.xxxx.com
6-4-1.查询
使用的参数:
-n # 就会只打印第一行数据,默认打印就会取消
-e # 可以执行多条 例如:-e 匹配查询命令 -e 匹配查询的命令 ...
-r # 使用扩展正则
使用的指令:
p # 将查询数据打印
; # 可以执行多条
语法:
sed '行/正则 指令' 原文件
例如:
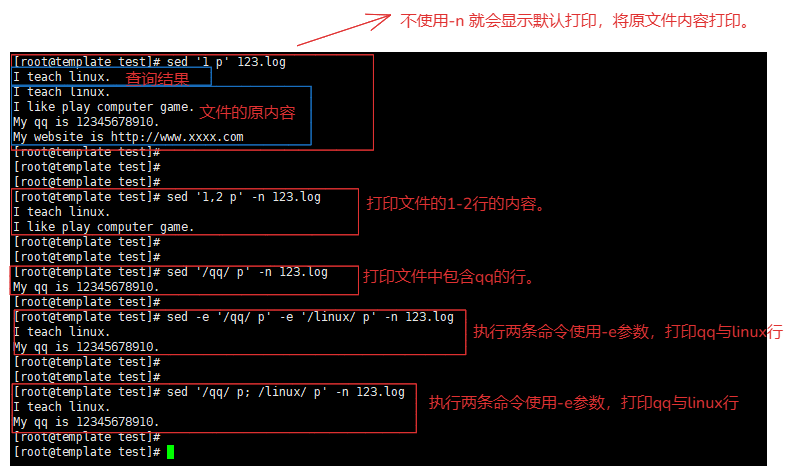
sed '1 p' 123.log # 打印第一行,并且默认打印(原文件内容打印一遍)
sed '1,2 p' -n 123.log # 打印1-2行,取消默认打印
sed '/qq/ p' -n 123.log # 正则,匹配qq行并且打印
sed -r '/[0-9]+{1,11}/ p' -n 123.log # 正则 匹配1-11位qq的行
# 多条打印
sed '/qq/ p; /linux/ p' -n 123.log # 正则,使用分号,执行匹配两条打印
sed -e '/qq/ p' -e '/linux/ p' -n 123.log # 正则,使用 -e 参数
6-4-2.修改
参数:
-r # 使用扩展正则
-i # 不会打印终端,修改原文件,如果不加只是修改内存中的数据,不会影响原文件
指令:
c # 整行替换,将原来的内容替换为新的内容
s # 部分内容替换,将部分内容进行替换。
语法:
sed '行/正则 c 新内容' 原文件
sed '行/正则 s/原内容/新内容/g' 原文件
g的含义:
带g:替换全部
不带g:替换一次
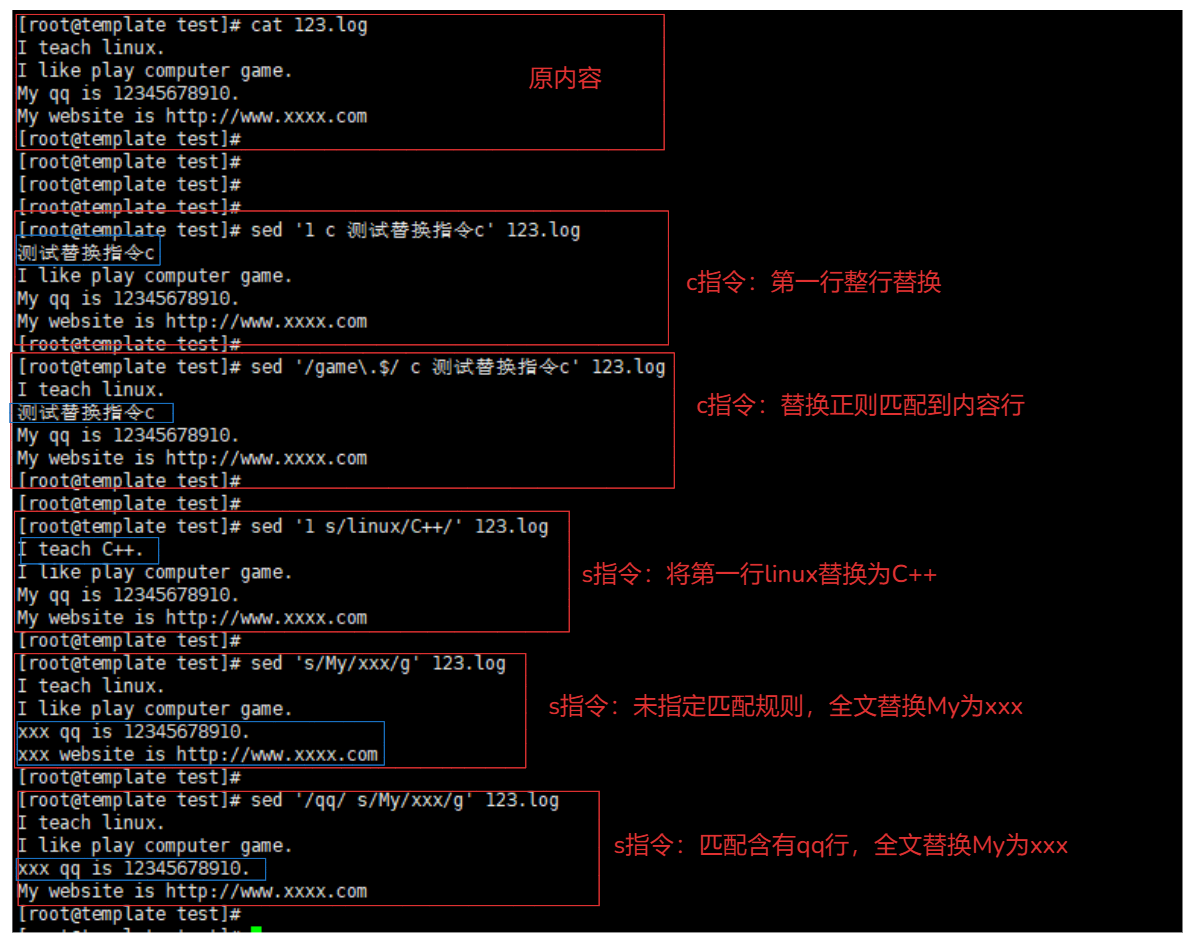
c指令例如:
sed '1 c 测试替换指令c' 123.log # 将第一行替换
sed '/game\.$/ c 测试替换指令c' 123.log # 正则匹配/game\.$/,替换
s指令例如:
sed '1 s/linux/C++/' 123.log # 将第1行的linux替换为C++
sed 's/My/xxx/g' 123.log # 将全文的my替换为xxx
sed '/qq/ s/My/xxx/g' 123.log # 只对含有qq的行进行替换
6-4-3.删除
参数:
-i # 不会打印终端,修改原文件,如果不加只是修改内存中的数据,不会影响原文件
-r # 使用扩展正则
指令:
d
例如:
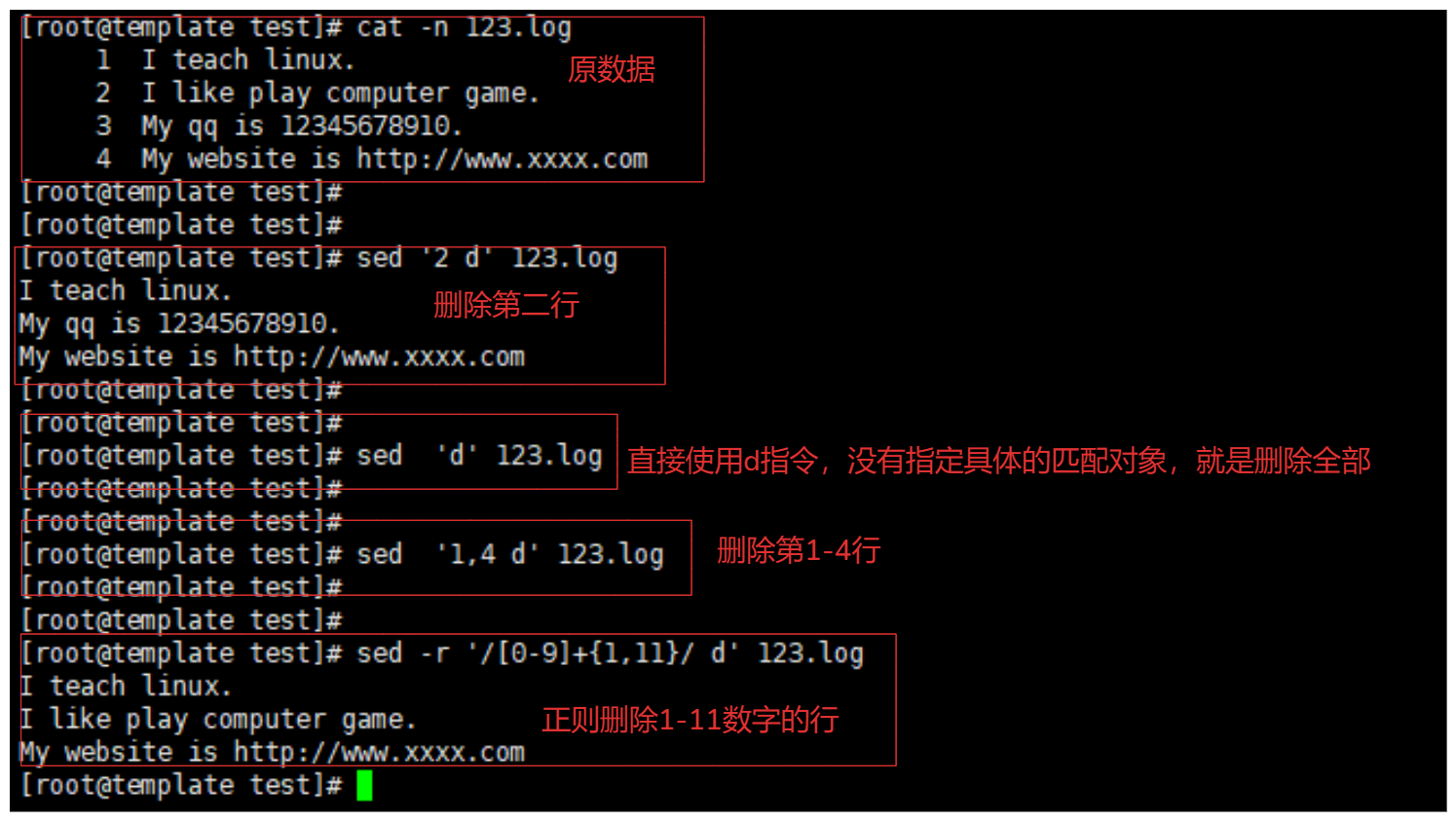
sed '2 d' 123.log # 就会将文本的第二行删除
sed 'd' 123.log # 全部删除
sed '1,4 d' 123.log # 删除1-4行
sed -r '/[0-9]+{1,11}/ d' 123.log # s删除正则匹配1-11qq的行
6-4-4.增加
参数:
-i # 不会打印终端,修改原文件,如果不加只是修改内存中的数据,不会影响原文件
-r # 使用扩展正则
指令:
i 添加 insert
a 追加 append
语法:
sed "行号/正则 sed指令(a/i) 追加数据" 原文件
例如:
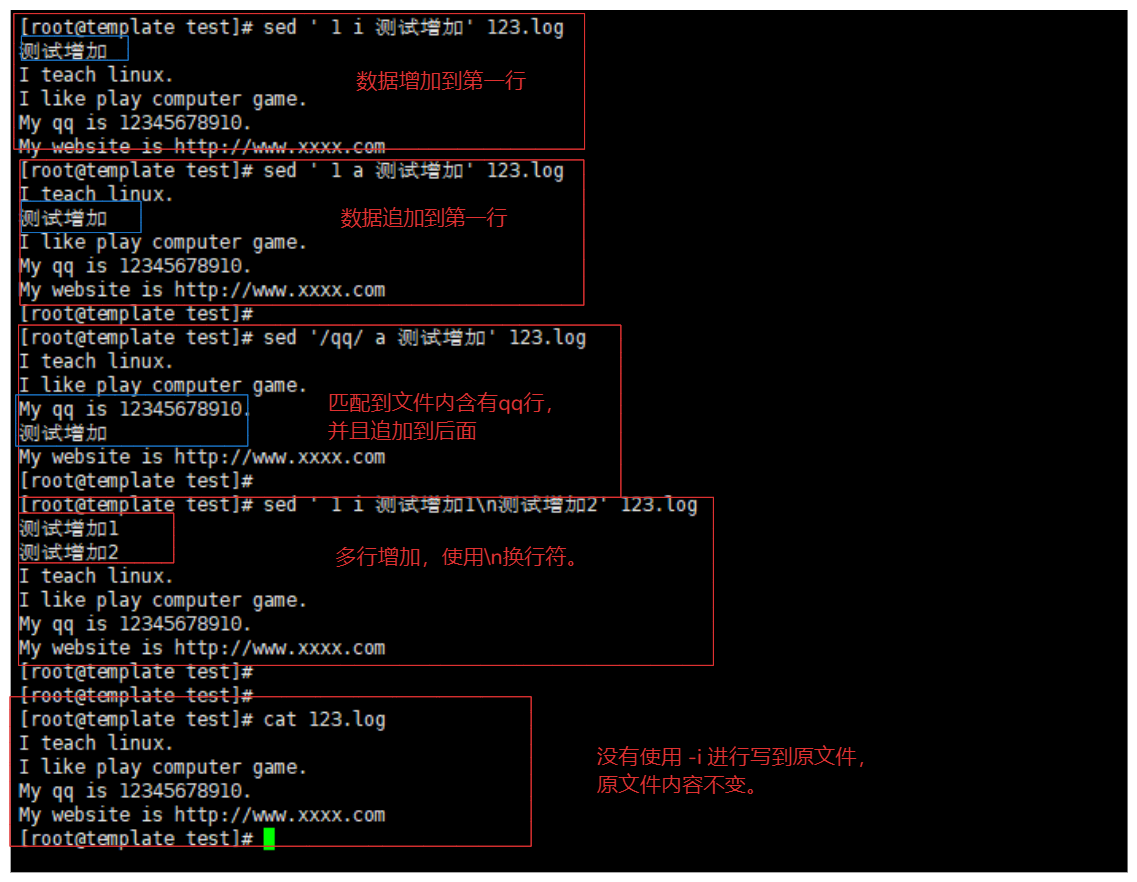
# 单行增加
sed ' 1 i 测试增加' 123.log # 在第一行增加数据,新增到第一行
sed ' 1 a 测试增加' 123.log # 在第一行追加数据,追加到第一行后面
sed '/qq/ a 测试增加' 123.log # 追加到 含有qq行 后面
sed -r '/[0-9]+{1,11}/ a asadasdasd' 123.log # 追加 正则匹配1-11位qq的后面
# 多行增加
sed ' 1 i 测试增加1\n测试增加2' 123.log # 使用换行符号增加多行
7.补充:文件比较
7-1.diff
命令:
diff
作用:
对两个文件进行比较,主要按照行进行比较,比较两个文件的不同
特殊符号:
a:添加 # 比如:3a4 表示在 文件1 的第3行之后,文件2 添加了内容 “新的内容”。
c:修改 # 比如:5c4 表示 文件1 的第5行内容是 “旧内容”,而 文件2 的第4行内容是 “新内容”。
d:删除 # 比如:5d4 表示 文件1 的第5行内容 “被删除的内容” 在 文件2 中被删除。
=:相同 # diff 命令的默认输出中不会显示完全相同的行,但在某些扩展模式下 -c 会显示。
!:不同 # diff 命令的默认输出中不会显示完全相同的行,但在某些扩展模式下 -c 会显示。
+(添加内容)和-(删除内容) # diff 命令的默认输出中不会显示完全相同的行,但在某些扩展模式下 -c 会显示。
参数:
-b 忽略一行当中多个空白区域(a b 与 a b 视为相同)
-B 忽略空白行的区别
-i 忽略大小写的不同
-c 扩展模式,显示上下文
使用方式:
diff [参数] from-file to-file
from-file : 文件名称,作为欲比较文件的文件名
to-file:文件名称,作为目的比较的文件名
例如:
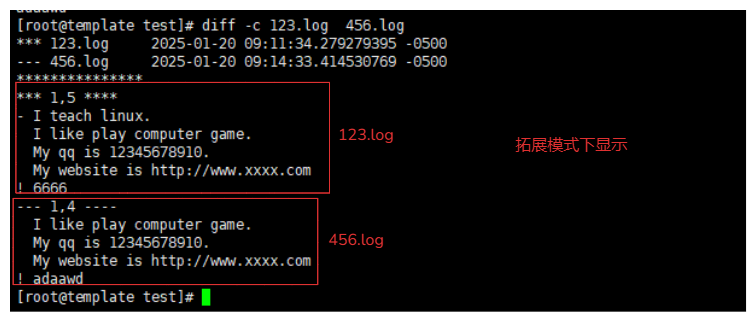
[root@template test]# diff 123.log 456.log
1d0
< I teach linux.
5c4
< 6666
---
> adaawd
# 文件123.log有,但是456.log没有:
1d0的含义:
1:代表 123.log文件的第5行
d:表示删除(delete)操作。
0:表示在文件 456.log 的第 0 行。
说明:文件 123.log 的第 0 行内容在文件 456.log 中被删除了。
< I teach linux.含义:
这是被删除的具体内容。
< 表示这一行内容来自文件 123.log。
说明:文件 123.log 的第5行内容与文件 456.log 的第4行内容不同,需要进行更改。
# 文件456.log有,但是123.log没有
---
> adaawd
>: 表示这一行内容是文件 456.log 中独有的。
adaawd: 是文件 456.log 中的某一行内容,而这一行内容在文件 123.log 中不存在。
7-2.patch
命令:
patch
作用:
patch指令让用户利用设置修补文件的方式,修改,更新原始文件
参数:
-pN: 后面的N代表取消几层目录的意思
-R:代表还原,将新文件还原未原来的文件
使用:
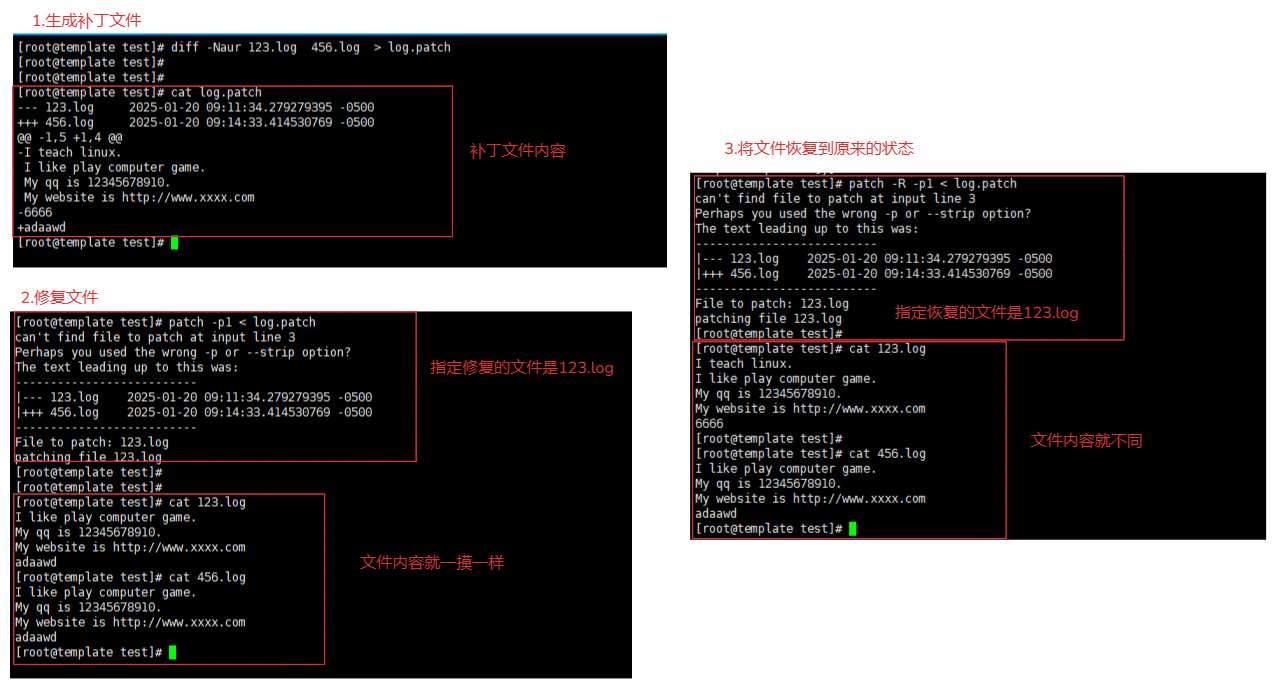
1.制作补丁文件
diff -Naur 文件1 文件2 > 补丁文件.patch
diff -Naur 123.log 456.log > log.patch
内容:
[root@template test]# cat log.patch
--- 123.log 2025-01-20 09:11:34.279279395 -0500
+++ 456.log 2025-01-20 09:14:33.414530769 -0500
@@ -1,5 +1,4 @@ # 新旧文件修改数据界定范围,旧文件:1-5 新文件1-4
-I teach linux. # 删除
I like play computer game.
My qq is 12345678910.
My website is http://www.xxxx.com
-6666 # 删除
+adaawd # 增加
2.使用补丁进行旧文件更新
patch -p1 < 补丁文件
patch -p1 < log.patch
3.文件恢复到原来的内容
patch -R -p1 < 补丁文件
patch -R -p1 < log.patch